General Knowledge Representation And Sharing, with Illustrations In Risk/Emergency Management ________________________________________________________________________________________
Philippe A. Martin [0000-0002-6793-8760] and Tullio J. Tanzi [0000-0001-5534-7712]
A reformatted version of this article has been published as a journal article in the
2023 Special Issue "Disaster Risk Reduction: In Support of the Sendai Framework and Improved Societal Well-Being" of Sustainability.
A part of an earlier version of this article
had previously been published at ITDRR 2020.
Abstract. How should information be organized and shared by agents – people or software – for all and only the pieces of information looked for by agents to be retrieved by these agents? Toward that end, various logic-based knowledge representation (KR) and sharing (KS) techniques, and hence KR bases, have been used. However, most KS researchers focus on what this article defines as “restricted KR and KS”, where information providers and consumers can or have to discuss for solving information ambiguities and other problems. The first part of this article highlights the usefulness of “general KR and KS” and, for supporting hem, provides a panorama of complementary techniques. These techniques collectively answer research questions about how to support Web users in the collaborative building of KR bases. The second part of this article uses the risk/emergency management domain to illustrate how complementary kinds of information can be represented for general KS.
Keywords: Scalable Knowledge&Ontology Representation&Sharing, Risk&Emergency Management.
Table of Contents
1. Introduction 2. Complementary Ways To Support General Knowledge Sharing 2.1. Tools To Import & Export Any Kind Of Knowledge, Even In User Specified Formal Languages 2.2. General-purpose Ontologies Merging Top-level Ones and Lexical Ones 2.3. KB Servers That Support Non-restricting KB Sharing By Web Users 2.4. KB Servers That Support Networked KBs 3. Examples Of Representations For General Knowledge Sharing 3.1. Organization of a Small Terminology About Disaster Risk Reduction 3.2. A General Model To Represent And Organize Search & Rescue Information 3.3. Representations About Automatic Explorations of A Disaster Area 3.4. Representations About How To Create Rovers Adapted To A Terrain 4. Conclusion 5. References
1. Introduction
Risk management and emergency management – and most of their subtasks, e.g. disaster risk reduction and Search & Rescue operations – require access and use to many kinds of information or other resources, e.g. certain kinds of people, search robots, maps, communication tools, detection devices, search procedures and search software. These tasks also depends on many parameters, e.g. the availability of the resources, the nature of the disaster, the terrain and the weather. Ideally, all published information on all these elements would be stored, related and organized on the Web in places and in ways permitting people and software agents to i) retrieve and compare them according to non-predefined sets of criteria, and ii) complement the stored information in ways that maintain its degree of organization and hence retrievability.
As explained below, such an ideal and scalable organization of information implies the building and exploitation of knowledge representation bases: KR bases. In this article, they are simply called KBs and, before going further, now need to be more introduced. Such KBs do not store texts or other data; they store KRs (or simply, “knowledge”), i.e. semantic and logic-based representations of relations between information (the boxes and figures in Section 2.1 and Section 3 include many examples). In this article, the notions referred to by the words “knowledge” (KRs) and “data” are mutually exclusive. “Data” refers to information merely organized by predefined structural relations (i.e. partOf ones) and few semantic relations of very few predefined types (mostly typeOf relations and maybe some subtype relations). In KBs, unlike in relational databases, all the types (i.e. relation types and concept types) and their definitions are user-provided (not predefined by the database designer); most of the knowledge in many KBs are expressed via such definitions; large KBs such as CYC [Lenat & Guha, 1990] [Sharma et al., 2019], Freebase [Tanon et al., 2016] and DBpedia [Lehmann et al., 2015] have hundreds of thousands of subtype relations. Document based technologies and database systems only handle data, although deductive databases are steps towards KBs. A KB is composed of an ontology and, generally, a base of facts. An ontology is i) the set of terms (alias, identifiers) used in the representations stored in the KB, along with ii) representations of term definitions, and hence direct or indirect semantic relations between these terms. Natural language based documents or databases cannot automatically be converted into KBs that are well-organized via generalization and implication relations, if only because these documents and bases most often lack the necessary information to derive such relations (these relations are rarely made explicit by document authors and even human readers often cannot infer such relations with certainty). These relations – and hence, manually or semi-automatically built KBs – are necessary to support i) semantic-based searches, via queries or navigation, and ii) any scalable organization or integration of information. This is why methodologies or architectures for building ontologies or ontology based systems, and their advantages, have already often been discussed in relation to risk management related information. E.g., in February 2022, the digital library of the ISCRAM conferences (“Information Systems for Crisis Response and Management” conferences) included 64 articles with main fields mentioning ontologies, and 46 of these articles recorded “ontology” as a keyword.
There are some top-level ontologies related to disaster management, e.g. the agent oriented ontology of [Inan, Beydoun & Opper, 2015] for better indexing and retrieving “disaster management plans” in document repositories for such plans, SEMA4A [Malizia et al., 2008] (the purpose of which is to help alerting people of imminent disasters), empathi [Gaur et al., 2019] which is more general and integrates some other top-level ontologies, and POLARISCO [Elmhadhbi et al., 2021] which is a suite of ontologies formalizing and relating the terminologies and methods of various “emergency response organizations” (e.g. fire departments, police, and healthcare services) However, as of 2022, there does not appear to be any publicly accessible large content ontology about information related to disaster management, let alone KBs in which people or organizations could relate or aggregate information. For instance, even though [Snaprud et al., 2016] (which is also about disaster related terminologies) mentions past “massive efforts e.g. in European projects such as DISASTER (disaster-fp7.eu), SecInCoRe (www.secincore.eu), EPISECC (www.episecc.eu), or CRISP (www.crispproject.eu)”, only the second and third projects of this list have Web pages which are now accessible, and the results of these projects are not KBs but reports about planned works and advocated architectures or small models (top-level ontologies). Some other large projects such as the Norwegian INSITU (Sharing Incident and Threat Information for Common Situational Understanding) project (2019-2022) [Munkvold et al., 2019] focus more on terminology harmonization as well as tools for the collaborative synthesis of information in classic media (textual documents, databases, maps, ...), hence not information synthesis via KBs. The use of classic media make terminology harmonization useful to support lexical searches (i.e., those proposed by document editors and current Web search engines; these are not semantic searches). However, this harmonization is a complex task that requires committees (hence an hierarchy-based decision-making organization) and it is useful only when its guidelines are followed (which is not easy to do). With KBs, such a terminology harmonization is not necessary: relations of generalization or equivalence between terms within KBs or across KBs can be added in a decentralized and incremental way by each term provider or knowledge provider. Thanks to these relations, people can use the terms they wish and knowledge providers can do so without decreasing knowledge retrievability.
This article distinguishes two meanings for “knowledge sharing” (KS). The one here called “restricted KS” is closer to data(base) sharing: it is about i) easing the exchange of structured information (KRs or structured data) between particular agents (persons, businesses or applications) that can discuss with each other to solve ambiguities or other problems, and ii) representing only information that is needed for particular applications or that can be completely or efficiently exploited by particular agents. The other meaning, here called “general KS”, is about people representing or relating information within or between KBs in ways that maximize the retrievability and exploitation of the information by any person and application. Examples of early landmark works related to general KS were Ontolingua (server, ontologies and vision) [Farquhar et al., 1997] and the still on-going above cited CYC project. These two meanings are unfortunately very rarely distinguished, even indirectly, including by the World Wide Web Consortium (W3C). Regarding KS, the W3C has a “Semantic Web vision” [Shadbolt et al., 2006] of a “Web of Linked data [W3C, 2021]”. As the name may suggest, and as explained in Section 2, the vision and techniques proposed for these Linked Data are mainly focused on restricted KS. Indeed, the W3C had to focus on the basics and convince industries of the interests of KBs over databases. However, after 1997 – the beginning of the popularization of the W3C visions and languages – KS was mainly learned about and operationalized via the W3C documents and languages, and thus almost all research works in KS were implicitly in restricted KS. Among risk/emergency management related research articles that advocate the use of KBs, most rely on the W3C approach or techniques – e.g. [Jain et al., 2021] (ontology-supported rule-based reasoning), [Dobrinkova et al., 2016] (ontology-supported access to particular databases) and [Kontopoulos et al., 2018] (ontology mainly including 38 concept types and 21 subtype relations, about some crisis management procedures). Previous research in risk/emergency management has not addressed general KS in these domains and is insufficient to address the distributed and large number of potentially useful sources of information for such a management. This insufficiency is also one reason for the above cited lack of large publicly accessible content ontologies or KBs related to disaster management.
When applied to knowledge modeling and exploiting processes or techniques as well as rules (or constraints or data structures for them), restricted KS means representing them i) into a KB directly usable by a KR-based software for a particular application, or ii) into a KB from which a particular program can be manually or semi-automatically generated (this is model-based design/programming). With general KS, these process-related resources are represented and organized into an ontology where general logical specifications are incrementally (and cooperatively) specialized by more and more precise or restricted specifications, according to selected paradigms (e.g. logical, purely functional and state-based) and their associated primitives from particular logics and languages. Since these primitives can be defined or declared in an ontology, this one can store and organize representations that are directly translatable in particular formal languages such as programming languages. Thus, if software components are stored in the lower levels of such an ontology, this one may also be used as a scalable library of software components in various languages. Via the systematic use of specialization relations and the explicit representation of any implementation choices, general KS allows the representation of specifications that are language dependent or application dependent while still maximizing knowledge reuse and thus allowing knowledge users (not just knowledge providers) to make such choices.
Knowledge representation and sharing (KR&S) – or, a fortiori, general KS – and the exploitation of its results has various advantages for risk/emergency management. Before an emergency occurs, i.e. in the anticipation phase, KR&S helps finding, organizing and analyzing resources (e.g. information, including techniques), designing tools (e.g. KB-based or not techniques, software and disaster area exploration robots) and testing them (e.g. via simulations). During an emergency, KR&S helps finding and coordinating resources (e.g. information and people). After it, KR&S helps organizing and analyzing data collected during this emergency (e.g. data collected by the robots) and exploit it for validating or refining hypothesis, techniques, simulation data and tools, thus for generating new knowledge.
Section 2 introduces complementary techniques to support general KS – and hence the above described ideal – via four subsections, one for each of the following four complementary topics of such a support: KR language instruments, KR content instruments (reusable ontologies; this is the topics on which most general KS related research focus), inner-KB content organization, inter-KB content organization. By doing so, Section 2 also explains different aspects of the above cited insufficiencies of classic solutions. The originality of Section 2 is in the synthesis or panorama itself, more than in the description depth of the cited or introduced techniques, since the first author has separately published on several of these techniques. However, in Section 2 some new elements are introduced. Furthermore, the panorama shows that it is only together that these complementary techniques support general KS by collectively answering the following research question: how to let Web users collaboratively build KBs that i) are not implicitly “partially redundant or inconsistent”, neither internally nor with each other, ii) are complete with respect to particular criteria and subjects selected by the KB creators, iii) do not restrict what the knowledge providers can enter nor force them to agree on terminology or beliefs, iv) do not lead knowledge providers to duplicate knowledge in various KBs, and v) do not require users to search knowledge in various KBs nor aggregate knowledge from various KBs?
Using various examples, Section 3, the second part of this article, shows the way various kinds of information useful for risk/emergency management can be categorized or represented for general KS purposes. Section 3.1 illustrates the representation and organization of a small terminology, and the advantages of performing such tasks. Section 3.2 gives a general model to represent and organize Search & Rescue information; the illustrated originality is the handling of information objects. Section 3.3 shows KRs about automatic explorations of a disaster area, e.g. by a rover (in this article, “rover” refers to an autonomous small vehicle such as those used for planetary surface exploration); the illustrated originality in Section 3.3 is the representation of procedures. Section 3.4 represents information about how to create rovers adapted to a terrain; the illustrated originality is in showing how all the important information from three different research articles are synthesized, related and organized. The contents of all these KRs (models, procedures, techniques, ...) and their use for designing the intended rovers are themselves validated by the designed prototype rover and its capabilities (Tanzi and Bertolino, 2021).
2. Complementary Ways to Support General Knowledge Sharing
2.1. Tools To Import & Export Any Kind Of Knowledge, Even In User Specified Formal Languages
Knowledge representations (KRs) are logic statements. From a graph-oriented viewpoint, KRs are concept nodes (i.e. concept type instances, quantified or not) connected or connectable by relation nodes (or, more shortly, “relations”: existentially quantified instances of relation types). KRs are expressed in formal languages: KR languages (KRLs). In this article, a KB is a set of objects that are either types (objects that can have instances) or non-type objects. Statements (KRs) are non-type objects. Types are either relation types or concept types. In this article, a “term” is an object identifier that does not solely come from the used KRL, i.e. that is not solely predefined. A term is defined or declared in an ontology. A KB is only an ontology if it has no base of facts, hence if all its statements are definitions. Box 1, Box 2 and Section 3 give KR examples. Box 3 illustrates simple semantic queries on KRs.
|

|
|
Regarding KR languages (KRLs), the W3C proposes i) some ontologies for “KRL models”, i.e. logic and structural models, e.g. RDF for representing very simple logic formulas (existentially quantified conjunctive ones), OWL2 for using the SROIQ description logic and RIF for representing rules of more expressive classic logics, and ii) some notations, i.e. concrete syntax models, for the previous KRL models, e.g. the notations named RDF/XML, RDF/Turtle and RIF/XML. Box 1 illustrates RDF/Turtle and the meaning of “/” in these names. There are other standards for other KR logic models, e.g. KIF-model (the model of the ANSI “Knowledge Interchange Format”) and Common-Logic (CL, the ISO/IEC model for first-order logic), with various notations for them, e.g. Prefixed-KIF, Infix-KIF and XCL (XML for CL). However, as described by the next two paragraphs, the current standard or common KRLs have at least two problems for general KS, hence for general risk/emergency management purposes.
The first problem of these KRLs is their expressiveness restrictions. Although these restrictions ensure that what is represented with these KRLs has particular interesting properties (e.g. efficiency properties), this is at the cost of preventing the representation of some useful information: some KRs cannot be formally written, hence not shared, and this also often leads to the writing of KRs in ad hoc, biased or imprecise ways, hence in incorrect or far less exploitable ways. For general KS, enabling knowledge providers to write expressive KRs has often no downside since, when needed and whichever their expressiveness, KRs can be translated into less expressive ones, often automatically, to fit the need of a particular application, by discarding the kind of information that this application cannot handle or does not require; since such choices are application dependent, the knowledge users should make them, not the knowledge providers. Conversely, KRs designed for particular applications are often unfit (too restricted or biased, ...) for other applications. As mentioned in other words within the introduction, in general KS, knowledge providers do not make application-dependent choices – or only as additional specializations, hence without restricting the possibilities of knowledge users. Since present or future risk/emergency management is not a fixed list of known applications, expressiveness restrictions limit it.
Another important problem of these KRLs is that they are not high-level in the sense that they do not allow “normalized and easy to read or write” representations for many useful notions such as meta-statements, numerical quantifiers and interpretations of relations from collections. Thus, even when representing similar information, different KRs written in different languages or by different users are difficult to translate and match automatically, and hence to search or aggregate. The use of ontology design patterns – e.g. those of [Dodds & Davis, 2012] – by knowledge providers only very partially addresses these issues and is difficult, hence rarely performed. Furthermore, for different domains or applications, different notions and different ways to write them are useful. Creating or visualizing KRs via the current KR editors is even more restricting in terms of what can be expressed and displayed. E.g., graphics take a lot of space and hence do not allow people to simultaneously see and thus visually compare a lot of KRs (this is problematic for KR browsing and understanding).
One answer to these problems was i) FL [Martin, 2009], designed to be a very expressive, concise and configurable textual notation for KRs, and ii) FE [Martin, 2002], a more verbose version of FL which looks like English and hence is more easily read by non-experts. Like FL, FE can use an ontology even for logic related terms such as quantifiers and hence can be a notation any logic, unlike the other logic-based controlled languages, e.g. Attempto Controlled English and Common Logic Controlled English. Box 1 and Box 2 illustrates the expressiveness and high-levelness of FL and FE compared to some classic KRLs. The English statement in Box 2 could have been represented in KIF (since it has a second-order logic notation interpreted into a first-order logic model) but in a less readable and normalizing way.
A complementary and more general answer is the creation of an ontology of not only model components for logics but also of notation components for these models. KRLO (KRL ontology) [Martin & Bénard, 2017] is a core for such an ontology: it allows the definition of KRL languages (and actually most formal languages). Furthermore, it is stored in a cooperatively-built shared KB (details in Section 2.3), that allow Web users to extend KRLO and store the definitions of new KRLs. Software modules that exploit such an ontology are currently being designed. With these modules, KB systems will be able to import and export from, to or between any such specified KR languages, and hence also perform certain kinds of KR translations (furthermore, since the rules for these translations are also specified in the ontology, tool users may select the rules to apply and they may also complement these rules). [Ginsberg, 1991] criticized KIF, and other would-be KRL interoperability standards, for necessarily packaging only a particular set of logic primitives and hence not actually supporting interoperability if the primitives of any logic cannot be defined with respect to each other with that KRL. The use of KRLO and translation procedures based on it is a solution to this problem and can be seen as a way to have the interoperability advantage of standards without their expressiveness and notational restrictions. [Martin & Bénard, 2017] also shows how commons notations such as Turtle or JSON-LD can be used for representing meta-statements and many kinds of quantifiers, albeit in a yet non-standard way. Box 2 illustrates this with Turtle and IKLmE, a model that is part of KRLO and that represents the concept and relation types of IKL [Hayes, 2006], a first-order logic model that is an extension or variant of CL and KIF for interoperability purposes. Some other research projects had or have some similarities with the KRLO project but do not share the goal of supporting one shared ontology for any number of KRLs. Furthermore, KRLO is cooperatively extendable by Web users, as detailed in subsequent subsections, for general KS purposes as well as general translation purposes between KRLs. No other project related to KRL ontologies had the same goal as the KRLO project. The LATIN (Logic Atlas and Integrator) Project (2009-2012) [Codescu et al., 2011] represented translation relations between many particular logics. Ontohub [Codescu et al., 2017] is i) a repository that included some KRL model representations and some translation relations between them, and ii) an inference engine able to integrate ontologies based on different logics. ODM 1.1 [ODM, 2014] is an ontology that relates some elements of some KRL models, mainly RDF, OWL, CL and Topic Maps.
2.2. General-purpose Ontologies Merging Top-level Ones and Lexical Ones
Foundational ontologies or, more generally, top-level ontologies define types that support and guide the representation, organization and checking of KBs. Two examples of well-known general foundational ontologies are DOLCE [Borgo & Masolo, 2009] and BFO [Arp, Smith & Spear, 2015]. The previously cited POLARISCO relies on BFO for better formalizing and relating the terminologies and methods of various emergency response organizations. Strictly speaking, lexical ontologies – e.g. ConceptNet 5.5 [Speer, Chin & Havasi, 2017] – organize and partially define various meanings of words from natural languages and relate these meanings to these words. However, in this article, the expression “lexical ontologies” also refer to “large mappings between general KBs”, e.g. the lexical ontology of UMBEL (now retired but included into KBpedia [Bergman, 2018]) which had more than 35000 types and 65000 formal mappings between categories from (for example) OpenCyc, YAGO, DBpedia, GeoNames and schema.org.
Both kinds (top-level ones and lexical ones) are domain-independent, hence reusable for risk/emergency management. The more types from such ontologies a KB reuse, the easier it is to create and organize its content and the more this content can be retrieved via these types. The more types from such ontologies two KBs share and are based on, the easier the content of these two KBs can be aligned or fully integrated. Below, the word “merge” is used for referring to any of these two processes. Since such ontologies are sets of definitions, not assertions of facts or beliefs, inconsistencies between them are signs of conceptual mistakes, e.g. misinterpretations or over-restrictions. Thus, when not redundant, such ontologies are complementary and, possibly after some corrections, may be merged without leading to inconsistencies.
The Multi-Source Ontology (MSO) [Martin, 2004] is one step towards such a merged ontology. It already merges many top-level ontologies and a lexical ontology derived from WordNet [Martin, 2003]. More will be added, e.g. those from other merges made for large general ontologies such as YAGO and DBpedia. However, unlike for other merges, the ones in the MSO follow the general KS supporting methods described in the next subsection. Here are examples of what this entails.
- The MSO is in a cooperatively-built shared KB where it can be improved and complemented by Web users.
- Modifications in such a KB are, whenever needed, “additive”, as opposed to “destructive” since i) a modification can be made by adding a relation that states how a newly entered KR corrects another KR, ii) KRs are represented as viewpoints, preferences or beliefs from particular knowledge providers, and iii) particular relations must be entered between opposing beliefs for them to be later automatically managed according to the wishes of each user. The next sub-section explains how. The other knowledge sharing approaches are essentially based on helping the creation, handling, retrieval and aggregation of (possibly competing) ontology modules – e.g., see [Vescovo et al., 2021] – and versions (for KBs, hence for ontology modules too) – e.g., see [Kauppinen & Hyvönen, 2004]. Modules and versions are relation sets which may be “partially redundant and inconsistent” with each other With the approach used in the MSO, additions do not require choices between relations and particular modules or versions can still be extracted using semantic queries.
- In accordance with the previous point, when an ontology is merged into the MSO, its content does not need to – and is not – destructively modified to fix conflicts with other ontologies. Thus, no arbitrary choice has to be made and this eases the integration of later versions of these integrated ontologies.
- The top-level of the MSO has been organized via subtype partitions, and hence has advantages similar to those of a decision tree for knowledge retrieval and inference purposes. This organization is kept when new KRs are added into the above cited kind of “additive but consistent” shared KBs.
Besides top-level ontologies and a lexical ontology, the MSO includes KRLO and hence types that are interesting for representing or categorizing procedures or software. As illustrated in Section 3.2, this last point is useful too for risk/emergency management purposes.
2.3. KB Servers That Support Non-restricting KB Sharing By Web Users
A user of a shared KB may want to enter a statement that contradict another user's statement already in the KB. However, for general KS purpose, a KB should not include two statements logically inconsistent with one another, since classic logics – and hence most inference engines – cannot handle KBs that are logically inconsistent (in other words, most KB management systems are not based on a paraconsistent logical system or a similar approach). Similarly, for general KS purpose, avoiding inconsistencies in a shared KB cannot be achieved by having a person or a commitee decide to accept or not each new statement submitted to the KB. Indeed, this process is too slow to be scalable and it is important for general KS to preserve the possibilities for knowledge end-users to make selections themselves according to their particular needs. Similarly, general KS cannot use solutions based on selecting only consensual KRs or only KRs from a largest consistent subset of the KB. Automatically dispatching submitted statements into various KBs for each KB to be internally consistent, e.g. as in the Co4 protocol for building consensual KBs [Euzenat, 1996], is also not scalable: with such a method, the number of required KBs can grow exponentially and these KBs may be mostly redundant with one another.
Solutions start by associating each term (alias, identifier within the KB) and statement
to its source (its author or, if unknown, the source document).
For terms, this is now a standard practice, e.g., the W3C advocates the systematic use of URLs, with
the possible use of abbreviations for the sources.
For statements, making this association is recognizing that the statements which are usually called
facts in KBs are actually beliefs: the associations between them and their sources
become the actual facts. This association may be formalized using meta-statements that
contextualize statements according to who created them or believe in them.
(Unfortunately, the W3C has not yet made recommendations regarding this last point and
OWL does not handle meta-statements).
More generally, in such KBs, the statements provided by users may be seen as either
“beliefs” or “definitions”.
These last ones are always “true, by definition”: the meaning of the term they define
is whatever its definitions specify (thus, if a definition of a term is inconsistent, this term
means “something impossible”).
E.g., assuming that pm identifies a particular user in a KB, then pm
has the right to create the term “pm:Table” (this identifier uses the
term prefixing syntax usable in most KRLs of the W3C) and to define it as a type for flying objects
rather than as a type for some kinds of furniture. Thus, definitions need not
be contextualized like beliefs are.
Thus, to avoid direct inconsistencies between statements from different contributors (knowledge providers), a shared KB may have an editing protocol that leads to the entering of beliefs instead of facts. When a contributor C is about to add a belief that the inference engine detects as being in conflict or partially redundant with another contributor's belief already in the KB, the protocol may ask C to relate the two beliefs for i) representing why this addition is necessary (this is also a way to make C realize that the addition is not necessary or has to be refined), and then ii) let the inference engine exploit such relations between conflicting beliefs for making choices between them when such a choice is required. E.g., a relation between the statements “according to user X, birds fly” and “according to user Y, healthy adult carinate birds can fly” is necessary to state whether the second statement is a correction (by Y) of the first statement, or if the first statement is a correction (by X) of the second statement. Such a relation can then be exploited by each user (according to preferences and application requirements) for manually or automatically selecting which statement should be exploited by an inference engine for the cases when this engine has to choose between the two. For knowledge retrieval purposes, such choices may not have to be made since, when the two statements are potential answers to a query, returning them connected by their relation, may be a good and informative result. One particular rule for an automatic exploitation strategy may be a specification of the following informal rule: “when statements conflict and when their authors are all trustable, select the most corrected statements according to their inter-relations and then, if conflicts remain, generate all maximal sets of non-conflicting statements and give the results of the inferences made with each set”. Different users may refine or complement this rule in many ways.
This approach is further detailed and implemented in the shared KB editing protocol of the WebKB-2 server [Martin, 2011]. It uses the addition of particular relations to the KB not only to be able to manage KB sharing conflicts but also modifications to the KB: modifications are additive, not destructive. E.g, terms or relations which are made obsolete by their creators but still used by other agents are not fully removed but contextualized in a way that indicates i) for terms, who are their new owners, and ii) for relations, who does not believe in them anymore. Regarding the addition of a belief that the inference engine detects as being in conflict or partially redundant with already stored ones, the main principle of this protocol is to ask the author of the belief to connect it to each of these particular other stored ones at least via a relation of a type derived from each of the following ones: “pm:correction”, “pm:logical_implication” (alias, “=>”) and “pm:generalization” (not all logical implications are generalizations). Here, “derived” means either “identical”, “inverse”, “exclusive with”, “subtype of”, “subtype of the inverse”, “subtype of a type exclusive with”. E.g., “pm:non-corrective_specialization_only” is defined as a subtype of the inverse of “pm:generalization” as well as an exclusion to both “pm:correction” and “=>”. Thus, all the potentially redundant or conflicting statements are (directly or transitively) connected via these relations. This organization has many advantages for inferences, checks and quality evaluations of the KB, e.g. statements can be searched for via their exclusion to some other ones. Even more importantly for general KS, this organization supports automatic choices between conflicting statements via rules such as the one given in the previous paragraph.
Since knowledge providers can specify the above cited relations even when an inference engine is not able to detect potential conflicts or implicit redundancies, knowledge providers can also specify such relations between informal statements within a KB or a semantic wiki. Thus, the approach can also be used to organize the content of a semantic wiki and thus avoid or solve edit wars in it. To conclude, the approach described in the previous paragraph works with any kind of knowledge, does not arbitrarily constrain what people can represent and store (within the constraints of any automatically enforceable topic or KB scope), and keeps the KB organized, at least insofar as people or the used inference engine can detect inconsistencies or redundancies. In a fully formal KB, many implications have to be provided by the knowledge providers (e.g., these implications may be rules these persons believe to be true) but the generalization relations between statements can be automatically generated, e.g. for inference efficiency purposes. To get or keep a partially informal shared KB organized, and hence better exploit it for inferences and cooperation purposes, the more this KB uses some informal terms in its statements, the more it is useful to also ask the knowledge providers to specify generalization relations between statements (in addition to the implication relations, as shown in the previous paragraph).
2.4. KB Servers That Support Networked KBs
As hinted in the first paragraph of the introduction, the amount of information that can be valuable for a domain such as risk/emergency management is huge (and can be used for many other purposes). That amount of information cannot be stored into a single individual KB (alias, physical KB). An individual KB is a KB having one associated KB server that stores this KB and manages query/update accesses to it – one server or, for security purposes, a set of equivalent ones. As opposed to such a KB, a networked KB (alias, virtual KB) is composed of a network of individual KBs where the KB servers exchange information or forward queries among themselves.
The W3C has not made recommendations about networked KBs, it solely advised the authors of KBs to relate the terms of their KBs to those of some other KBs. This advice tries to address the problems coming from the fact that most KBs are developed independently from one another, and hence are just structured data for one another since their ontologies are not related or poorly related. However, this strategy for partially-independent development of KBs only very partially solves the above referred problems: the more knowledge is added to such KBs, i) the more implicit redundancies and inconsistencies they have between them, ii) the harder it is then to align or integrate them, and iii) each user that wants to reuse such KBs has to (re-)do such an integration work. Although there are numerous approaches for partially automatizing such a work or aspects of it, as for instance recently summarized by [Neutel & Boer, 2021], their success rates are necessarily limited: correctly and fully integrating two (partially-)independently ontologies requires understanding the meaning of each object in these ontology and hence, most often, finding information that is not represented in them.
Thus, for reasons similar to those given in the previous (sub-)sections, for a networked KB to be scalable and interesting for general KS purposes, i) its total content, i.e. the sum of its component KBs, should be as organized as if it was stored into one individual shared KB with the properties described in the previous subsection, ii) neither the repartition of the KRs among the KBs, nor the process of adding an individual KB to a networked KB, should depend on a central authority (automated or not), and iii) no user of the networked KB should have to know which component individual KB(s) to query or add to. Hence, ideally, for general KS on the Web, i) there would exist at least one networked KB organizing all KRs on the Web, and ii) additions or queries to one KB server would be automatically forwarded to the relevant KB servers.
These constraints are not satisfied by networked KBs based on distributed or federated database systems. Indeed, in these systems, the protocols that distribute or exchange information and forward queries exploit the fact that each individual KB or database has a fixed database schema or ontology, i.e. one that is not modified by its end-users (e.g. data providers). On the other hand, in general KS, the ontologies of the individual KBs are often modified by the KB contributors. Many networked KB architectures exploit such database systems, including the architectures advocated in risk/emergency management related articles, e.g. those of [Dobrinkova et al., 2016].
Similarly, these constraints are not satisfied by networked KBs based on peer-to-peer (P2P) protocols or multi-agent system (MAS) protocols. Indeed, for exploiting the KRs within these KB – for the distribution, indexation or exchange of knowledge – these protocols also have to rely on some fixed and/or centralized ontologies (and/or use knowledge similarity measures or automatic ontology integration techniques when these approach are sufficient for the intended task or domains; these measures or techniques may be provided by the individual servers, peers or agents). These fixed ontologies may be stored within the individual servers, software agents or peers – or sometimes even the P2P routing table, as described by [Loser et al., 2004]. They may also be external to them, with more structured networks (e.g. the use of super peers) or centralized solutions, for instance as described by [Islam et al., 2010], [Gharzouli & Derdour, 2014] and [Toure et al., 2021].
To satisfy the above cited constraints, the solution proposed by [Martin, 2009] is based on the notions of “(individual KB) scope” and “nexus for a scope”. The rest of this section presents the underlying ideas of a recently extended version of this solution. An intensional scope is a specification (via a KR) of the kinds of objects (terms and KRs) that the server handling an individual KB is committed to accept from Web users. This scope is chosen by the owner(s) of this shared individual KB. An intensional core scope is the part of an intensional scope specifying the kinds of objects that a server is committed to accept even if, for each of these kinds of objects, another intensional core scope on the Web also includes this kind of objects (i.e., if at least another server has made the same storage commitment for this kind of objects). An extensional scope is a structured textual Web document that lists each formal term (of the ontology of the individual KB) that uses a normalized expression of the form “<formal-term-main-identifier>__scope <URL_of_the_KB>”. Since extensional scopes are Web documents, this format permits KB servers to exploit Google-like search engines for knowing which KBs store a particular term. A (scope) nexus is a KB server that has publicly published its intensional and extensional scopes on the Web, and has also specified within its non-core intensional scope that it is committed to accept storing the following kinds of terms and KRs whenever they do not fall in the scope of another existing nexus: i) the subtypes, supertypes, types, instances of each type covered by the selected intensional scope, and ii) the direct relations from each of these last objects (that are stored in this KB only as long as no other nexus stores them). (The WebKB-2 server that hosts the MSO is a nexus that has at least the MSO as intensional scope. Thus, this server can be used by any networked KB as one possible nexus for non-domain specific terms and KRs.) Then, “an individual KB (server) joining a networked KB” simply means that the KB server is being committed not only to be a nexus for its intensional scope but also to perform the following tasks whenever a command (query or update) is submitted to the KB server:
- The first task is, insofar as the intensional scope allows it, to handle this command internally via the KB sharing protocol of WebKB-2 or another protocol with similar or better properties. Because of the intensional scope, the query or update might be only partly stored or handled. For efficiency reasons, when an object is in the core intensional scope but is related to other objects that are not in it, each of these other objects should be associated to the URL of another KB server that has this object within its core intensional scope.
- The second task is to forward this command to the KB servers which, given their scopes, may handle it, at least partly. These servers are retrieved via their published extensional scope.
Thus, via this propagation, each command is forwarded to all nexus that can handle it, and no KB server has to store all the terms of all the KBs, even for interpreting the published scopes of other nexus. To counterbalance the fact that some KR forwardings may not be correctly performed or may be lost due to network errors, i.e., to counterbalance the fact that this “push-based strategy” may not always work, each KB server may also search other nexus having scopes overlapping its own scopes and then import some KRs from these nexus: this is the complementary “pull-based strategy”. KB servers with overlapping scopes may have overlapping content but this redundancy is not implicit and hence, as explained in the previous subsection, not harmful for general KS purposes.
To sum up, Section 2.4 showed how some inter-KB organization(s) can replicate an inner-KB organization that has advantages and supports described in Section 2.3 and Section 2.2, which themselves are made possible via the language related techniques introduced in Section 2.1. Section 3 illustrates some applications of some ideas from Section 2.1 and Section 2.2 for some knowledge useful in risk/emergency management.
3. Examples Of Representations For General Knowledge Sharing
In this section, for concision and clarity purposes, the FL notation
[Martin, 2009] is used, not a W3C KRL notation.
Thus, for identifiers, the namespace end delimiter is “#” (as in pm#Table)
instead of “:” in W3C KRL notations (as in pm:Table); indeed,
in FL “:” is the end delimiter for relation nodes, as in most frame-based KRLs.
3.1. Organization of a Small Terminology About Disaster Risk Reduction
In 2017, the UNDRR (United Nations office for Disaster Risk Reduction) has defined a “terminology about disaster risk reduction [UNDRR, 2017]” which in the present article is referred to as “UndrrT”.
[Martin, 2020] represented UndrrT in FL, increased its organization and stored it in a Web document. As illustrated in Fig. 1 and Box 4, this document organizes UndrrT into a subtype hierarchy using i) whenever possible, subtype partitions or other subtype exclusion sets, ii) the top-level concept types of the MSO, and iii) a few additional types when really needed for categorization purposes. This Web document is also structured informally via sections and subsections, according to some of the MSO types, in a systematic and non-subjective way. All these points make the terms and relations between the terms in UndrrT much easier to understand and retrieve (by following relations between them or via queries) than in the original UNDRR document since its terms are only informally defined and only listed in alphabetic order.
The first two points of the three points listed in the previous paragraph also support
some automatic checking of the way
the UndrrT terms are specialized or used in KRs, in order to
i) detect whether some of these terms have been partially misinterpreted, and
ii) guide knowledge representation.
E.g., instances of undrrT#Disaster_risk_management are defined to be usable as
sources in relations the signature of which has
undrrT#Disaster_risk_management or one of its supertypes as the first parameter.
Since one of these supertypes is pm#Process,
and since the MSO provides many types of relations from pm#Process (e.g.
pm#object, pm#parameter, pm#duration, pm#agent,
pm#experiencer, etc.), such relations are usable from instances of
undrrT#Disaster_risk_management.
Representing UndrrT using the MSO also highlighted important ambiguities that the sometimes
lengthy informal definitions associated with the terms did not help resolve.
E.g., are the types undrr#Exposure, undrr#Vulnerability and
undrr#Resilience meant to be specializations of what
pm#Characteristic_or_dimension_or_measure means or of what
pm#State (which refers to non-evolving kinds of situations) means?
In [Martin, 2020], we selected the first interpretation
since then representing information using these types is easier than with the second interpretation.
However, other users of UndrrT may
have interpreted and used these UndrrT terms as if they represented states.
The two interpretations are exclusive: they cannot be reconciled.
Thus, general KS is clearly reduced by such ambiguities.
|

|
3.2. A General Model To Represent And Organize Search&Rescue Information
Unlike other general ontologies, the MSO provides a type for “description instruments or results” (alias, “information objects”, e.g. languages, stories, procedures, object-oriented classes, maps) and many subtypes for it, most of which are from KRLO. They are useful for representing and categorizing many information objects that can be used in risk/emergency management. Box 5 shows that the Search & Rescue domain requires many of these subtypes for categorizing information, e.g. for maps and procedures exploiting or enriching maps.
|
Box 5 show the distinction between concrete and abstract information objects.
It leads to distinguishing concrete maps from abstract ones.
A concrete map, e.g. one displayed on paper or on a screen,
is a 2D or 3D graphic representation of physical objects.
An abstract map is a structural representation of a concrete map.
In Search & Rescue, search functions need to exploit characteristics of objects in a map,
and search agents that do terrain mapping or discover victims or possible indices of victims
need to add objects to the map. Thus, structurally, an abstract map
should not be a set of pixel representations but should permit the storage, update and
querying of i) object representations that are, were or may be part of the map, and
hence also ii) at least their partOf relations, types and attributes.
This does not mean that such maps should be directly stored in a KB, using relations.
Indeed, this would not only be an inefficient way to store and handle spatial coordinates or
relationships of objects in maps, this would also make them difficult to exploit via
classic programs, those only based on classic structures such as object-oriented classes.
Hence, such maps should remain abstract data structures but
should be represented or implemented in much richer structures than those in
binary formats for the 2D/3D abstract maps: raster image formats (pixel based formats) and
vector formats (graphics/geometry+texture based format, e.g.
SVG and
OBJ).
More information can be described via the
Geography Markup Language (GML) which uses a very restricted kind of KRL
– GML is used by the Web Feature Service (WFS), an interface model created by
an interface model created by the
Open Geospatial Consortium (OGC) to support requests for
geographical features across the web using platform-independent calls.
However, GML is not for storage purposes.
In any case, ideally, for each physical object, these maps would store a reference
(e.g., an identifier or a pointer) to an information object representing this object
in a KB, and this KB would support semantic queries about such objects.
For classic queries – the structural and lexical ones – data structures
are sufficient.
For conceptual queries or navigation, semantic relations stored in data structures can be
dynamically extracted and imported into the KB, when needed and based on the kinds of
needed relations.
To that end, FL and WebKB-2 have been extended to enable the reference to
– and, when needed, automatic call of –
“relation generators” (as we call them); they are represented in ways roughly similar
to normal relations or to function calls.
Box 6 contains a generic representation of such abstract maps useful for Search & Rescue: it is a list of semantic relations between such maps and some other kinds of objects. This representation can be viewed as a generalization or “minimal general specification” of abstract data structures for such maps. More comprehensively, Box 6 is a top-level ontology – hence a minimal general specification, model or listing – of functions and of the most interesting kinds of objects that they could exploit, which are useful for Search & Rescue. Before explaining the notation used in Box 6, it should be that the goal of this box is to represent three important and combinable functions:
- one to retrieve objects (generally, people) within a map, given some of their types or ranges for their attributes, e.g. a range for the expected health or social value of actual/potential victims at certain places in a map (since, for example, an often used strategy is to first try to save the healthier and most socially valuable victims),
- one to compute values (possibly with some associated certitude coefficients) for particular attributes of particular objects in a map, given other parameters such as the environmental context (weather, ...) and when the rescue begins and/or when the objects can or could be retrieved (since, for example, some victims may be difficult to save by the time they are found),
- one to compute the best paths (possibly given strategic rules and/or a search algorithm) from a starting place to others (thus, possibly an area) for finding objects of given attributes, with additional attributes to maximize (e.g. the safety of the rescuing agents and of the victims) and others to minimize (e.g. the power consumption of a rover used for exploring a disaster area in search of victims).
In object-oriented (OO) programming, functions are often associated with some of the objects they exploit by being represented as methods of the class of these objects. This kind of associations, which in KRLO is represented via a relation type of name “method”, helps organizing and normalizing the code, and is now commonly supported by most common programming languages. Box 6 uses “method” relations since it is intended to be a minimal general specification of important primitive functions for Search & Rescue. The next three points comment this use.
- Box 6 uses “_{” and “}” to delimit the set of relations that define a type. These delimiters are not necessary in FL but are used here to make the specifications look more like those in many OO-like notations, UML textual notations and frame-based notations, and hence more intuitive to people that are used to those notations. (E.g., the separators “,” and “;” are used in Box 6 where “ ” and “,” in classic FL.) However, despite this intended syntactic similarity with OO classes, genuine KRs are represented in Box 6, not just OO classes; indeed, genuine relations are used, not class attributes (unlike relations, attributes are local to classes and are not first-order entities).
- One of the advantages of associating functions to information structures via “method” relations is that this supports the use of an intuitive OO-like naming scheme for the functions: in Box 6, see the “__” within method names. These names follow the naming scheme “className__coreMethodName”. With a genuine OO programming language, the part before the “__” is omitted because when a method is called on a particular object, this one (and hence, indirectly, its class) is specified just before the method, e.g., as in “objectName.coreMethodName“ when the classic dot notation is used. With a KRL, methods are not local to an object or class – like relations from a object are not local to this object in the way its attributes are – and hence the name of the class has to be specified with the method name, e.g. via the above cited normalizing and compact OO-like naming scheme.
- Another advantage of such associations is that, combined with the use of UML cardinalities (e.g. “1..3”, “0..*”) in the parameters of these functions or methods, they provide rather easy-to-use ways to generalize – or abstract away – implementation particularities, at least compared to programming languages. Indeed, with a programming language, class definitions are only tree structures and functions do not use cardinalities nor have successive default parameters; this generally forces a user of such languages to i) cut a graph of relations (i.e., the model in the user's mind) into pieces when representing it via such structures, ii) make the relations implicit, iii) choose a rather arbitrary embedding order between the graph elements, and iv) implement various similar versions of a same function, based on particular aggregations of datatypes for the parameters.
|
3.3. Representations About Automatic Explorations of A Disaster Area
This subsection shows how the task of systematically exploring a disaster area (e.g. by a rover, to search for victims) can be represented at a high-level (as well as lower ones). The reuse of the functions from the previous subsection is not shown. The focus here is to illustrate how (the elements of) tasks or procedures can be variously represented and organized, via KRs.
Box 7 shows an example systematic search procedure written in a procedural notation. Procedures can often be automatically converted into pure functions (this is the case of the one in Box 7), hence in a declarative way. Pure functions can be represented in a KRL that handles functions, e.g. KIF and FL. With FL, or with KRLO and any KRL, procedures can also be directly represented in a state-based form. Once in a KB, procedures or functions can be organized via generalization relations and also generalized by more classic kinds of KRs, e.g. logical formulas representing rules.
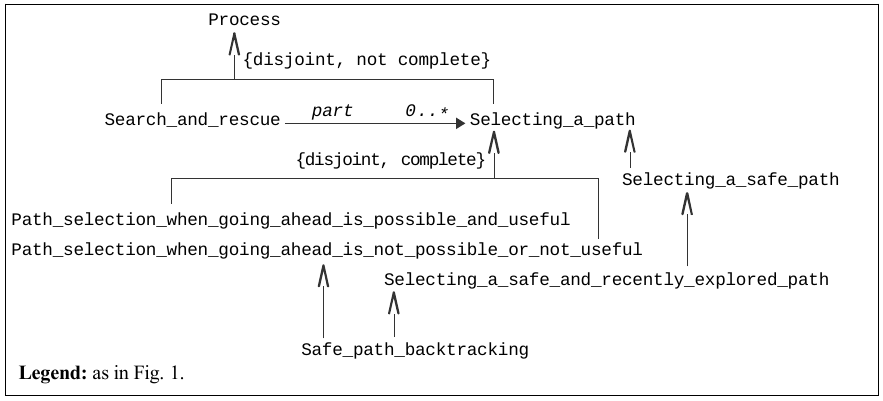
Fig. 2 shows some relations (a partOf one and several subtype ones) between top-level tasks in Search & Rescue. Such relations are useful for categorization purposes, e.g. to organize and exploit a library of functions useful for Search & Rescue, as explained in the introduction of this article. Such a library may for example organize functions which represent different ways of performing similar tasks. This library – and hence programs reusing it – may also include a function that selects the most relevant of these different ways for a particular environmental context given as a parameter. Box 8 shows some further subtype relations from one of the tasks mentioned in Fig. 2.
|
|
|
3.4. Representations About How To Create Rovers Adapted To A Terrain
[Bertolino & Tanzi, 2019a] and [Tanzi & Bertolino, 2019b, 2019c] are research articles (here ordered by increasing length) about a simulation tool helping to design rovers adapted to a terrain, for Search & Rescue purposes. Since the content of these articles is in natural language, it is difficult – from this content, manually or automatically – to identify, match, represent and synthesize i) all the important kinds of the described objects (e.g., the described tasks and their instruments, subtasks, inputs, outputs, ...) and ii) the relations between these objects. Box 9 illustrates relations from processes and software, and Box 10 illustrates relations from artifacts, attributes and descriptions. These boxes also show how the represented types are categorized as subtypes of top-level types from the MSO. The relations are representations are mostly formal but the use of informal parts (the strings within double quotes) is also illustrated since it is sometimes difficult or not worthwhile to formalize everything. Without all such relations, such objects cannot be retrieved via semantic browsing or querying. Without a shared KB (such as the ones described in Section 2.3) where such objects and relations can be found and complemented, general KS cannot be supported. Ideally, such relations should be added into shared KBs by the information authors (researchers, engineers, technicians, ...). Indeed, as earlier noted, relying on knowledge engineers to read articles and represent such relations is not scalable and articles often lack the information necessary for inferring generalization relations or other important relations.
|
|
4. Conclusion
The first kinds of contributions of this article were i) its highlighting of the insufficiencies of restricted KS – hence, the waste of efforts and opportunities that not using general KS is for supporting generals tasks such as risk/emergency management – and ii) its panorama of complementary techniques supporting general KS. Most of general KS related research focus on the content of foundational or lexical ontologies. Section 2.2 is about the (manual) integration of such ontologies into a unique one, something far less researched. More generally, the four subsections of Section 2 have to draw on techniques previously developed by the first author, for the presented techniques to be both complementary and relevant for general KS. Although some new research elements have been included, the originality of the provided panorama is in the synthesis it makes: together, the described techniques provide a rather complete approach for supporting general KS efforts useful for risk/emergency management, while still allowing the reuse of advances in the well researched field of restricted KS. Together, these techniques answer the following research question: how to let Web users collaboratively build KBs i) that are not implicitly “partially redundant or inconsistent” internally or with each other, ii) that are complete with respect to certain criteria or subjects, iii) without restricting what the users can enter nor forcing them to agree on terminology or beliefs, and iv) without requiring people to duplicate knowledge in various KBs, or to manually search knowledge in various KBs and aggregate knowledge from various KBs?
Via Section 3, the second kinds of contributions of this article were i) KRs showing how complementary kinds of risk/emergency management related information can be represented for general KS purposes, and ii) highlights of the interest of creating or reusing such KRs. The focused example domains were i) the UNDRR terminology, ii) a general model to represent and organize Search & Rescue information, iii) procedures or tasks for automatically exploring a disaster area, and iv) research articles about the use of a simulation tool for creating rovers adapted to a terrain. The prototype rover designed using the above represented pieces of information (Tanzi and Bertolino, 2021) is also validating them.
KRs will also continue to be added to the MSO of the WebKB-2 server for supporting risk/emergency management. WebKB-2 – and especially its procedures for evaluating or preserving the KB content quality and general KS supporting organization – will continue to be refined. These procedures allow their users to exploit the ontologies of their choices, and thus so far are generic: they have not yet proved to be domain sensitive, including in risk/emergency management.
5. References
- Arp R., Smith B. & Spear A.D. (2015). Building ontologies with basic formal ontology. Mit Press, ISBN 978-0-262-52781-1.
- Bergman M.K. (2018). A Knowledge Representation Practionary: Guidelines Based on Charles Sanders Peirce. Springer International Publishing, 464 pages, December 2018, ISBN 978-3-319-98091-1.
- Bertolino M. & Tanzi T.J. (2019a). Advanced Robot 3D Simulation Interface for Disaster Management. In IEEE 2019 Kleinheubach Conference (pp. 1-4).
- Borgo S. & Masolo C. (2009). Foundational choices in DOLCE. Handbook on ontologies (pp. 361-381). Springer, Berlin, Heidelberg.
- Codescu M., Horozal F., Kohlhase M., Mossakowski T. & Rabe F. (2011). Project Abstract: Logic Atlas and Integrator (LATIN). In Intelligent Computer Mathematics 2011, LNCS 6824 (pp. 287-289).
- Codescu M., Kuksa E., Kutz O., Mossakowski T. & Neuhaus F. (2017). Ontohub: A semantic repository engine for heterogeneous ontologies. Applied Ontology, 12(3-4), pp. 275-298, 2017.
- Del Vescovo C., Horridge M., Parsia B., Sattler U., Schneider T. & Zhao H. (2020). Modular structures and atomic decomposition in ontologies. Journal of Artificial Intelligence Research, 69, 963-1021.
- Dodds L. & Davis I. (2012). Linked Data Patterns – A pattern catalogue for modelling, publishing, and consuming Linked Data. Web document: http://patterns.dataincubator.org/book/, 56 pages, 2012.
- Dobrinkova N., Kostaridis A., Olunczek A., Heckel M., Vergeti D., Tsekeridou S., Seynaeve G., De Gaetano A. Finnie T., Efstathiou N. & Psaroudakis C. (2016). Disaster Reduction Potential of IMPRESS Platform Tools. In the revised selected papers of ITDRR 2016 (pp. 225-239, Springer), Cham.
- Elmhadhbi L., Karray M.H., Archimède B., Otte J.N., Smith B. (2021). An Ontological Approach to Enhancing Information Sharing in Disaster Response. Information 2021, 12(10), 432. https://doi.org/10.3390/info12100432
- Euzenat J. (1996).
Corporate memory through cooperative creation of knowledge bases and hyper-documents.
In KAW 1996 (36, pp. 1-18), Banff, Canada, November 1996.
http://ksi.cpsc.ucalgary.ca/KAW/KAW96/euzenat/euzenat96b.html
See also http://www.inrialpes.fr/exmo/papers/exmo1995.html#Euzenat1995a - Farquhar A., Fikes R. & Rice J. (1997). The Ontolingua Server: a tool for collaborative ontology construction. International Journal of Human-Computer Studies, Volume 46, Issue 6 (pp. 707-727, Elsevier), June 1997.
- Gharzouli M. & Makhlouf D. (2014). To Implement an Open-MAS Architecture for Semantic Web Services Discovery: What Kind of P2P Protocol Do We Need?. International Journal of Agent Technologies and Systems (IJATS) 6(3), 58-71, 2014.
- Gaur M., Shekarpour S., Gyrard A. & Sheth A. (2019). empathi: An ontology for emergency managing and planning about hazard crisis. In 2019 IEEE 13th International Conference on Semantic Computing (ICSC) (pp. 396-403).
- Ginsberg M.L. (1991). Knowledge interchange format: The KIF of death. AI magazine, 12(3), pp. 57-63, Fall 1991.
- Hayes P. (2006). IKL guide. URL: https://www.ihmc.us/users/phayes/IKL/GUIDE/GUIDE.html
- Inan D.I., Beydoun G. & Opper S. (2015). Towards knowledge sharing in disaster management: An agent oriented knowledge analysis framework. In Australasian Conference on Information Systems 2015, Adelaide, South Australia.
- Islam M.T., Mursalin A. & Xuemin S. (2010). P2P Approach for Web Services Publishing and Discovery. In Handbook of Peer-to-Peer Networking (pp. 1315-1332), Springer, Boston, MA, 2010.
- Jain S., Mehla S. & Wagner J. (2021). Ontology-supported rule-based reasoning for emergency management. Web Semantics 2021 (Cutting Edge and Future Directions in Healthcare; pp. 117-128), Academic Press.
- Kontopoulos E., Mitzias P., Mossgraber J., Hertweck P., van der Schaaf H., Hilbring D., Lombardo F., Norbiato D., Ferri M., Karakostas A., Vrochidis S. & Kompatsiaris I. (2018). Ontology-based Representation of Crisis Management Procedures for Climate Events. In ICMT 2018 (Workshop on Intelligent Crisis Management Technologies for Climate Events), at ISCRAM 2018, Rochester NY, USA.
- Kauppinen T. & Hyvönen E. (2004). Bridging the semantic gap between ontology versions. In Web Intelligence Symposium, Finnish AI Conference (Vol. 2, pp. 2-3), Vantaa, Finland September 1-3, 2004.
- Lehmann J., Isele R., Jakob M., Jentzsch A., Kontokostas D., Mendes P., Hellmann S., Morsey M., van Kleef P., Auer S. & Bizer C. (2015). DBpedia - A large-scale, multilingual knowledge base extracted from Wikipedia. Semantic Web, 6(2), pp. 167-195 (2015).
- Lenat D. & Guha R.V. (1990). CYC: A Midterm Report. AI Magazine, 11(3), 32, Fall 1990.
- Loser A., Schubert K. & Zimmer F. (2004). Taxonomy-based routing overlays in P2P networks. In IDEAS 2004 (pp. 407-412), Database Engineering and Applications Symposium, 7-9 July 2004.
- Malizia A., Astorga-Paliza F., Onorati T., Díaz P., & Aedo Cuevas I. (2008). Emergency Alerts for all: an ontology based approach to improve accessibility in emergency alerting systems. In ISCRAM 2008 (pp. 197-207), 5th International Conference on Information Systems for Crisis Response and Management, Washington DC, USA.
- Martin Ph. (2002). Knowledge representation in CGLF, CGIF, KIF, Frame-CG and Formalized-English. In ICCS 2002, 10th International Conference on Conceptual Structures (Springer, LNAI 2393, pp. 77-91), Borovets, Bulgaria, July 15-19, 2002.
- Martin Ph. (2003). Correction and Extension of WordNet 1.7. In ICCS 2003, 11th International Conference on Conceptual Structures (Springer, LNAI 2746, pp. 160-173), Dresden, Germany, July 21-25, 2003.
- Martin Ph. (2004). The Multi-Source Ontology (MSO) of WebKB-2. Web document: http://www.webkb.org/doc/MSO.html
- Martin Ph. (2009). Towards a collaboratively-built knowledge base of&for scalable knowledge sharing and retrieval. HDR thesis (240 pages; “Habilitation to Direct Research”), University of La Réunion, France, December 8, 2009. http://www.webkb.org/doc/papers/hdr/
- Martin Ph. (2011). Collaborative knowledge sharing and editing. International Journal on Computer Science and Information Systems (IJCSIS; ISSN: 1646-3692), Volume 6, Issue 1, pp. 14-29.
- Martin Ph. & Bénard J. (2017). Creating and Using various Knowledge Representation Models and Notations. In ECKM 2017 (pp. 624-631), 18th European Conference on Knowledge Management, Barcelona, Spain, September 7-8, 2017.
- Martin Ph. (2020). Representation and organization of the UNDRR terminology. Web document: http://www.webkb.org/kb/nit/o_risk/UNDRR/d_UNDRR.fl.html
- Neutel S. & de Boer M.H. (2021). Towards Automatic Ontology Alignment using BERT. In AAAI Spring Symposium: Combining Machine Learning with Knowledge Engineering, 2021.
- ODM (2014). ODM: Ontology Definition Metamodel, Version 1.1. OMG document formal/2014-09-02. http://www.omg.org/spec/ODM/1.1/PDF/
- OMG (Object Management Group) (2007). OMG Unified Modeling Language Superstructure Specification, version 2.1.1. Document formal/2007-02-05, Object Management Group, February 2007. http://www.omg.org/cgi-bin/doc?formal/2007-02-05.
- Munkvold E.B., Opach T., Pilemalm S., Radianti J. & Rod J.K. (2019). Sharing Information for Common Situational Understanding in Emergency response. In European Conference of Information Systems (ECIS), Uppsala, Sweden, 2019.
- Speer R., Chin J. & Havasi C. (2017). ConceptNet 5.5: An Open Multilingual Graph of General Knowledge. In 31st AAAI conference (pp. 4444-4451) San Francisco, USA, February 4-9, 2017.
- Shadbolt N., Berners-Lee T. & Hall W. (2006). The Semantic Web Revisited. In IEEE Intelligent Systems, vol. 21, no. 3, pp. 96-101, Jan.-Feb. 2006, doi: 10.1109/MIS.2006.62.
- Sharma A., Goolsbey K. & Schneider D. (2019). Disambiguation for Semi-Supervised Relation Extraction of Complex Relations in Large Commonsense Knowledge Bases. In the 7th Conference on Advances in Cognitive Systems, 2019.
- Snaprud M., Radianti J. & Svindseth D. (2016). Better access to terminology for crisis communications. In the revised selected papers of ITDRR 2016 (pp. 93-103, Springer), Cham.
- Tanon T.P., Pellissier T., Vrandečić D. & Schaffert S. (2016). From Freebase to Wikidata: The Great Migration. In WWW 2016, 25th International Conference on World Wide Web (pp. 1419-1428), April 11, 2016.
- Tanzi T.J. & Bertolino M. (2019b). Towards 3D Simulation to Validate Autonomous Intervention Systems Architecture for Disaster Management. In ITDRR 2019 (12 pages, hal-02364504), Information Technology in Disaster Risk Reduction, Oct 2019, Kiew, Ukraine.
- Tanzi T.J. & Bertolini M. (2019c). 3D Simulation to Validate Autonomous Systems Intervention in Disaster Management Environment. In the revised selected papers of ITDRR 2019 (pp. 196-211: 16 pages, Springer), Cham.
- Tanzi T.J. & Bertolino M. (2021). Autonomous Systems for Rescue Missions: Design, Architecture and Configuration Validation. Information Systems Frontiers, 23, pp. 1189-1202.
- Toure M., Guidedi K., Gandon F., Lo M. & Guéret C. (2020). MoRAI: Geographic and Semantic Overlay Network for Linked Data Access with Intermittent Internet Connectivity. In WI-IAT 2020, IEEE/WIC/ACM International Joint Conference On Web Intelligence And Intelligent Agent Technology, Dec. 2020, Melbourne, Australia.
- UNDRR (United Nations Office for Disaster Risk Reduction) (2017). Report of the open-ended intergovernmental expert working group on indicators and terminology relating to disaster risk reduction. Web document: https://www.preventionweb.net/publications/view/51748
- W3C (World Wide Web Consortium) (2021). Semantic Web. Web document: https://www.w3.org/standards/semanticweb/