1.0.1. Gestion|ingénierie des connaissances
Génie logiciel
[software engineering] :
ingénierie du
développement de logiciel
[software development]
"Gestion|ingénierie des connaissances" (au sens des industriels)
[knowledge management] :
ensemble des techniques permettant de
collecter/extraire, analyser, organiser et partager des informations,
le plus souvent à l'intérieur d'une organisation, e.g.,
les connaissances
importantes d'un employé (carnet d'adresses, trucs/expertise, etc.)
avant qu'il ne parte à la retraite.
Ces informations sont généralement stockées sous la forme de
documents informels,
très rarement via des représentations des
connaissances, du moins jusqu'à présent.
Un outil permettant une telle gestion est un
système de gestion de connaissances (SGC)
[knowledge management system (KMS)].
"Gestion|ingénierie|acquisition des connaissances" (au sens des universitaires)
[knowledge engineering] :
ensemble des techniques permettant de
collecter/extraire, représenter, d'organiser et de partager des
connaissances
dans une base de connaissances (BCs), laquelle est gérée via un
système de gestion de BC (SGBC) [KB management system (KBMS)].
Système à base de connaissances (SBC) :
tout outil exploitant des (représentations)
de connaissances par exemple pour résoudre certains problèmes.
Techniquement, un SGBC est aussi un SBC mais est rarement classé en tant que tel.
Les systèmes experts sont
des SBCs mais ne sont pas forcément basés sur des
"connaissances profondes" (représentations détaillées de
connaissances nécessaires à
un raisonnement).
1.0.1. Gestion|ingénierie des connaissances
Exercice : reliez les types ci-dessus par des relations de spécialisation
et de sous-partie
(conformément aux
règles de base pour la représentation de connaissances)
thing
> partition
{ (entity
> (non-spatial_entity
> (software
> (SGC > excl{ SGBD (SBC > systeme_expert SGBC) } )
)
)
)
(situation
> (process
> (problem_solving_process
> (GCI = knowledge_management, //... au sens des industriels
tool: 1..* SGC,
> excl
{ (GCI_sur_donnees //ce que la plupart des industriels font
tool: 0..* SGBD 0..* informal_file 0..* formal-file
)
(GCI_sur_connaissances
> (GCU = knowledge_engineering, //... au sens des universitaires
subtask: GCI __[any->0..*, 0..*<-any] //rare mais possible
tool: 1..* SGBC
)
)
},
subtask:
gestion_de_contenu __[any->0..*, 0..*<-any]
GCU __[any->0..*, 0..*<-any] //e.g., pour certaines meta-data en GCI
)
)
)
)
};
1.0.3. Tâches génériques de résolution de problème
Hiérarchie de spécialisation sur les "tâches génériques" dans
la "méthodologie d'acquisition des connaissances"
KADS-I (Breuker & al., 1987)
(tâches dont les "modèles génériques" sont à
sélectionner, suivre et combiner
lors de l'élicitation et modélisation de connaissances
-> méthodologie "dirigée par les modèles" et donc "descendante") :
analyse_de_système
identification (d'une catégorie)
classification
classification_simple
diagnostic (identification d'une catégorie de faute)
diagnostic_faute_unique
diagnostic_par_classification_heuristique (modèle du domaine : modèle de faute)
diagnostic_systématique (modèle du domaine : modèle de rectitude)
localisation_structurelle
localisation_causale
diagnostic_fautes_multiples
évaluation (de correspondance ou d'adéquation : identification d'une classe de décision)
surveillance (identification d'une incompatibilité entre une norme et une observation)
prédiction (d'un état passé ou futur du système)
prédiction_de_comportement
prédiction_de_valeurs
modification_de_système
réparation
remède
contrôle
maintenance
synthèse_de_système
transformation
conception
conception_par_transformation
conception_par_raffinement
conception_par_raffinement_à_flot_unique
conception_par_raffinement_à_flots_multiples
configuration
planification
modélisation
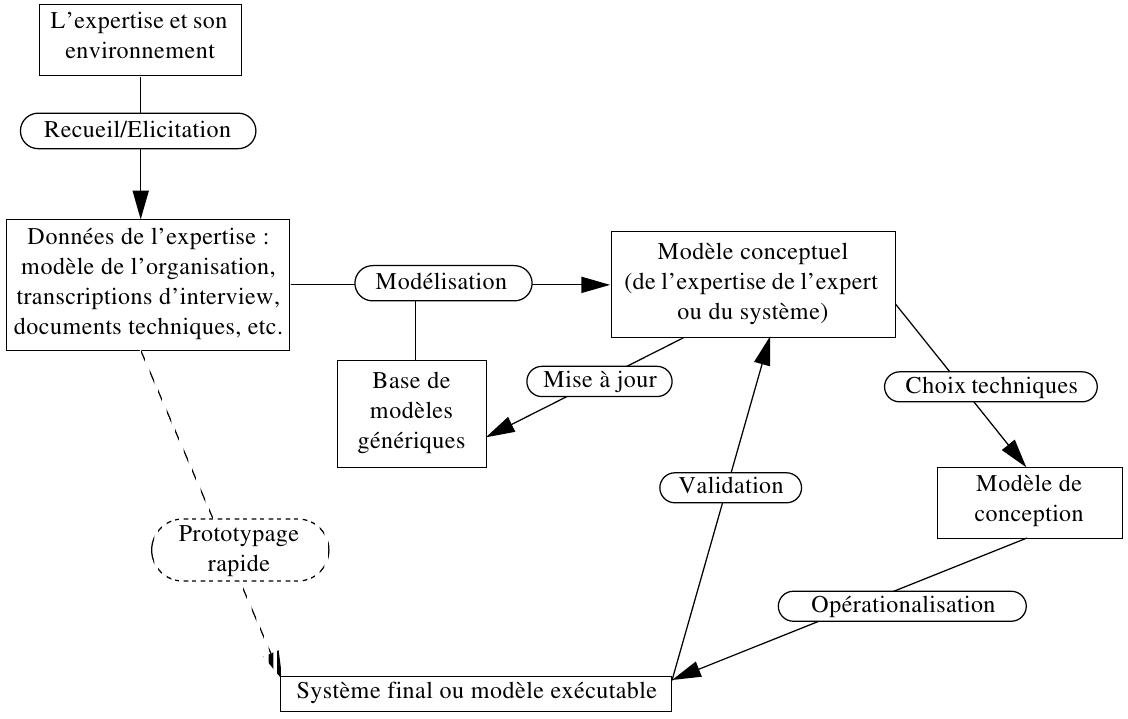
1.0.4. Exemple de modèle de tâche générique
Diagnostic systématique" dans KADS-I :
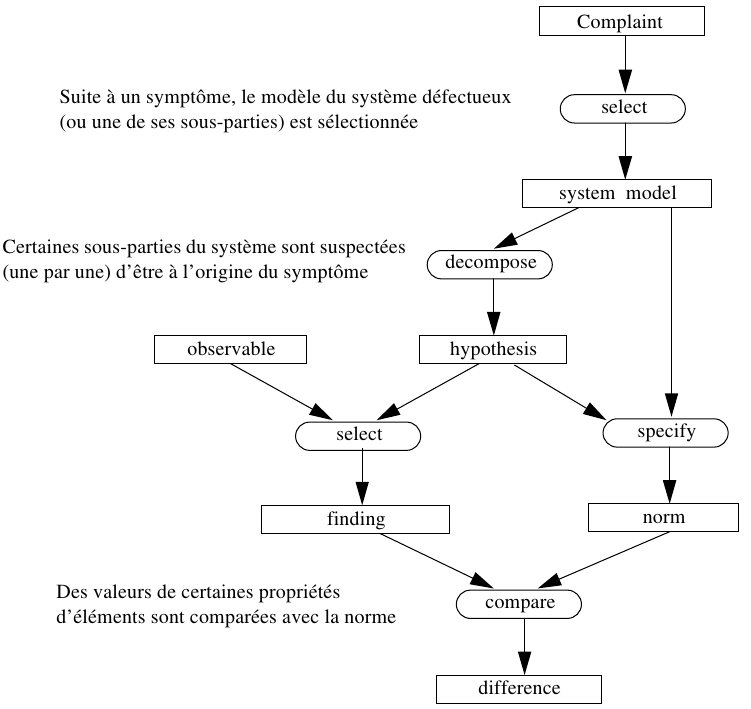
1.0.5. Tâches et méthodes dans CommonKADS
En théorie, dans KADS (et dans d'autres méthodologies),
une tâche ne se
décompose pas directement en sous-tâches :
une tâche est un but qui a des méthodes alternatives pour être atteint
et chaque méthode définit une décomposition en sous-tâches.
Le choix entre différentes méthodes pour une tâche est souvent fait
lors de la
modélisation, en fonction des contraintes de l'application visée.
Toutefois, lorsque cela est possible, il est préférable de modéliser la
façon d'effectuer
un tel choix pour que le SBC final puisse l'effectuer dynamiquement en fonction des
informations dont il disposera.
Il s'agit alors de modéliser une tâche qui
effectue des choix entre des méthodes.
Le choix de l'ordre entre des sous-tâches d'une méthode est le plus souvent
déterminé dynamiquement en fonction des diverses contraintes
statiques (e.g., relations entre les tâches) et
dynamiques (données fournies lors
d'une exécution).
Ce choix peut être effectué par le "moteur d'inférences sur
règles (déclaratives)" utilisé, ou peut être modélisé
dans une tâche séparée,
e.g., une tâche de planification [planning, scheduling].
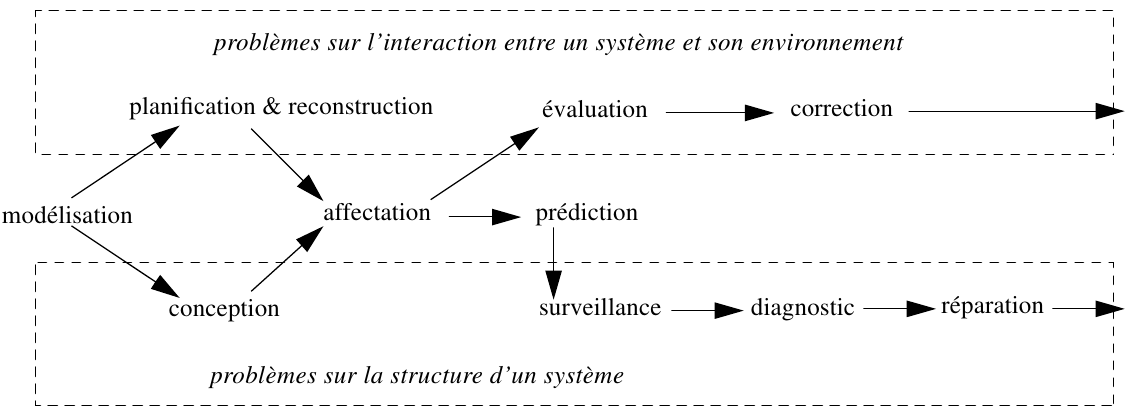
Dépendance entre les "tâches génériques" dans
CommonKADS (Breuker, 1994) :
1.0.6. Approches dirigées par les modèles / données
L'élicitation et modélisation des connaissances, i.e.,
la construction de modèles de tâches et d'objets utilisés par ces
tâches, peut être
- "dirigée par les modèles" et donc "descendante"
- "dirigée par les données" (interviews/articles d'experts, ...) et donc "ascendante"
- mixte (de manière opportuniste ou systématique).
Avec la popularisation du
Web sémantique
(liée à la prise de conscience des limites
du Web classique et, plus généralement, des nombreux problèmes liés au peu de
prise en compte des relations sémantiques dans les approches GL/BDD classiques),
les méthodologies de modélisation|analyse|spécification & conception de logiciel
prennent de plus en plus en compte les résultats des méthodologies de
modélisation de connaissances.
Toutefois, actuellement, cette prise en compte reste limitée. Ainsi, ce qui est appelé
"dirigée par les modèles" dans les 1ères méthodologies (celles pour le logiciel)
correspond à ce qui est appelé "dirigée par les données" dans les 2ndes.
Ce cours introduit - et fusionne partiellement - les 2 types de méthodologies
(puisque les 2ndes généralisent les 1ères et simplifient leur apprentissage)
mais il ne donnera pas d'exercice (ni d'évaluation) sur les modèles de tâches.
Par contre, les définitions liées à "tâche" (e.g., le lien entre
"tâche" et "méthode")
pourra faire l'objet d'évaluations.
1.0.7. Ne pas faire d'opérationalisation dans la phase de modélisation
Dans la phase de modélisation, plus les représentations de connaisances
sont précises et
organisées
(et donc (ré-)utilisables), mieux c'est.
Relisez les pages pointées par les deux liens ci-dessus (mots "précises" et
"organisées").
Ce sont les pages 2.6.1 et 2.6.2 du cours de coopération.
Pour relier|organiser des connaissances provenant de différentes sources,
relisez les pages 2.6.3 à 2.6.8.
Le but de la modélisation est de maximiser la (ré-)utilisation des connaissances
quelque soit l'application. Une représentation est alors "meilleure" qu'une autre
si elle contient plus d'informations, donc si elle peut la générer.
Ainsi, dans cette phase, il faut
- utiliser le langage de représentation de connaissances (LRC)
le plus expressif possible, et
- suivre le plus de méthodologies à la fois possible
(et donc spécialiser le plus d'ontologies possible).
Dans la phase de conception ou d'opérationalisation, les contraintes de
l'application visée sont prises en compte. Les connaissances peuvent alors,
si nécessaire, être converties dans un langage assurant des
performances minimales pour les inférences logiques, e.g., RDF + OWL2.
Contrairement à ce que semble préconiser le W3C, il ne faut pas tenter
d'utiliser de tels langages pour la modélisation et le partage de connaissances :
sauf pour des connaissances simples, cela conduit à des représentations
biaisées|incorrectes ou incomplètes, moins organisées et plus difficiles à
comparer, rechercher, fusionner, ... (-> gérer et exploiter).
Dans cette phase, pour des raisons de performance, un filtrage sur le contenu
de la BC - et sa division en modules peu reliés entre eux - peut être
nécessaire.
En effet, l'application peut ne pas avoir besoin de toutes les
connaissances d'une BC générique et un moteur d'inférences travaillera beaucoup
plus vite s'il a moins de connaissances à exploiter (i.e., comparer, enchaîner, ...).
1.0.7. Ne pas faire d'opérationalisation dans la phase de modélisation
Les langages qui utilisent une structure d'arbre (au lieu d'une structure de graphe),
commme XML et les langages orienté-objet, ne permettent pas - ou n'encouragent pas -
une représentation explicite de relations sémantiques entre objets d'information.
Le plus souvent, seules des relations "sous-partie" et "attributs-de" sont représentées,
ce qui conduit à des choix arbitraires, e.g., un objet "employé" doit être
représenté
comme sous-partie d'un objet "entreprise" ou inversement.
En résumé, dans les modèles à structure d'arbre
(XML, modèle orienté-objet, ...),
toute relation est implicite",
"locale à un object" (i.e., des relations de même
nom dans différents objets sont des relations différentes) et n'est donc pas une
entité du 1er ordre (i.e., elle n'a pas d'identifiant et ne peut donc
être mise dans
une variable). Ce sont les raisons pour lesquelles
le W3C a proposé le modèle RDF
quelques années après avoir
prososé XML (relisez ces raisons).
Si un langage de représentation des connaissances (LRC) suffisamment expressif
(i.e., basé sur une logique suffisamment expressive) est utilisé pour représenter
(une partie du/des sens) de l'information,
- les représentations peuvent être traduites dans différents langages
formels/informels
et selon différentes techniques ou paramètres permettant des
personnalisations,
- des déductions automatiques peuvent être effectuées pour faciliter
la recherche des
connaissances, leur partage et leur exploitation
(e.g., pour résoudre des problèmes et
prendre des décisions).
OWL2 (du W3C) est une ontologie de
langage pour la logique de description SROIQ(D),
qui est relativement expressive tout en restant
décidable.
Les logiques plus expressives ne sont pas généralement pas décidables.
La logique du 1er ordre (alias, "logique des
prédicats du premier-ordre") n'est pas décidable.
Dans cette logique, les prédicats|relations peuvent avoir des variables (ce n'est pas le
cas dans la logique des propositions, qui est donc
très peu expressive) mais il n'est pas
possible d'utiliser des variables pour les prédicats|relations.
Dans une logique d'ordre supérieur,
des variables pour les prédicats|relations peuvent
aussi être utilisées, et donc quantifiées.
Pour représenter des phrases en langage naturelle, il faut souvent au moins une
logique du 1er ordre avec en plus la possibilité d'utiliser des contextes
(méta-phrases) et
des ensembles.
1.0.7. Ne pas faire d'opérationalisation dans la phase de modélisation
Dans une base de connaissances, des représentations en logique du 2nd ordre (e.g., la
définition de la transitivité) peuvent être traduites en logique du 1er ordre,
en les
instanciant sur chacune des relations concernées (e.g., chacune des relations transitives).
C'est pourquoi, comme expliqué précédemment, il est judicieux
d'utiliser un langage
très expressif pour la phase de modélisation, puis de les convertir dans un langage
moins expressif lors de la phase de conception ou d'opérationalisation.
Exemple de phrase (ici une définition) du 2nd-ordre :
owl#transitive_property (?r) :=
[ [^x ?r: (^y ?r: ^z)] => [^x ?r: ^z] ];
//note: ^x, ^y et ^z are free variables, i.e., implicitely universally
// quantified: ^x is equivalent to 'every
pm#thing ?x'
Supposons qu'une BC contienne cette définition et la définition suivante de 'ancestor' :
ancestor type: owl#transitive_property;
Lors de la phase d'opérationalisation, il est alors possible des axiomes tels le suivant
et donc de supprimer la définition du second-ordre de la BC :
[ [^x ancestor: (^y ancestor: ^z)] => [^x ancestor: ^z] ];
1.0.8. Types de concept de plus haut-niveau essentiels
La page suivante organise des "types de concept" de haut-niveau les "plus
importants" dans le sens où ce sont ceux qui
- sont le plus intuitifs à utiliser pour catégoriser des sens de mots
(contrairement à, par exemple, "abstrait", "divisible", ...),
- ont le plus de liens d'exclusion entre eux (donc ceux qui permettent le
plus de
détections d'erreur de modélisation)
- sont le plus facilement utilisables pour des signatures de
"type de relations" primaires (i.e., non définissables par rapport à
d'autres types de relations)
- sont les plus faciles à utiliser (avec leurs types de relations primaires associées)
comme guide pour l'élicitation et la modélisation de connaissances.
Tout type de concept que vous représentez doit spécialiser un des
types de concept en "caractères gras non italiques" de la page suivante.
Des types de relations associées à ces types de concept sont ensuite donnés.
Exercice à effectuer pendant la lecture de la page suivante :
- Pour au moins 3 sens du terme "représentation de connaissances", citez leurs
généralisations parmi les types de concepts de page suivante.
Note: en français ou en anglais, "représentation" a une dizaine de sens,
ceux évidents lorsque l'on rajoute les adjectifs "théatrale", "syndicale", ...
en#"knowledge-representation"
> (knowledge-representation_process < process)
(knowledge-representation_content < description)
(knowledge-representation_character-string < description_instrument);
1.0.8. Types de concept de plus haut-niveau essentiels
thing (^anything that exists or that can be thought about^)
> partition
{ (situation (^"situ"; anything "occuring" in a real/imaginary region of time&space^)
> partition
{ state (^"stat"; situation that is not a process^)
(process (^"proc"; situation "making a change"^)
> (problem_solving_process (^e.g., software_lifecycle_process^)
> KADS_generic_process (e.g., KADS_systematic_diagnosis^)
)
(process_playing_a_role (e.g., consuming_process, creating_process^)
> event (^"evnt"; process considered instantaneous from some viewpoint^)
)
)
}
situation_playing_a_role (^e.g., outcome, accomplishment^)
)
(entity (^"enti"; thing that is not a situation -> that may "participate" to one^)
> partition
{ (spatial_entity (^"spac"^)
> excl{ (physical_entity (^"phys"^) > entity_that_can_be_or_was_alive)
spatial_non-physical_entity (^"snpe"; e.g., geometry_object^)
}
spatial_object_playing_a_role (^e.g., place, physical_entity_part/substance^)
)
(non-spatial_entity
> partition
{ (characteristic_or_attribute_or_measure
> partition
{ characteristic (^"chrc"; e.g., height, color, wavelength^)
attribute_or_measure (^"meas"; e.g., red, '620 to 740 nm'^)
}
temporal_entity (^"time"; e.g., date, duration^)
)
(description_content/instrument/support (^"desc"^)
> description (^"dcon"; e.g., concept_type, proposition^)
description_instrument (^"dins"; e.g., language^)
description_support (^"dsup"; e.g., file^)
)
non-spatial_entity_non-chrc/meas/desc (^"nseo", e.g., justice^)
}
)
}
entity_playing_a_role (^e.g., owner, agent^)
)
}
thing_playing_a_role (^e.g., creation, part^);
1.0.9. Types de relations de plus haut-niveau essentielles
À partir d'un processus (en FL ci-dessous, graphiquement page suivante) :
any process
relation_from_process_to_spatial_entity : 0..* spatial_entity,
relation_from_process_to_temporal_entity : 1..* temporal_entity,
relation_from_process_to_event : 1..* event,
relation_from_process_to_state : 1..* state,
relation_from_process_to_process_attribute: 0..* process_attribute,
relation_to_process_participant : 1..* participant,
relation_to_another_process : 0..* process,
relation_to_description : 0..* description;
relation_from_process_to_spatial_entity
> from_place place to_place via_places;
relation_from_process_to_temporal_entity
> since_time time duration frequency until_time;
relation_from_process_to_event
> triggering_event ending_event;
relation_from_process_to_state
> (predecessor_state > beginning_state precondition cause)
(successor_state > end_state postcondition consequence purpose);
relation_from_process_to_process_attribute
> manner speed;
relation_to_process_participant
> (relation_to_used_object alias: object,
> input object parameter material instrument)
(relation_to_participating_agent > agent initiator)
(relation_to_created-or-modified_participant
> (relation_to_created-or-modified_object
> input-output_object generated_object deleted_object)
(relation_to_modified_agent > patient experiencer recipient) );
relation_to_another_process
> specializing_process generalizing_process sub-process method embedding_process;
relation_to_description //useful for annotating but not for modelling knowledge/software
> description;
Note. Il y a de nombreuses manières de formaliser des contraintes sur
l'ordre d'exécution
de différent processus. Ces différentes
manières pourraient être représentées via des
spécialisations des types de relations 'predecessor_state' et 'successor_state'.
- Le langage des "réseaux de Petri" [Petri net]
est un des formalismes les plus expressifs
(lire la page pointée).
Il étend le langage des automates d'états finis.
- D'autres modèles permettant de représenter le parrallélisme|concurrence entre
processus sont : [process algebra],
[actor model] et
[trace theory].
1.0.9. Types de relation de plus haut-niveau essentiels - Graphique
------------------------0..*-->
|______________________________ spatial_entity temporal_entity <--1..*----------------------------
(relation_to_another_spatial_entity) ^ ^ |
\0..* 1..*/ |
\ / |
(relation_from_process_to_spatial_entity \ /(relation_from_process_to_temporal_entity |
> from_place place \ / > since_time time duration frequency |
to_place via_places) \ / until_time) |
\ / |
\ / (relation_from_state_to_temporal_entity)|
---0..*--> process_attribute \ / |
|____________________________________________ | | --------------------------------1..*--> event |
(relation_from_process_to_process_attribute \ | | /(relation_from_process_to_event |
> manner speed) \ | | / > triggering_event ending_event) |
\ | | / |
\| |/ |
state <-- 1..* ------------------------------ process ----------------------------------- 1..* --> state
| (predecessor_state / | | \ (successor_state |
| > beginning_state / | | \ > end_state postcondition |
| precondition cause) / | | \ consequence purpose) |
|(part) | | | | (part)|
| | | | | |
| (relation_to_process_participant | | | |(relation_to_created-or-modified_participant |
| > (relation_to_used_object | | | | > (relation_to_created-or-modified_object |
| alias: object, | | | | > input-output_object generated_object |
| > input_object parameter | | | | deleted_object) |
| material instrument) | | | | (relation_to_modified_agent |
| (relation_to_participating_agent| | | | > patient experiencer recipient) ) |
| > agent initiator) ) | | | | |
v v | | v v
1..* state <----------------- 1..* participant | | 0..* participant -----------------------> 1..* state
(state) / \ (state)
/ \
(relation_to_description / \(relation_to_another_process
> description) / \ > specializing_process generalizing_process
| | sub-process method embedding_process)
| |
0..*| |0..*
---------------------------0..*--> v v
|_________________________________ description process
(relation_to_another_description | | \
> generalizing-description | | \
sub-description correction) | | ------------------------0..*--> description_medium
| | (description_medium)
| |
agent <--1..*--------------------------/ \----------------------------0..*--> description_container
(description_believer) (description_container)
1.0.9. Types de relation de plus haut-niveau essentiels - exercice
Exercices de représentation en FL (sur des phrases en langage naturel,
en préparation à des modélisations plus difficiles en Génie Logiciel).
Aidez vous des types de relations de la page précédente:
- "In 2013, 80% of French persons write in French in order to be understood
by most French-speaking persons (who read them)"
[80% of French_person
agent of: (a writing
instrument: a French_dialect,
result: a description *d,
purpose: [*d object of:
(an understanding
agent: most (French_person
agent of:
(a reading object: *d)
) ) ] )
] time: 2013;
- "The content of the sentence 'Any/every man that travels from Chicago to Boston
from 14:00 to 16:00 on a Friday, gnaws all his nails' is described by this sentence".
Note: il manque d'importantes relations à cette assertion/"croyance" pour qu'elle
soit précise/vraie/utile. Lesquelles ?
[ [every (man agent of: (a travel
from_place: Chicago, to_place: Boston,
since_time: 14:00, until_time: 16:00,
time: a Friday ) )
?m agent of: (a gnawing object: every (nail part of: ?m))
] time: 2012,
description: "Any man that travels from Chicago to Boston, from
14:00 to 16:00 on a Friday, gnaws all his nails";
] believer: spamOnly@phmartin.info ;
1.0.10. À propos des questions qui/quoi/quand/où/comment
Exercice :
- Catégorisez des types de relations pouvent répondre aux questions
"who/what/why/where/when/how". Utiliser 'wh-/how_relation' pour identifier
leur plus proche supertype commun. Qu'en déduisez-vous concernant l'utilisation
des "wh-/how relations" pour l'élicitation, la catégorisation, et la
normalisation des connaissances (-> leur comparabilité et donc leur exploitabilité) ?
wh-/how_relation .(*) (^this type permits to categorize relations based on
who/what/why/where/when/how questions; this is a subjective and ineffective
way of categorizing relations;
since the meaning of these questions are subjective and not normalizing,
they should not be used for knowledge elicitation^)
> how_relation
who_relation what_relation why_relation where_relation when_relation;
how_relation
> instrument method sub_process
(how_much_relation
> duration relation_to_attribute_or_quality_or_measure
relation_from_collection_to_number);
who_relation (^e.g., agent initiator, patient, experiencer, recipient^)
> relation_to_participating_agent relation_to_modified_agent
owner generator creator; //for normalization purposes, do not use
//these last three types nor relations from agent to process
what_relation
> object/result process_attribute mereological_relation method
relation_from_collection relation_to_collection contextualizing_relation;
why_relation (^e.g., cause, method, goal, triggering_event, ...^)
> relation_from_process_to_state relation_from_process_to_event;
//for normalization purposes, do not use relations to process
where_relation (^e.g., where, from/to where, ...^)
> relation_to_spatial_entity part_of member_of;
//for normalization purposes, do not use '...-of' relations
when_relation
> relation_to_temporal_entity
1.0.11. Exemple de formulaire d'entrée semi-formel pour un process
Process type [give an identifier (e.g., wn#travel) or an informal name (e.g., "travel")]:
Where does it occur [e.g., in FL, `from:wn#Paris, to:"Berlin", via: ["Strasbourg", "Bohn"]´]:
When does it occur [e.g., `from:1/1/2001, to:31/12/2001,
frequency: "every 2nd Tuesday of the month", duration: 8 wn#hour´]:
After/before which process(es) does it occur [e.g., `triggering_event: wn#full_moon´]:
After/before which state(s) does it occur [e.g., `precondition: "John is at Paris"´]:
Who does/experiences/... it [e.g., `agent: JohnDoe.info, experiencer: JohnDoe.info´]:
What does it use/generate/... [e.g., `material: "100 kg of fuel", tool: a wn#train´]:
Which (direct) subprocesses does it involve [e.g., `subprocess: pm#train_changing´]:
Where is it described [e.g., `description: ThomsonSalesmanTravelsToBerlin.info´]:
1.0.12. Quelques autres règles de modélisation
Extension de la règle "Dans la phase de modélisation, plus les représentations
sont précises et organisées, mieux c'est" :
dans toutes les phases, plus les représentations sont normalisées,
(-> les plus comparables et donc exploitables), mieux c'est.
Donc, plus de conventions et méthodologies sont suivies, mieux c'est.
Attention toutefois, dans la phase d'opérationalisation,
"améliorer la performance" peut entrer en conflit avec "améliorer la normalisation"
lorsque cette dernière amélioration s'effectue par augmentation de la précision,
i.e., par augmentation de la possibilité de générer d'autres représentations et
donc de les comparer.
Un type de "chose jouant un rôle" (-> sous-type de thing_playing_a_role)
ne peut généraliser un "type de chose ne jouant pas un rôle".
Exercice 1 : en utilisant les types de concept déjà présentées,
représentez en FL
- 'person', 'customer', 'breathing', 'life' (sens communs des mots correspondants)
- "if a person ingests more calories more than what its body eliminates,
then he will put on weight".
Exercice 2 :
- comparez "normalisation des connaissances" et
"normalisation de BDD relationelles"
- la "dénormalisation de BDD"
a t-elle un équivalent pour les BCs ? Si oui, lequel
et durant quelle phase cela peut-il avoir lieu ?
1.0.13. UML
UML (Langage de Modélisation Unifié)
[Unified Modeling Language] :
langage (semi-formel, essentiellement graphique) de modélisation - général mais
orienté-objet (OO) - pour le Génie Logiciel.
Il a été créé dans les années 1990 en fusionnant divers
précédents langages de
modélisation : langages de
- modélisation de données (e.g.,
diagrammes d'entités-association)
- modélisation de composants (relations entre modules), et surtout
- modélisation OO et
"business modeling" (e.g., de workflows).
En France, Merise - une
"méthode d'analyse, de conception et de gestion de
projet informatique" basée sur des diagrammes d'entités-association - était
très utilisée dans les années 1970 et 1980 pour l'informatisation massive des
organisations, avant que UML n'apparaisse. Toutefois, UML n'est qu'un langage.
La méthode Merise - et, plus généralement, des méthodes de gestion de
projet|développement informatique ou d'urbanisation du système d'information
d'une organisation (i.e., sa conception
ou évolution) - peuvent être suivies en
utilisant (et étendant) le langage UML.
UML a été adopté en 1997 par
l'Object Management Group (OMG)
(un organisme de standardisation) et géré par lui depuis.
UML est défini avec le
méta-"language de modélisation" MOF (Meta-Object Facility)
de l'OMG.
En 2005, avec UML 2.0, l'OMG a corrigé et
étendu de manière importante
les versions UML 1.x. E.g., UML 2.0 contient
l'OCL (Object Constraint Language),
un langage déclaratif utilisable dans tous les modèles définis avec MOF.
OCL permet d'écrire des expressions|règles|contraintes. E.g. :
score > 88.33 and score <= 93.33 ; gender = #female or gender = #male ;
p implies q ; left xor right ; next->isEmpty or value <= next.value
self.grading and self.questions->size<10 ; p1 <> p2 implies p1.name <> p2.name
Student.allInstances->forAll( p1, p2 | p1 <> p2 implies p1.name <> p2.name )
UML fait l'objet de diverses critiques (mais c'est le cas pour tous les langages).
1.0.13. UML - Extensions
La focalisation de UML sur l'approche OO et ses faiblesses de formalisation le rendent
insuffisant pour de "bonnes" (i.e., précises, facilement partageables, ...)
représentations de connaissances. Divers
"véritables langages de modélisation"
(donc expressifs et basés sur des ontologies de haut niveau) sont toutefois
"compatibles" avec UML ou l'étendent, e.g.,
* OntoUML (un "profil UML" définissant une
"ontologie de langage" minimale pour
une modélisation correcte; cf. les 2 liens précédents)
* SBVR
("Semantics of Business Vocabulary and Business Rules"; adopté par l'OMG) :
- une ontologie de langage basée sur une "logique du 1er ordre +
modalités
aléthiques (nécéssité/possibilité
dans un/tous les mondes imaginables) et
déontiques (obligation/permission)
- "Structured English", un
langage controllé formel
pour cette ontologie de langage ;
cette notation est toutefois moins expressive, régulière et "normalisante"
que FL et Formalized-English, les 2 notations utilisées
dans ce cours (e.g.,
les processus sont représentés par des relations en "Structured English").
D'autres profils UML étendent UML, e.g.
- Executable UML (xtUML or xUML) : permet la
traduction automatique de
Platform-independent models (PIM)
(page à accéder et lire) dans des
Platform-specific models (PSM)
(page à accéder et lire)
- SysML : Systems Modeling Language (SysML)
- le "profil UML pour XML" : pour définir des
schémas XML|XSD.
1.0.13. UML - Diagrammes
Diagramme (structurel|statique / comportemental&interaction) d'UML:
représentation
* de relations (de types souvent prédéfinis par UML) entre des objets individuels.
* d'associations (relations-définitions, avec multiplicité - e.g., 1..* - et
navigabilité) ;
l'association 'part' est nommée aggrégation (UML la distingue via un losange coté
'container') ;
un seul sous-type est proposé : la composition (elle implique que la classe 'contained'
est
détruite lorsque la classe 'container' est détruite ; son losange est noir).
Exercice : il y a 1 erreur de modélisation dans le 1er exemple, et 2 dans le second. Lesquelles ?
//FL version without the 3 above referred modelling problems :
pond place of: duck __[any->0..*, 0..1<-any]; //'place of', not 'part
car part: carburetor __[any->0..10, 0..1<-any]; //1st problem: '0..10', not '1';
//2nd problem: 'part', not 'composition' since '0' in '0..1<-any'
1.0.13. UML - Diagrammes
Diagramme structurel|statique d'UML [structure diagram] : diagramme
* de classes
[Class diagram] :
- entre classes (types de concept), relations super/sous-type ('<', '>') et
toutes autres relations|"associations" avec leur multiplicité (e.g., 1..*) et navigabilité
- dans chaque classe (comme pour tout langage OO):
attributs (relation "locale" à chaque instance) et méthodes, avec leur
visibilité ("+": public; "-": private; "#": protected; "~": package; "/": derived; "_": static),
et
portée ("instance members": propre à chaque instance; "classifier members":
commune|"static")
* d'objets
[Object diagram] :
depuis des objets individuels (à un instant t),
attributs, relations de typage et autres relations statiques
* de composants
[Component diagram] :
relations d'assemblage|dépendance ou de délégation
entre composants: modules (paquetages, ..., exécutables), données (fichiers, BDD),
éléments de configuration (paramètres, scripts);
l'approche par composants accepte
toute réutilisation ; dans l'approche OO,
seul des
classes/objets "représentant" quelque chose "devraient" être réutilisés.
* de déploiement
[Deployment diagram] :
répartition des composants sur des
- "nœud physique|artefact|externe" [device nodes] : ordinateurs, périphériques,
réseaux, disques, ...
- "nœud logiciel|environnement|interne" ["Execution Environment Node"]: environnement, service, ...
* des paquetages
[Package diagram] : relations de type "import"|"uses"
et "merge" entre
modules (de définitions), i.e., entre espaces de noms.
* de structure composite
[Composite Structure diagram] :
relations de structure/role entre
composants (attributs, méthodes) d'une classe
* de profils [Profil diagram] :
relation de spécialisation ("apply") entre un profil et le
meta-modèle de référence qu'il étend.
1.0.13. UML - Diagrammes d'interaction ou dynamiques
Diagramme comportemental d'UML [behavior diagram] : diagramme
* des cas d'utilisation [use-case(s) diagram] :
depuis chaque processus|fonctionnalité, relations vers
- ses acteurs (relation non typée ni dirigée mais équivalente à la
relation 'agent')
- d'autres processus: relations de sous-partie ("include" / "extend") ou de
généralisation ('<') ;
* d'états(-transitions)
[UML State Machine diagram | UML statechart] :
relations (non typées mais équivalentes à'ending_event'/'triggering_event',
'successor_state'/'predecessor_state' ou 'successor_process'/'predecessor_process' entre
événements et
états" (au sens de UML; cela peut être aussi bien des états que des processus),
avec la restriction suivante (qui définit des "automates déterministes") :
1 état initial et au plus 1 événement/processus pour chaque
état (-> pas de parallélisme) ;
UML et la terminologie des
"automates (à états) finis"
donne le nom de "transitions" à ces
événements.
Les transitions peuvent avoir des "gardes" : expressions booléennes (sur
des variables d'états ou des paramètres d'événements) pour ajouter des
conditions sur le
"déclenchement" d'une transition.
Une transition peut être elle-même être décrite par
un autre
diagramme d'états(-transitions) ;
* d'activité
[Activity diagram] :
relations (non typées mais équivalentes à 'successor_process') entre
processus (appelés "décision" si ce sont des "tests de condition", et "actions" sinon)
;
Le parallélisme (-> plusieurs relations 'successor_process' depuis un processus) est
possible et régulé via des relations spéciales ("fork" puis "join") ;
il s'agit donc d'une sorte d'organigramme : une représentation graphique d'un algorithme,
pour montrer le "flot de données" et le "flot de contrôle" entre processus.
Les "réseaux de Petri" permettent
de combiner diagrammes d'activité et d'états(-transitions).
Diagramme d'interaction ou dynamique [Interaction diagram] : diagramme
* global d'interaction
[Interaction Overview diagram] :
diagramme d'activité dont chaque
nœud (chaque processus) peut être
(décrit par) un des diagrammes des types ci-dessous
(ceci permet de décrire l'enchaînement possibles entre ces sous-diagramme/processus) ;
* de séquence [Sequence diagram] :
représentation cartographique intuitive des relations
'successor_process' entre processus (avec leur agents) faisant ressortir qui "interagit"
avec qui via le système modélisé ; en effet, dans cette représentation
cartographique, les
processus sont placés en fonctions de 2 axes :
celui de leur acteur principale et celui du temps ;
* de communication [Communication diagram] :
un peu comme un diagramme de séquence mais
sans l'axe des acteurs ;
* de temps [Timing diagram] :
représentation cartographique des variations d'états de certaines
"variables de données" au cours du temps.
1.0.13. UML - Exercices
Représentez en FL
ce diagramme de classes et diagramme d'objets associé
puis ce diagramme des cas d'utilisation.
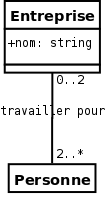
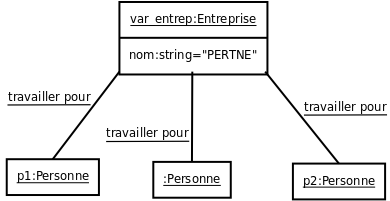
|
employeur
_(personne -> 0..* entreprise),
alias: travailler_pour;
entreprise
attribute: 1 (. nom < string),
employeur of : personne
__[any->2..*, 0..2<-any],
instance:
(entrep
employeur of :
the personne p1
a personne
the personne p2
);
|

|
process
> (food_eating
alias: eat_food)
(paying_for_food
alias: pay_for_food)
(wine_drinking
alias: drink_wine)
(food_cooking
alias: cook_food);
food_critic agent of:
1..* food_eating
1..* paying_for_food
1..* wine_drinking;
chef agent of:
1..* food_cooking; |
1.0.13. UML - Diagramme d'États(-transitions)
Représentation en FL du
diagramme d'états(-transitions) ci-dessous.
Les "états" (au sens d'UML ; ci-dessous de vrais états) sont en caractères gras.
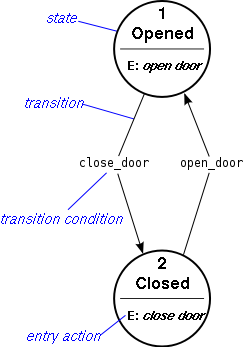 |
[a state *opened_door]
^ ^
beginning_state| |end_state
| |
[a door_closing [a door_opening
process processs
*close_door] *open_door]
| ^
end_state| |beginning_state
v |
[a state *closed_door]
//Or, equivalently (the parts in italics are optional):
a state *opened_door
is beginning_state of:
(a door_closing process *close_door
that has for end_state: a state *closed_door),
is end_state of:
(an opening_of_a_door *open_door
that has for beginning_state:
the state *closed_door);
//Or, equivalently:
a door_closing process *close_door
has for beginning_state: a state *opened_door,
has for end_state:
(a state *closed_door
that is beginning_state of:
(an opening_of_a_door *open_door
that has for end_state:
the state *opened_door)
);
|
1.0.13. UML - Diagramme d'États(-transitions)
Représentation en FL d'un autre
diagramme d'états(-transitions).
Les "états" (au sens d'UML"; ci-dessous interprétés comme étant
des processus)
sont en caractères gras. La manière de représenter ce
diagramme est donc
différente de celle pour le diagramme précédent.
Une même méthode peut
être utilisée si les "états au sens d'UML"
sont interprétés comme de "vrais états"
et les transitions entre eux
comme étant des événements. Toutefois, dans ce cas,
où sont les processus ?
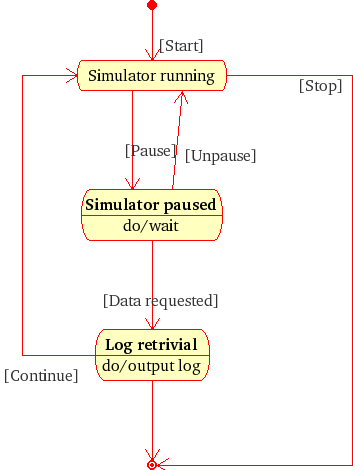 |
an event *start
triggering_event of:
(a running_of_a_simulator *simulator_running
ending_event:
(an event *stop
successor_state: a end *end
)
(an event *pause
triggering_event of:
(a wait *simulator_paused
ending_event of:
(an event *data_requested
triggering_event of:
(a log_output *log_retrieval
successor_state: *end,
successor_process:
*simulator_running
)
)
)
)
);
|
1.0.13. UML - Diagramme d'activité
Représentation en FL du début d'un
diagramme d'activité sur la gestion d'un
brainstorming de groupe. Les activités (processus) sont en caractères gras.
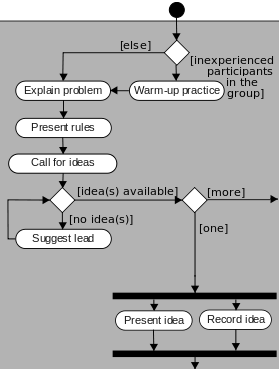 |
an event *start
successor_state:
([ ["inexperienced participants in the group"] = *ip] ]
successor_process _[<= [*ip = true] ]:
(a "warm-up practice"
successor_process: a "explain problem" *ep)
successor_process _[<= [*ip = false] ]:
(*ep successor_process:
(a "present rules"
successor_process:
a "call for ideas" *cfi //see below
) ) );
*cfi
output: [ ["idea(s) available"] = *ideas],
successor_process _[<= [*ideas = false] ]:
(a test
output: [ ["more than 1 idea"] = *moreThan1],
successor_process _[<= [*moreThan1 = true] ]:
a process *p1, //*p1 is outside of the figure
successor_process _[<= [*moreThan1 = false] ]:
(a "Present idea"
successor_process: a process *p2)
successor_process _[<= [*moreThan1 = false] ]:
(a "Record idea"
successor_process: *p2)
); //the last two processes have the same predecessor
// and precondition, and the same successor: *p2
// *p2 is outside of the figure on the left
|
1.0.13. UML - Réseau de Petri
Représentation du
réseau de Petri ci-dessous,
tout d'abord en
PNLF (Petri Net Linear Form, une notation textuelle
visuellement proche de la
notation graphique des réseau de Petri)
puis en FL.
Pour utiliser le formalisme des réseaux de Petri dans UML, il faut le
modéliser via un "profile".
Dans cet exemple, les états sont en caractères gras et les noms des types des
transitions (événements) finissent par une lettre majuscule.
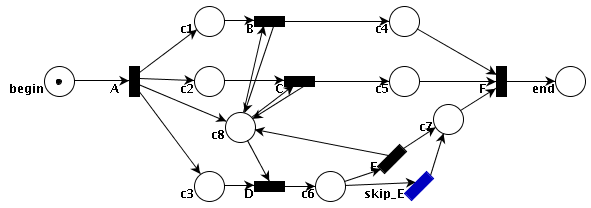 |
(begin @)→[A *a] { →(c1)→[B *b]→(c4)→[F *f]→(end), //représentation en PNLF
→(c2)→[C *c]→(c5)→[*f],
→(c3)→[D *d]→(c6) {yes→[E *e]→(c7 *c7),
no→[skip_E]→(*c7)→[*f] }
};
[*a]→(c8) { →[*d], ←[*e], →[*b], ←[*b], →[*c], ←[*c], →[*f] }.
a A *begin //représentation en FL
token_activation: 1, //this state is activated with 1 Petri Net token '@'
beginning_state of:
(a A *a end_state: (a c1 beginning_state of:
(a B *b end_state: (a c4 beginning_state of:
(a F *f end_state: a end) )))
(a c2 beginning_state of:
(a C *c end_state: (a c5 beginning_state of: *f)) )
(a c3 beginning_state of:
(a D *d end_state: a c6 *c6) )
);
*c6 beginning_state of _[<= [*someConditionDefinedElsewhere = true] ]:
(a E *e end_state: a c7 *c7),
beginning_state of _[<= [*someConditionDefinedElsewhere = false] ]:
(a skip_E end_state: (*c7 beginning_state of: *f));
*a end_state: (a c8 beginning_state of: *d *b *c *f, end_state of: *e *b *c);
|