










1. Définitions générales
1.1. Coopération et collaboration
1.2. Avantages/conditions pour une collaboration
1.3. Acteur idéal d'une collaboration
1.4. Outil idéal pour la collaboration
1.5. Coopération/travail-coopératif assisté par ordinateur
1.6. Logiciels collaboratifs, alias groupware
1.7. Web 2.0 et Web 3.0
1.8. Base de données (BD) et base de connaissances (BC)
2. Partager des informations (-> définir les problèmes à résoudre,
négocier, rechercher des décisions unanimes, coordonner, ...)
2.1. Choisir des média et outils de communication
2.2. Donner des identificateurs aux sources d'information et aux objets
2.3. Protéger l'accés aux informations
2.4. Présenter et exprimer des informations
2.5. Faciliter et personnaliser les interactions homme-machine
2.6. Représenter des informations
2.6.1. ... d'une manière correcte et précise
2.6.2. ... d'une manière organisée
2.6.3. ... d'une manière organisée via des relations d'argumentation
2.6.4. ... d'une manière explicite et sans perte
2.6.5. ... et des techniques pour l'évaluation collaborative
2.6.6. ... d'une manière modulaire au sein d'une BC centralisée/distribuée
2.6.7. ... d'une manière modulaire à des fins de programmation
2.6.8. ... d'une manière à la fois centralisée et distribuée
2.7. Délibérer et négocier pour créer le consensus
2.8. Trouver des idées pour les délibérations, négociations, ...
2.9. Attirer/allécher/retenir
2.10. Coordonner
3. Prendre des décisions (en particulier: choisir des règles/logiciels
de prise de décision)
3.1. Prendre/prédire des décisions individuelles
3.1.1. ... via la théorie des jeux
3.1.2. ... via la théorie/analyse de la décision
3.1.2.1. ... via la théorie/analyse de décision multi-critères
3.2. Prendre/prédire des décisions de groupe
3.2.1. ... via la théorie du choix social
3.2.2. ... via des systèmes de vote
e.g. (latin: exempli gratia):
"par exemple"
i.e. (latin: id est): "c'est-à-dire"
Coopération ou co-opération (intentionnelle ou non):
interactions (volontaires, accidentelles ou forcées) entre des agents
qui combinent les efforts de ces agents.
Ainsi, un processus qui fait combiner (des résultats de) processus en
compétition est un processus qui les fait coopérer:
la concurrence n'est pas de la coopération mais peut être
utilisée par elle.
La coopération peut être distribuée ou centralisée,
synchrone ou non.
Des agents coopérants forment un "système coopératif".
Coopération intentionnelle: coopération entre des agents volontaires.
Collaboration:
coopération entre des agents volontaires ayant un
objectif identique, e.g., réaliser un échange commercial
ou un projet.
Par rapport à coopérer, collaborer est donc une notion plus
spécialisée (et plus forte) mais parvenir à faire coopérer
des gens (non motivés pour collaborer) est plus difficile.
Le terme "collaboration" est plus souvent associée à des activités
supervisées (et donc centralisées) que le terme "coopération".
Comme la coopération peut impliquer des personnes n'ayant pas
forçément un but identique ou la volonté de collaborer,
le terme "coopération" est plus souvent associé à des efforts
de guerre/paix, de développement économique d'un pays, à
la théorie des jeux, aux wikis et aux projets open source.
Collaborer, c'est agir (et, en particulier, rechercher et diffuser des informations) de telle sorte que d'autres personnes puissent agir (et, en particulier, rechercher et compléter ces informations) de la manière la plus efficace possible, en temps et en résultats.
Intelligence d'essaim [swarm intelligence; parcourez cet article ainsi que celui sur les méta-heuritiques]: un comportement collectif, décentralisé et auto-organisé pouvant, selon certains points de vue, être interprété comme "intelligent". Ce comportement peut être naturel (e.g., le travail dans une colonie de fourmis, le rassemblement des oiseaux, le mouvement d'un banc de poissons) ou artificiel (agents en Intelligence Artificielle).
Intelligence collective: intelligence de groupe (convergence des comportements ou de connaissances dans un groupe) qui émerge lors de la collaboration ou de la concurrence entre de nombreuses personnes. L'intelligence collective est fortement liée à "l'intelligence d'essaim" mais ses agents sont plus souvent des personnes. Elle peut par exemple subvenir parce que la majorité des membres du groupe ont une "mentalité de troupeau/mouton" [herd mentality].
Exercice de compréhension et de représentation de connaissances:
- relier les concepts de "coopération", de "collaboration", de "groupe"
de "système de coopération" et de "système de collaboration" et
d'essaim - tels que définis ci-dessus - via des relations "sous-type" ou "exclusion"
(exemple préalablement donné au tableau);
- raffiner/généraliser(/illustrer) au moins un des trois derniers concepts en utilisant
une relation "sous-type" (ou bien "instance" si vous ne trouvez qu'une
illustration).
//========= Représentation graphique // Avec "s" pour "spécialisation" et "e" pour "exclusion". // Une relation de type "R", de source "S" et de destination "D" se lit "S a pour R D". // E.g.: "(le type) chose a pour spécialisation (le type) entité // "X s: Y" <=> "∀x, 'x instance of: X' => 'x instance of: Y' " // Une relation entre "individus" (instances de types du 1er ordre), e.g., celle de type "agent" // doit avoir une cardinalité pour sa destination (par défaut, la source est ∀) chose / \ /s \s / \ v v situation <--e--> entité / | \ /s |s \s v v v processus état groupe / \ /s \s v v coopération --agent--1..*--> système_de_coopération / |s \ /s v \s / essaim \ v | v collaboration |s système_de_collaboration v essaim_d_abeille //========= Représentation dans la notation textuelle FL: // Une relation "S R: D" se lit "X a pour R D" ou, en anglais, "X has for R D" // Une relation "S R of: D" se lit "X est R de D" ou, en anglais, "X is R of D". // ">" est une abbréviation de "spécialisation: " chose > (situation exclusion: entité, > (processus > (coopération agent: 1..* système_de_collaboration) collaboration ) ) (entité > (groupe > (système_de_coopération > système_de_collaboration (essaim > essaim_d_abeille) ) ) );
Avantages:
- plus grandes chances d'obtenir (plus facilement) quelque chose;
- pouvoir se spécialiser (i.e., ne pas tout faire/savoir) et donc être plus
efficace (division du travail);
- pouvoir connaître de nouvelles idées/habitudes et les appliquer;
- la valeur d'un réseau avec N noeuds peut être proportionnelle à
e.g. N, N1,5 ou N2 (Loi de Metcalfe).
Inconvénients:
- à court terme: l'investissement en temps et/ou argent;
- si la collaboration échoue, perte de temps/argent/réputation;
- moins de vie privée puisque la collaboration implique l'accessibilité
des informations;
- le coût de la coordination dans une équipe de N personnes peut être
proportionnelle à
e.g. environ N2 selon la
loi de Brooks:
ajouter des personnes à un projet en retard accroît son retard
car a) il faut les former,
b) les temps de communication sont proportionnels à N*(N-1),
c) beaucoup de tâches ne sont pas partitionables.
Conditions usuelles pour collaborer avec une autre personne:
- au moins un but commun
- une chance de rencontrer ou bien collaborer de nouveau avec cette personne
- succès des précédentes rencontres ou collaboration avec
cette personne.
Des résultats en
économie expérimentale
indiquent que
les êtres humains sont souvent coopératifs même
lorsque cela ne leur rapporte rien
(e.g., ils aident des gens même
s'ils ont peu de chances de les revoir).
Cela peut s'expliquer de la façon
suivante:
- même au niveau individuel, il est généralement payant
d'être systématiquement coopératif
lorsque les ressources sont limitées, comme le montrent la
théorie des jeux (en particulier
la théorie des jeux à somme nulle),
le succés de la stratégie coopération-réciprocité-pardon,
l'altruisme réciproque et la théorie du livre "Tragedy of the commons";
- c'est encore plus vrai au niveau du groupe (un groupe dont les membres sont
coopératifs
est plus compétitif, ce qui est "en moyenne" payant
pour ses membres même si l'intérêt
de certains membres est
"sacrifié";
- beaucoup d'êtres humains sont suffisamment rationnels pour comprendre les
deux arguments précédents;
- la sélection naturelle (entre individus et entre groupes) a conduit à
ce que les êtres humains
soient relativement coopératifs lorsque
cela ne nuit pas à leurs intérêts.
D'autres raisons plus détaillées existent. Un certain nombre d'entre elles
se trouvent dans les articles de recherche de "Cooperation Commons". Cette vidéo est également intéressante.
Note sur le modèle open-source. Il est l'emblème d'un large mouvement coopératif atteignant ses objectifs. Toutefois, les mouvements open-source n'utilisent actuellement pas d'outils avancés pour aider la coopération. Ceci peut expliquer pourquoi ces mouvements ont du succès essentiellement lorsque le but à atteindre et ses sous-tâches sont bien définis et bien connus par leurs membres (c'est par exemple généralement le cas pour la conception d'un système d'exploitation).
Être "ouvert" (dans le sens de rechercher/donner des données/idées) est nécessaire pour coopérer, mais ce n'est pas une condition suffisante ni un critère caractéristique. En effet, il est également souvent payant d'être "ouvert" dans le contexte d'une compétition, comme c'est le cas en recherche et pour les organisateurs de concours scientifiques ou d'ingénierie.
Exercice:
raffiner/généraliser(/illustrer) au moins un avantage, un
inconvénient et une condition
(parmi ceux ci-dessus) en utilisant
à chaque fois au moins une relation sous-type(/instance).
Idéalement, un acteur (ou participant) d'une collaboration
L'idée maitresse du livre
"Wisdom of the Crowds" est que
"un groupe plus important est plus intelligent qu'un groupe plus petit"
- si les membres sont sages/rationnels (le livre développe le 2nd point
ci-dessus), et
- si "un dispositif existe pour que les jugements individuels soient
transformés
en une décision collective", donc si
un "outil idéal/adéquat pour la collaboration"
est utilisé.
Un problème principal est donc de créer de tels outils et que ceux-ci
puissent (aider les gens à) reconnaitre les meilleures
connaissances/idées/solutions.
Exercice:
1) compléter ou raffiner/généraliser(/illustrer) chacune des 4 types de
tâches ci-dessus
en utilisant à chaque fois au moins une relation
sous-type(/instance).
2) que peut faire - avec des outils du Web désormais classiques - une personne
souhaitant être "coopérative" à chaque fois qu'elle
reçoit un email relatif à
son travail et ne contenant pas ou peu
d'informations confidentielles ?
3) décrivez et justifiez les caractéristiques d'un enseignant idéal
puis celles d'un étudiant idéal.
Lire aussi cet article sur les "aptitudes et les qualités requises pour collaborer efficacement".
Idéalement, un outil d'aide à la collaboration devrait
Exercice:
- compléter ou raffiner(/illustrer) chacune des 5 types de tâches
ci-dessus
en utilisant à chaque fois au moins une relation
sous-type(/instance).
Collaboration assistée par ordinateur [Computer-supported_collaboration (CSC)]:
(étude de) l'utilisation des ordinateurs et/ou de l'intranet/internet pour
soutenir la collaboration au sein d'un groupe ou entre
groupes/organisations/communautés/sociétés.
En tant que champ
d'étude, le CSC inclut le CSCW (TCAO; cf. ci-dessous) mais se focalise sur
les systèmes de contrats
et de rendez-vous/coordination, e.g.,
les ventes aux enchères et les systèmes de marché.
Le terme SCC a émergé dans les années 1990 pour désigner un
champ d'étude généralisant les 3 anciens champs suivants:
Travail coopératif assisté par ordinateur (TCAO) [Computer supported cooperative work (CSCW)]:
(étude de) l'utilisation des ordinateurs en tant que support de
médiation dans des activités telles que la communication, la coordination,
la coopération, la concurrence, les jeux et l'art. Voici quelques exemples de
dimensions fondamentales du travail coopératif:
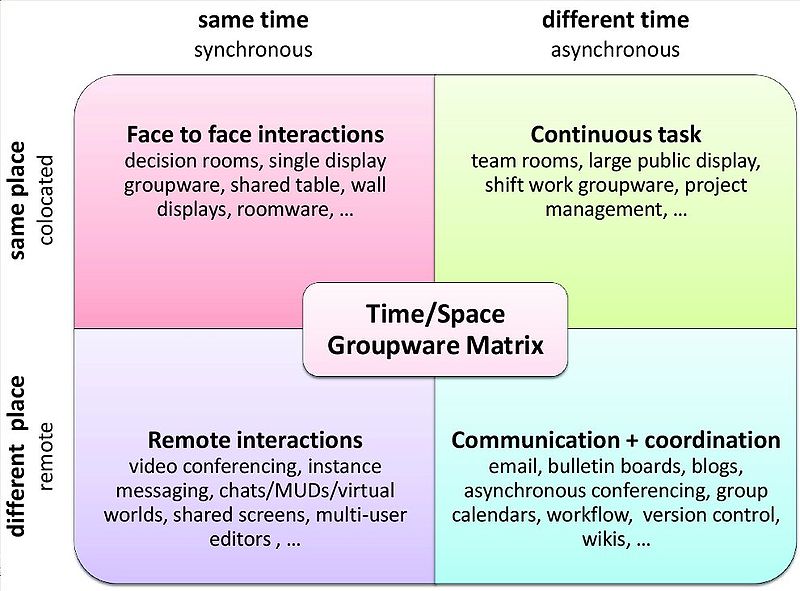
En résumé, la plupart des outils dits "de collaboration" sont actuellement
surtout des outils de communication d'informations (de manière synchrone ou pas,
à distance ou pas) et/ou de
modification d'un même fichier par divers utilisateurs.
Peu d'outils dits "de collaboration"
aident activement à coordonner/organiser des tâches et des informations.
Lors de l'étude ou la présentation d'un outil, il faut donc préciser et
approfondir ces trois distinctions.
Exercice:
- lesquels des 4 types d'outils/tâches ci-dessus sont pertinents pour classifier
les
types de systèmes suivants: "internet", la "publication de
documents Web", les
"tableurs en ligne",
les "réseaux sociaux", les "systèmes pair-à-pair" et les "bases de
connaissances partagées" ?
- pour chacun des outils listés dans la figure et la question ci-dessus,
indiquez ses caractéristiques
relevant de l'une des 5 sortes de
caractéristiques d'un "outil idéal pour la collaboration"
(section 1.4); si l'outil n'a pas de telles caractéristiques, donnez
celles qui s'en rapprochent le plus.
- pour chacun des 4 types d'outils ci-dessus, indiquez si un outil de ce type peut
être
un "outil idéal pour la collaboration" (section 1.4) et,
si oui, comment.
Web 2.0: mot "fourre-tout"
(utilisé à partir de 2001) désignant
- les technologies liées à la construction de
pages Web dynamiques
(générables automatiquement),
e.g., le
DOM (Document Object Model) et
Ajax (Asynchronous Javascript
and XML), et
- la participation des internautes à la construction et indexation de
documents Web via des
sites/systèmes collaboratifs tels que les wikis, les blogs, les
réseaux sociaux, les folksonomies
et les systèmes de
sciences citoyennes.
Par opposition à la partie du Web 2.0 du Web, le reste est un
"Web de documents statiques".
Web 3.0: mot "fourre-tout"
(utilisé à partir de 2009) désignant les futures applications,
combinaisons et évolutions des technologies récentes et en particulier
celles liées
- au Web Sémantique,
- à la mobilité, l'universalité et l'accessibilité:
internet des objets,
indépendance vis à vis des
supports matériels et des
systèmes d'exploitation, ...
- au graphisme vectoriel (e.g., SVG qui est en fait maintenant une ancienne
technologie) et
aux formulaires XForms.
Exercice:
- un outil du Web 2.0 qui n'est pas aussi un outil du Web 3.0 peut-il être
un
"outil idéal pour la collaboration" (section 1.4) ? Pourquoi ?
Base d'informations:
base de données/connaissances.
Base de données (BD): ensemble structurellement organisée de données, i.e, des objets d'information dont la sémantique n'est pas explicitement "représentée". En effet, dans une BD, il existe essentiellement trois 'types de relation' explicites : partie, type et attribut. Un document structuré (e.g., un document XML) peut donc être considérée comme une BD. Inversement, une BD peut être stockée dans un document structuré. Les types de données autorisées et leurs relations possibles sont souvent spécifiées dans un schéma structurel (de BD/document). Ce schéma est fixe/prédéfini: l'utilisateur d'un SGBD ne peut dynamiquement ajouter/définir de nouveaux types de données et ne peut définir de nouveaux types de relations.
Base de connaissances (interprétable par la machine) (BC): ensemble de représentations de connaissances, i.e., d'assertions logiques reliant des objets d'information via des relations sémantiques (qui sont également des objets d'information). L'utilisateur d'un SGBC peut dynamiquement ajouter de nouveaux types d'objets à une BC (via des définitions ou des déclarations) et les utiliser.
SGBD: système de gestion de BDs.
SGBC: système de gestion de BCs.
Exercice:
- un outil directement basé sur un SGBD peut-il être un
"outil idéal pour la collaboration" (section 1.4) ? Pourquoi ?
- un SGBC peut-il être basé sur un SGBD ? Comment ?
Si possible, les outils de communication assistée par ordinateur doivent être choisis/conçus pour pouvoir utiliser un nombre maximum de média et de contraintes. Il faut donc par
exemple mieux choisir/concevoir des outils de communication qui
peuvent marcher avec une faible bande passante minimale, de
manière asynchrone, sur une longue distance, avec qui la
communication est enregistrable mais où l'anonymité
des participants peut être assurée s'ils le désirent.
Si possible, les outils doivent aussi être choisis/conçus pour pouvoir exploiter les caractéristiques des voies de communications disponibles. Par exemple, pour faciliter la collaboration, il peut être utile d'utiliser en même temps plusieurs voies de communication à haut débit peut être utile. En effet, des choses simples - comme voir les yeux d'une autre personne clairement via une résolution suffisante sur les écrans de vidéo et la possibilité de zoomer - peuvent aider de manière importante les participants à se faire confiance et à collaborer à distance.
Des objets d'information et des informations sur des objets physiques sont beaucoup plus faciles à rechercher et gérer si ces objets sont
identifiés par un
identifiant (non-ambiguë)
(globalement unique), de préférence un
URI (Uniform Resource Identifier)
- URL (Uniform Resource Locator)
ou URN (Uniform Resource Name).
Les étiquettes RFID permettent d'associer un identifiant unique à un objet physique, et donc d'associer et de retrouver facilement des informations sur cet objet, y compris son emplacement. L'internet des objets réfère au réseau mondial des objets identifiés et à leurs interactions.
L'identification des sources d'information est également souvent
nécessaire
1) pour éviter le spamming et la diffamation, et
2) pour permettre une certaine confiance dans le contenu des informations
ainsi que leur gestion sécurisée, la distribution des tâches et la coopération (détails plus loin).
Cependant, même lorsque cela nuit à la collaboration, toute personne a le
droit de préserver sa vie privée
ou de maintenir certaines informations
confidentielles.
Permettre de publier des informations
anonymement
peut aider la coopération, comme par exemple dans le cas des
"tireurs d'alarmes" [whistleblowers].
Ainsi, un groupware devrait permettre la publication de toute information qu'un
logiciel ou un tiers identifié peut attester n'être ni un spam ni de la
diffamation.
Idéalement, un groupware devrait
1) permettre aux gens d'associer à des objets ou des groupes/type d'objets
des politiques de contrôle
d'accès/usage/sécurité
précises, et
2) appliquer ces politiques.
De nos jours, même les outils les plus "orientés sécurité" ne
permettent pas à leurs utilisateurs de spécifier des politiques de
contrôle d'accès/usage "fines"
et de les associer à des objets d'information.
Le projet PRIME reste l'un des plus avancés sur ce sujet
(sujet d'exposé, en même temps que le
serveur de réseaux social sécurisé Diaspora).
Règle sur l'usage d'objets précis et de métadonnées: pour toute tâche liée à la coopération, plus un protocole/outil de coopération permet de représenter et d'exploiter des objets d'information fins et des méta-données précises (représentations de connaissances, politiques de contrôle d'accès/usage, etc) sur ces objets, mieux c'est.
Sécurité:
sûreté (protection contre des
événements indésirables) et
fiabilité
(capacité de maintenir des fonctions), même contre des agents volontaires.
Cela implique de maintenir la
disponibilité,
l'intégrité et la
confidentialité de certaines
informations, procédures ou machines. Cela implique également d'obliger la
responsabilité d'au moins certains
types d'actes, e.g., la lecture ou écriture de certains types d'informations.
Préservation de la vie privée: sécurité + anonymité (i.e., non seulement le contenu ou la nature de certaines informations ou actes est protégée, mais leur existence aussi; ainsi, l'identité des personnes liées à certaines informations ou actes ne peut être connue que par des personnes autorisées; les autorisations doivent idéalement ne pouvoir émaner que des personnes elles-mêmes).
Notion de "consensus" en tant que problème de sécurité informatique distribuée
(pour la tolérance aux pannes):
méthode à utiliser par un groupe de noeuds d'un réseau pour
prouver qu'ils sont accessibles et non corrompus, est d'arriver à fournir
indépendemment une même réponse à une question (ou, en d'autres
termes, "parvenir à un accord sur une seule valeur"). Le problème
lié à cela est "quel protocole utiliser pour y parvenir ?".
Ce problème est impossible à résoudre lorsque
i) l'un des noeuds/processus se bloque, et
ii) les processus communiquent par envoi de messages, n'ont pas d'horloge
commune et fonctionnent à des vitesses arbitrairement différentes.
Cette notion de "consensus" est peu liée à celle de
"consensus pour la prise d'une décision", qui est la notion à laquelle le terme "consensus" réfère dans le reste de ce document.
Séparer l'information (son contenu) de sa présentation (multimédia): pour
- faciliter les changements de présentation par les programmeurs et les
utilisateurs,
- faciliter l'exploitation automatique de l'information.
Principaux outils actuels:
- des schémas/modèles/langages pour décrire des structures
(e.g., XML), et
- des schémas/modèles/langages pour décrire des présentations
(e.g., CSS, XSLT).
Lorsqu'utilisés directement, les langages de description de structures de documents, tels XML, ne permettent de représenter qu'une fraction très faible de la sémantique de l'information et ils ne permettent pas de la représenter d'une manière qui passe à l'échelle. En effet, comme ils utilisent une structure d'arbre au lieu d'une structure de graphe, ils ne permettent pas - ou n'encouragent pas - une représentation explicite de relations sémantiques entre objets d'information. Le plus souvent, seules des relations "sous-partie" et "attributs-de" sont représentées, ce qui conduit à des choix arbitraires, e.g., un objet "employé" doit être représenté comme sous-partie d'un objet "entreprise" ou inversement. Ce sont les raisons pour lesquelles le W3C a proposé le modèle RDF quelques années après avoir prososé XML.
Si un langage de représentation des connaissances (LRC),
basé sur une logique suffisamment expressive (e.g., OWL pour le W3C),
est utilisé pour représenter
(une partie du/des sens) de l'information,
- les représentations peuvent être traduites dans différents langages
(ou langues) formels ou informels,
et selon différentes techniques ou paramètres permettant des
personnalisations,
- des déductions automatiques peuvent être effectuées pour faciliter
la recherche des connaissances,
leur partage et leur exploitation
(e.g., pour résoudre des problèmes et prendre des décisions).
Une question classique
lors de collaborations dans des circonstances inhabituelles (e.g., les
opérations de sauvetage après l'ouragan Katrina) est que des
personnes différentes (e.g., les personnes administratives et les
pompiers) n'ont pas le temps de rendre
explicites leurs différents "contextes de travail" (e.g., terminologies,
objectifs, problèmes, délais, niveaux de stress) et donc ne se
comprennent pas et prennent des décisions incorrectes.
Pour préparer de futures collaborations, un outil pour la collaboration doit
pouvoir aider les gens à représenter et relier leurs différents
contextes de travail (terminologie, localisation, météo, ...).
Ensuite, via des techniques d'inférence, des outils de collaboration
peuvent/pourraient être utilisés pour
1) concevoir et tester des scénarios,
2) comparer et organiser des informations provenant de sources diverses, et
3) détecter des redondances,
des erreurs de raisonnement,
des incohérences, des interprétations erronées,
l'usage d'expressions trop vagues ou inutilement agressives, etc.
Pour faciliter la coopération entre programmeurs - e.g., pour la conception d'un logiciel ou sa maintenance (qui prend environ 75% des coûts d'un projet informatique) - des facteurs importants sont la clarté et le degré d'abstraction/modularité (et donc d'adaptabilité) du code. Pour améliorer ces facteurs, un maximum de conventions de programmation et de bonnes pratiques de programmation (dont voici un ensemble minimal) doivent être suivies systématiquement. Bien que toutes ces pratiques améliorent la clarté du code, certaines sont seulement "présentation orientée" (les pratiques liées à un style de programmation) tandis que d'autres sont des modèles de conception (e.g., la séparation du contenu et de la présentation) ou des modèles architecturaux.
Une bonne interaction homme-machine (et donc interface homme-machine) (IHM) [HCI] est importante pour soutenir le partage d'informations et les autres tâches de collaboration.
Principes de conception d'interface avec l'utilisateur:
structure, cohérence, simplicité, visibilité, rétroaction,
tolérance, réutilisation ... Il y a
d'autres principes de conception d'affichage.
Le W3C se concentre sur les critères de
mobilité,
d'universalité (internationalisation) et
d'accessibilité.
Un résumé général est le suivant:
prendre en compte les possibilités, limites et problèmes
1) des différents éléments techniques (réseau, langages,
navigateurs, ...) et
2) des utilisateurs (vue, mémoire, compréhension, langues, ...).
Une conception centrée utilisateur
des interfaces, i.e. leur co-conception par l'utilisateur final, est une
bonne idée.
La théorie de l'activité
peut aussi aider la conception d'une interface homme-machine.
Plus important encore, des techniques de
personnalisation doivent être
utilisées pour
1) proposer différents modèles basés sur des groupes/profils,
2) proposer des recommandations basées sur les comportements passés
de l'utilisateur ou basées sur des préférences d'autres
gens (filtrage collaboratif), et
3) permettre aux utilisateurs d'adapter l'interface directement.
Corollaire de la règle sur "l'usage d'objets précis et de
métadonnées":
plus les éléments de l'IHM (i.e., de la présentation) et du contenu
sont séparés, plus ils sont fins, adressables et
précisément représentés (organisés),
plus il est possible de permettre leur personnalisation par chaque utilisateur.
Pour réellement supporter la coopération, un logiciel doit fournir une
liste organisée de paramètres de présentation et un
langage adapté pour la présentation.
La caractéristique la plus importante d'une IHM est que tous les objets liés à un objet particulier soient facilement accessibles à partir de lui.
Donc, idéalement, chaque objet "intéressant" doit pouvoir être
sélectionné et sa sélection par un utilisateur conduire à un
menu contextuel
(e.g., via un menu pop-up) permettant à l'utilisateur
d'explorer, de sélectionner et d'ajouter/modifier tous ses objets reliés, e.g., ses propriétés de présentation, des objets informationnels et les actions qui peuvent être faites sur cet objet ou via cet objet
(pour les objets reliés qui n'ont pas trait à la présentation,
les modifications doivent être sans perte, comme précisé dans la
section 2.6.4).
Dans des éditeurs de documents structurés bien
conçus, cela est possible mais l'ensemble des objets reliés est
limité à ceux identifiés par les schémas de structure,
de présentation et d'interaction/événement associés au
document en cours d'édition.
Pour un meilleur partage/recherche des connaissances et une meilleure
coopération, les objets doivent être représentés dans une
base de connaissances (BC), et donc, le menu contextuel associé à
un objet sélectionné devrait permettre l'exploration de la BC à
partir du point d'entrée constitué par cet objet.
Chose [thing]: tout ce à quoi quelqu'un peut penser est une chose.
Une partition possible des choses est celle distinguant
les situations (processus, états, évènements)
des entités (ce qui n'est pas une situation,
e.g., un objet physique, un objet d'information,
un attribut, un concept, etc.).
Objet (d'information) [(informational) object,
resource]: référence
à une chose ("ressource Web" si c'est une chose référable par un
URI), donc
- soit un symbole (référence qui n'est pas une description), e.g.,
un terme particulier (i.e., une chaine de caractères, e.g., "bird"),
un élément graphique (e.g., un icône, une flèche,
la séparation entre 2 colonnes d'une table),
un son particulier, ... ;
- soit une phrase
[(declarative) sentence or
(logic) statement,
not proposition]: une
combinaison de symboles décrivant une chose; en d'autres termes, une
description
non encore affirmée/pensée/crue et donc ni vraie ni fausse.
Une phrase peut d'ailleurs
être un paramètre d'un opérateur de recherche.
À part les quantificateurs (exists, forall, ...),
tout objet a une source associée,
e.g., son (groupe de) créateur(s), son interprète
ou le fichier qui contient la déclaration/définition de l'objet.
Dans les exemples des deux pages suivantes, ces sources ne sont
pas précisées (i.e., elles sont implicites).
Objet lexicalement formel: objet (d'information) lexicalement unique dans les fichiers où il est déclaré ou utilisé. Un URI est un objet lexicalement formel car c'est un terme unique à l'échelle du Web (c'est un "identifiant global" dans un format standard du Web). Une façon de rendre un terme lexicalement unique est de le préfixer ou postfixer par un identifiant de sa source. E.g., dans les LRCs du serveur de connaissances WebKB, pm#bird réfère à un objet dont la source est identifié par pm (qui peut être une abréviation pour Philippe Martin, l'auteur de ce document). pm#bird réfère à sens particulier du mot "bird" pour pm.
Objet (sémantiquement) formel: objet dont la source a déclaré qu'il avait un sens unique, en utilisant un LRC et/ou en lui donnant une définition précise.
Terme formel [formal term]:
terme déclaré ou défini comme ayant un sens unique par sa source.
Une URI est un terme unique à
l'échelle du Web (i.e., c'est un "identifiant global") et dans un
format standard. Toutefois, un URI n'est un terme (sémantiquement) formel
que si son créateur a précisé à quelle chose unique cet URI réfère,
e.g., à un document unique ou bien l'objet que ce document décrit.
Un terme formel réfère
- soit à un individu (un objet qui ne peut avoir d'instance;
les types qui ont pour instances des individus sont des types du 1er ordre),
e.g., pm#Paris_capitale_de_la_France ou toute instance d'un type de relation
- soit à un type de concept ("classe" en RDFS), e.g.,
pm#capitale_de_la_France et
un (représentant d'un) des sens du mot "bird",
- soit à un type de relation, e.g., pm#parent et pm#auteur,
Terme informel: mot (ou expression non quantifiée) lexicalement ou
sémantiquement ambiguë, i.e., ayant plusieurs sens.
Dans les langues naturelles comme l'anglais, la plupart des mots sont ambigus.
De plus, au moins à l'oral, le contexte est souvent pris en compte pour omettre
des précisions, e.g., le mot "chambre" est souvent utilisé sans
préciser s'il s'agit d'une chambre d'hôtel, funéraire,
d'enregistrement, d'appareil photographique, etc.
Dans les LRCs, les termes informels sont souvent représentés entre
double quotes. Par exemple, dans les LRCs de WebKB, "bird" et en#"bird",
réfèrent respectivement à la chaîne de caractères
"bird" et au mot anglais "bird".
Dans le cadre de ce cours, les doubles quotes doivent être utilisées
pour encadrer les objets informels.
Quantificateur de la logique du premier ordre:
i) quantificateur existentiel (-> "il existe", "au moins un", "1..*"),
ii) quantificateur universel (-> "quelque soit", "chaque", "tout").
Quantificateur numérique:
i) individuel (e.g., "2", "au moins 2", "entre 2 et 35"),
ii) statistique (e.g, "35%", "au moins 60%").
Définition: contrairement à une observation avec un quantificateur universel, une définition n'est ni vraie ni fausse, elle ne fait que définir un terme (voir l'exemple page suivante).
Langage de représentation de connaissance (LRC):
langage permettant d'écrire des "représentation de connaissances",
i.e., des phrases ayant une interprétation dans une logique.
Un LRC a généralement un seul
modèle de données (modèle structurel) (qui décrit
les composants du langage et comment ils peuvent s'agencer) et
une seule notation textuelle ou graphique (syntaxe permettant d'écrire
des phrases textuellement ou graphiquement).
Une notation a une grammaire permettant de décider si une phrase est
structurellement correcte ou pas.
Tout modèle structurel et notation de LRC a une interprétation dans
une logique.
Il peut y avoir de nombreuses notations pour un même modèle ou une
même logique.
Ci-dessous, 3 exemples de "phrases affirmées" équivalentes, en
En [English], en LP (logique des prédicats) et dans les LRCs
CGLF (Conceptual Graph Linear Form), FE (Formalized English),
FL (For Links), N3 (Notation 3),
KIF (Knowledge Interchange Format) et R+O/X (RDF+OWL linéarisé avec XML).
Ces exemples permettent d'illustrer et d'expliquer oralement l'usage de
quantificateurs et de définitions,
ainsi que plusieurs notions liées aux "relations sémantiques
(entre "noeuds conceptuels/sémantiques").
La notion de "relation sémantique" est précisée plus tard.
Si vous souhaitez d'autres exemples, cliquez ici.
Les parties en italique sont optionelles (elles ne sont utilisées que pour la lisibilité).
Également pour une question de lisibilité, les sources des termes et des
phrases ne sont pas précisées
sauf pour le terme pm#blue_man et les termes venant de OWL ou de RDF.
1) En : Tom (a man) owns a red hat and a coat. LP : ∃h hat(h) ∧ ∃r red(r) ∧ ∃c coat(c) ∧ owner(h,Tom) ∧ color(h,r) ∧ owner(c,Tom). CGLF: [man: Tom]- { <-(owner: *)<-[hat: *]->(color)->[red: *]; <-(owner)<-[coat] }. FL : the man Tom owner of: (a hat, color: a red), is owner of: a coat; FL : Tom instance of: a man, owner of: (a hat, color: a red) (at least 1 coat); FE : The man Tom is owner of a hat with color a red, and is owner of a coat. FE : The man Tom is owner of a hat that has for color a red, and is owner of a coat. N3 : [a hat; color [a red]] owner [Tom a man; owner [a coat]]. N3 : a hat; color [a red]; owner [Tom a man; owner [a coat]]. KIF: (exists ((?h hat)(?r red)(?c coat)) (and (instance man Tom) (owner ?h Tom) (color ?h ?r) (owner ?c Tom))) R+O/X: <hat> <color><red/></color> <owner> <man rdf:ID="Tom"><owner_of></coat></owner_of> </man> </owner> </hat> <owl:ObjectProperty rdf:ID="owner_of"><owl:inverseOf rdf:resource="owner"/> </owl:ObjectProperty> 2) En : (It appears that) all birds fly. //-> observation/belief (can be false) LP : ∀b bird(b) ∧ ∃f flight(f) ∧ agent(f,b). CGLF: [bird: @forall]<-(agent)<-[flight]. FL : every bird agent of: a flight; FE : every bird is agent of a flight. N3 : @forAll :b . {:b a bird} => {:b agent of a flight; place :s}. KIF: (forall ((?b bird)) (exists ((?f flight)) (agent ?f ?b))) 3) En : By definition of the term "bird" by pm, birds fly. //definition -> neither true nor false CGLF: pm#bird (*x) :=> [pm#bird: *x]<-(agent)<-[flight]. FL : any pm#bird agent of: a flight; FE : any pm#bird is agent of a flight. N3 : pm:bird rdfs:subClassOf [a owl:restriction; agent of a flight]. KIF: (defconcept pm:bird (?b) :=> (exists ((?f flight)) (agent ?f ?b))) R+O/X: <owl:Class rdf:about="±bird"> <rdfs:subClassOf> <owl:restriction><agent_of><flight/></agent_of> </owl:restriction> </rdfs:subClassOf> </owl:Class> <owl:ObjectProperty rdf:ID="agent_of"><owl:inverseOf rdf:resource="agent"/> </owl:ObjectProperty>
Commande dans une BC: affirmation d'une phrase dans une BC, ou bien
requête dans une BC (pour obtenir une information ou
l'exécution d'un processus).
Objet sémantique: objet dont le ou les sens ("le sens" si l'objet est
formel) a été au moins partiellement défini (par rapport à
d'autres objets) via des "relations sémantiques" avec un LRC.
E.g., compte-tenu de la définition des relations sémantiques pm#subtype
(rdfs#subClassOf) et rdfs#instanceOf,
si pm déclare pm#domestic_cat comme pm#subtype de pm#cat,
et pm#cat comme pm#subtype (sous-type) de pm#feline,
alors tout individu déclaré comme étant une instance de
pm#domestic_cat est aussi (transitivement) déclaré comme étant
une instance de pm#feline et hérite des propriétés associées
à pm#feline.
Exemples de représentation en FL, un des LRCs de WebKB:
FL : pm#domestic_cat < (pm#cat < pm#feline);
FL :
pm#domestic_cat pm#supertype: (pm#cat pm#supertype: pm#feline);
(Représentation de) connaissance (RC) [knowledge (representation)]: objet sémantique conforme au modèle d'un LRC. Cela sous-entend que les symboles sont reliés par des relations sémantiques et que la manière de les relier a un sens dans une logique, e.g., la logique du 1er ordre.
Relation sémantique: objet sémantique pouvant être utilisé
pour relier des objets formels mais pouvant aussi être utilisée pour
relier des objets non complètement formels.
Dans ce dernier cas, tous les sens de chaque objet sont reliés à tous
les sens des autres objets.
Exemples de classes de relations sémantiques de base:
relations d'équivalence,
généralisation [e.g., logical deduction, supertype, instance_of,
more_general_term],
sous-partie [e.g., sub_process, substance, physical_part],
thème [e.g., agent, object, recipient, instrument], argumentation,
contextualisation spatiale/temporelle/source [e.g., place, duration, date, author].
Cliquez ici pour une liste de types de relations.
Relation lexicale: objet formel ne pouvant être utilisé
qu'entre des symboles informels.
Une relation lexicale n'est donc pas une relation sémantique.
E.g.: homonyme, antonyme, les relations entre chaines de caractères, ...
Méta-phrase: phrase dont au moins un objet est une phrase.
E.g., "John pense que 'il fait beau' ", `Tom#birds_fly = John#"birds fly"´
et "Cette phrase est fausse".
Phrase contextualisée: phrase + méta-phrases contextualisantes associées.
Méta-phrase contextualisante: méta-phrase précisant quand sa
ou ses phrases objets sont vraies.
E.g., `Tom#birds_fly = John#"birds fly"´.
Contexte d'une phrase: toutes les méta-phrase qui directement ou non, la contextualise. Il est souvent difficile/impossible de représenter tout le contexte d'une phrase: une description ne peut souvent qu'être partielle.
Ontologie: ensemble de termes formels avec, associés à ceux-ci et portant sur eux, des définitions partielles/totales et des croyances. Une BC est composée d'une ontologie et d'une base de faits (ensemble de croyances) exprimée grâce aux termes définis dans l'ontologie.
Règles de base pour la représentation de connaissances
(règles à suivre dans tous vos exercices de modélisation) :
1. Une relation binaire de type *rt (e.g., 'subtype' or 'part')
depuis un nœud source *s (e.g., 'feline' or 'at least 80% of car')
vers une destination *d (e.g., 'cat' or 'at most 100 wheel') se lit :
" *s has/have for *r *d ". E.g. :
`feline > cat´ (i.e., `feline subtype: cat´) se lit
"feline has for subtype cat"
(ou "the type feline has for subtype the type cat"),
`at least 80% of car part: at most 100 wheel´ se lit
"at least 80% of cars have for part at most 100 wheels".
Ce dernier exemple peut aussi se lire :
"at least 80% of instances of the
type car have for part
at most 100 instances of the type wheel". Enfin,
conformément à la règle 7 ci-dessous,
`car part: at most 100 wheel´ se lit
"any (instance of) car has for part at most 100 (instance of) wheel(s)".
2. Si *r est suivi de "of" (pour inverser la direction de la relation), il vaut mieux lire
" *s is/are *r of *d ".
E.g., `cat < feline´ (i.e., `feline subtype of: cat´) se lit
"cat is subtype of feline" et `at least 51% of wheel part of: a car´ se lit
"at least 51% of wheels are part of a car".
3. `*st subtype of: *t´ (alias, `*st < *t´) est équivalent à
`any *st instance of: *t´,
i.e., ` `*i type: *st´ => `*i type: *t´ ´ (3ème paraphrase,
informelle cette fois :
"*st est sous-type de *t ssi toute instance de *st est aussi instance de *t").
4. `*t > excl{*st1 *st2}´ <=> `*t > *st1 (*st2 exclusion: *st1)´
(informellement :
*st1 et *st2 sont sous-types de *st et ne peuvent avoir ni sous-type commun,
ni instance commune).
5. Si le nœud destination d'une relation est source/destination d'autres relations,
il faut isoler ce nœud destination et ses autres relations avec des parenthèses
(comme
dans l'exemple du paragraphe précédent) pour que
l'interpréteur du langage puisse
savoir que ces autres relations sont
sur le nœud destination et pas le nœud source.
Similairement, dans une notation textuelle, lorsque 2 relations de même source se
suivent, il faut les séparer par un symbôle (en FL, c'est la virgule ; voir
les exemples).
6. Les noms utilisés dans les nœuds relation/source/destination doivent être des
noms communs/propres (jamais d'adjectif, verbe, ...) au singulier et en
minuscules (sauf pour les noms propres s'ils prennent normalement des majuscules).
7. Les relations qui ne sont pas entre types et/ou des individus nommés
(i.e., pas les relations sous-type/instance mais la majorité des relations)
doivent préciser comment les nœuds source et destination sont quantifiés
Exemples de quantificateurs : "a" (i.e., "there exists a"), "any" (i.e., "by definition, each"),
"every" ("by observation, each"), "most" (i.e., "at least 51%"), "at most 20%",
"0..20%", "at most 20", "0..20", "between 2 and 3", "2..3".
Toutefois, si le quantificateur du nœud source est 'any' - i.e., s'il s'agit d'une
définition -
celui-ci peut être omis : c'est le quantificateur par
défaut pour un nœud source.
Pour le nœud destination, 0..* est le quantificateur par défaut. Donc :
`car part: wheel __[any->0..*, 0..*<-any]´
=> (`any car part: 0..* wheel´ <=>
`car part: 0..* wheel´)
8. Si vous hésitez entre 2 relations dont une seule est transitive, choisissez la
transitive.
Sinon, si vous hésitez entre 2 relations, choisissez la plus basique|générique
(et
utilisez des nœuds concept adéquats pour ne pas perdre en
précision).
Certaines "choses", comme par exemple les concepts mathématiques,
peuvent être entièrement définies. Certaines autres, comme les
démonstrations mathématiques peuvent être entièrement
représentées. Toutefois, la plupart des choses naturelles/physiques
ne peut être que "partiellement définies" (avec des conditions
nécessaires ou suffisantes) ou partiellement décrites (avec des
"croyances" qui ne sont alors que des "interprétations" ou des "modèles").
Pour être utile à - ou acceptée par - le plus grand nombre possible de personnes,
une représentation doit être aussi précise et complète/générale que
possible et potentiellement utile
(→ respect de la vérité et de la complétude pertinente), i.e.,
* doit inclure toutes les informations pertinentes
(e.g., sachant que les "carinate birds" réfèrent aux
"oiseaux qui sont normalement capables de voler", écrire
"any healthy carinate_bird can be agent of a flight; any sparrow is a carinate_bird"
est plus intéréssant qu'écrire "a sparrow can be agent of a flight") ;
* doit être vraie et donc ni "sur-généralisée" ni "sur-spécialisée".
Voici donc quelques exemples de "bonnes pratiques pour la représentation
des connaissances".
u2#study_of_Dr_Doolittle_in_2002#` `every (wn#daylight ?t pm#part of: from 5/10/2001 to 2/12/2002) `every wn#carinate_bird can be pm#agent of a wn#flight with pm#time ?t´ ´ with pm#place wn#France´.
Être précis implique l'utilisation d'un langage ayant une bonne expressivité, au moins celle de "la logique du premier ordre avec des contextes et des quantificateurs numériques". Durant une phase de modélisation des connaissances à des fins de partage des connaissances, la représentation des connaissances ne doit pas être volontairement restreinte ou biaisée pour convenir à une application particulière ou un type particulier d'applications. Ainsi la BC est réutilisable pour d'autres types d'applications. Suivant les contraintes qu'ils ont, les développeurs d'applications peuvent alors choisir et adapter différents types de connaissances à partir de modules réutilisables.
"Plus organisé" signifie: plus de relations (directes ou indirectes) entre
les objets de la BC. Plus organisé implique plus précis.
Un moyen partiel mais efficace d'organiser une BC est
d'intégrer sans perte des ontologies de haut niveau
(plus des ontologies sont intégrées, mieux c'est)
et d'encourager/conduire les utilisateurs à utiliser
(et donc spécialiser ou instancier) les types de concepts et de relations
de haut niveau (plus ils sont utilisés, mieux c'est).
Les types de relations les plus communément utilisés à des fins d'inférence sont ceux d'identité, d'exclusion (négation, inverse, complément, ...), de généralisation (implication-logique, super-type, instance-de, terme-plus-général,. ..), de sous-partie (sous-processus, substance, partie-physique, ...) et d'autres relations transitives (membre-de, ...).
S'il y a un choix à faire entre deux sortes de relations
pour représenter quelque chose, et que une seule des deux est transitive,
cette dernière doit généralement être choisie.
En effet, dans un ordre partiel, un objet a une place unique, ce qui évite
des redondances et facilite la comparaison des connaissances (et donc aussi les
inférences et recherches de connaissances).
Tous les objets de la BC devraient avoir une place (unique) dans au moins sa
hiérarchie de généralisation.
Ce n'est pas possible en utilisant seulement des relations de
généralisation classiques (sous-type-de, instance-de,
implication-logique) lorsque la BC qui des objets informels et des
phrases (semi-)formelles expressives.
Une relation de "généralisation générique"
(ici notée ".>") est donc utile.
La classique relation "sous-type" est notée ">".
Voici un exemple d'utilisation de ".>" et de ">"
dans la notation FL.
"animal related concept" // "...": informal object .> ("animal right" .> (right_of_any_animal :<=> (right owner=> any animal), // ":<=>" full definition instance: (right_of_Garfield .> right_of_Garfield_in_2010), //specialization of an individual > (right_of_every_animal_in_2010 owner=> every animal, > (right_of_Garfield_in_2010 owner=> Garfield))));
Toujours pour éviter les redondances et faciliter la comparaison des connaissances, dans les noeuds relation il est préférable de n'utiliser que des types de relations basiques et binaires. Toutefois, si le langage utilisé le permet, il est acceptable d'utiliser des types de concept dans les noeud relation. Ceci permet d'éviter de déclarer des types de relations et donc de dupliquer des parties de la hiérarchie de types de concept. E.g., dans l'expression FE `a car with wn#color a wn#red´, wn#color est un type de concept.
À propos des relations de spécialisation (inverse : généralisation)
D'un type (terme formel) *t à une instance *i :
instance (inverse: 'type').
Équivalente à la relation 'member' entre l'ensemble des instances de *t et *i.
D'un type *t à un sous-type *st : subtype|> (inverse: 'supertype'|<).
Toute instance de *st est (aussi) instance de *t".
L'ensemble des instances de *st est inclus dans l'ensemble des instances de *t.
Toute relation associée|"depuis/vers" toute instance de *t est aussi associée à
toute instance de *st (dans les langages O.O., c'est la notion d'héritage :
l'ensemble des caractéristiques individuelles|non-statiques de *t est inclus
dans
celui de *st ; c'est l'inverse pour les instances).
Exercice : comment représenter des caractéristiques "non-héritables"|statiques ?
//By using 'instance' instead of 'subtype'. E.g. :
transitive_relation_type instance: (ancestor > direct_parent);
//Do not try this: transitive_relation > ancestor;
// since this would imply: transitive_relation > direct_parent;
// which is false ('direct_parent' is not transitive)
D'un mot (terme informel) *t à un mot plus spécialisé *st (i.e.,
ayant moins de
sens différents et/ou dont les sens sont plus
précis|informatifs|contraints) :
informal-subterm|.> (inverse: .<).
E.g.:
fr#"ville" .> (fr#"capitale_de_pays" .> (fr#"Paris" .> fr#"Paris_avant_1789"))
D'un mot *m à un type exprimant un de ces sens :
meaning|.> (inverse: name|.<). E.g.: fr#"Paris" .> pm#Paris.
D'une instance à une instance contextualisée dans le temps/espace/... :
.> (inverse: .<). E.g.: pm#Paris .> pm#Paris_avant_1789.
D'une phrase formelle à une spécialisation logique :
<=|> (inverse: =>).
E.g.:
`a cat with place a piece_of_furniture´
> `the cat Tom with place a chair that has for color a red´
D'une phrase (formelle/semi-formelle/informelle) à une spécialisation lexicale
(possiblement plus formelle, jamais moins) : .> (inverse: .<). E.g.:
"birds fly" .> (`any "bird" is agent of a flight´
.> `any bird may be agent of a flight´).
D'une phrase à une correction spécialisante: corrective_specialization.
E.g.:
pm#` mp#"birds fly"
corrective_specialisation:
pm#"any non-handicaped carinate_bird is able to fly"
´
Les relations d'argumentation (preuve, objection, argument, exemple ...) ne sont généralement pas transitives et ont donc tendance à conduire à des structures "spaghetti" qui aident peu la recherche des connaissances et les inférences. Les relations d'argumentation ne doivent être utilisées que lorsque ce qui doit être représenté ne peut l'être (au moins partiellement) d'une manière plus précise et organisée, typiquement via des relations de spécialisation ou de sous-processus. Si cela est nécessaire, des relations d'argumentation peuvent alors être utilisées dans le contexte externe de ces relations de spécialisation ou de sous-processus.
Pour les mêmes raisons et également pour normaliser les structures d'argumentation, au lieu d'utiliser des relations de type pm#objection, il vaut mieux utiliser des relations de type pm#corrective_specialization ou pm#corrective_generalization, avec des relations de type pm#argument dans leurs contextes externes. Ainsi, l'objection est indirectement affirmée et en plus une correction est donnée via une relation transitive et un argument est donné pour cette correction. Cette correction et cet argument vont faciliter l'acceptation de l'objection et peuvent être eux-mêmes des noeuds source de relations de correction.
Exemple de "discussion structurées" (structure d'argumentation multi-sources) dans la notation FL.
"knowledge_sharing_with_an_XML-based_language is advantageous" .< ("knowledge_sharing_with_an_XML-based_language is possible" .< knowledge_sharing_with_an_XML-based_language __[pm] ) __[pm], argument: – "XML is a standard" __[pm] – ("knowledge_management_with_classic_XML_tools is possible" corrective_specialization: "structural_knowledge_management_with_classic_XML_tools is possible" __[pm, argument: "classic XML tools only manage structures, not semantics" __[pm] ] ) __[pm], argument: "the use of URIs and Unicode is possible in XML" __[fg, objection: "the use of URIs and Unicode can easily be made possible in most syntaxes" __[pm#tbl#] ], objection: – ("the use_of_XML_by_KBSs implies several tasks to manage" argument: "the internal_model_of_KBSs is rarely XML" __[pm] ) __[pm] – ` "an increase of the number of tasks *t to_manage" has for consequence "an increase of the difficulty to develop software to manage *t" ´ __[pm], objection: – "knowledge_sharing_with_an_XML-based_language will force many persons (developers, specialists, etc.) to learn how to understand complex_XML-based_knowledge_representations" __[pm] – ("understanding complex_XML-based_knowledge_representations is difficult" argument: "XML is verbose" __[pm] ) __[pm];
Conflit (sémantique) implicite entre deux phrases affirmées: incohérence ou redondance partielle/complète entre ces phrases,
qui n'a pas été rendue explicite via une relation de "correction".
Pour comparaison, voici deux exemples de conflits explicites (et donc
résolus) entre deux croyances:
u2#` u1#`every bird is agent of a flight´ has for pm#corrective_specialization u2#`most healthy flying_bird are able to be agent of a flight´ ´. u2#` u1#`every bird can be agent of a flight´ has for pm#corrective_generalization u2#`75% of bird can be agent of a flight´ ´.
Les conflits entre des définitions provenant de différentes sources n'indiquent pas qu'une des définitions est meilleure que l'autre (car les définitions ne sont ni vraies ni fausses) mais indiquent qu'une des sources (i.e., un des auteurs de ces définitions) a mal compris la signification d'un terme défini par une autre source et donc que ces sources parlent de choses différentes et qu'elles devraient utiliser des termes formels différents.
"Protocole de coopération" minimal de haut niveau pour l'ajout/fusion sans-perte d'une phrase affirmée S1
créée par un utilisateur U1, dans une BC:
Un protocole minimal similaire peut être utilisé pour la suppression sans perte d'une d'une phrase affirmée. Les termes peuvent être ajoutés ou supprimés via l'ajout ou la suppression de phrases affirmées.
Si deux BCs sont développées plutôt indépendamment ou si une
fusion de deux BC est une nouvelle BC "indépendante" (i.e., dont les objets
ne sont pas reliés à ceux deux premières BCs),
les objets des BCs sont mutuellement peu reliés entre eux
et il y a des "conflits" implicites entre eux.
Il est difficile de résoudre ces conflits et de relier ces objets entre eux,
que ce soit manuellement ou automatiquement. Il est donc difficile
i) de rechercher, fusionner/aligner et exploiter ensemble les contenus
des BCs, et
ii) de faire en sorte que des outils ou des groupes utilisant ces KBs
travaillent ensemble.
La plupart des outils (semi-)automatiques liés au Web sémantique (et donc aussi au Web 3.0) sont destinés à atténuer la difficulté de recherche, comparer et fusionner des ontologies développées (semi-)indépendamment. Ces outils sont utiles, mais ils n'intègrent pas leurs résultats dans une BC partagée: leurs sorties sont des nouveaux fichiers/BCs formels dont les objets ne sont pas liés (explicitement, via des relations sémantiques) aux objets des autres BCs (ou de nombreuses autres BCs) sur le Web, en particulier les BCs sources. Ainsi, dans un sens, ces outils contribuent au problème qu'ils atténuent partiellement. En outre, comme les fusions qu'ils effectuent ne sont pas "sans perte", les mises à jour faites ultérieurement sur les fichiers/BCs que ces outils créent ne peuvent facilement être utilisés pour mettre à jour les BCs sources.
La plupart des outils manuels liés au Web sémantique sont des éditeurs de BC privés (qui conduisent donc leurs utilisateurs à créer des BCs plutôt indépendantes entre elles) ou bien des serveurs/éditeurs de BC partagés (e.g., Ontolingua, OntoWeb, Ontosaurus, Freebase et les serveurs wiki sémantique) qui n'ont pas de protocole de coopération entrainant une intégration des connaissances "sans perte d'informations". Par conséquent, ces outils
Le protocole minimal de coopération décrit précédemment
permet aux utilisateurs de créer une BC de manière coopérative
sans avoir à s'accorder sur une terminologie ou des croyances.
Ce protocole est déclenché pour chaque changement dans la base et
doit donc s'appuyer sur un SGBC pour détecter les conflits implicites.
Toutefois, une approche similaire peut être utilisée - bien que de
manière plus asynchrone - chaque fois que des personnes détectent
des conflits implicites dans la BC. Ainsi, une telle approche peut également
être appliquée sur des BC semi-formelles.
Par conséquent, cette approche pourrait être utilisée dans des
wikis sémantiques afin de résoudre leurs nombreux problèmes (dont
leurs problèmes de gouvernance) causés par leur manque de structure.
Beaucoup d'outils du Web 2.0 permettent aux gens d'associer des commentaires à des ressources entières (documents/KBs/services) et de les évaluer en fonction d'un critère (ou de quelques critères) tels que "utilité", "étendue du domaine couvert" et "véracité ". Ces outils permettent aussi souvent de voter sur les annotations et/ou les ressources. Via des statistiques sur les annotations et les votes, ces outils génèrent des "recommandations" et permettent ainsi de la recherche/synthèse collaborative d'informations (également appelée "recherche sociale/concurrente"; sujet d'exposés).
Cependant, la sémantique et l'utilité d'une approche aussi grossière (dans les ressources qu'elle indexe) est limitée et limitante. Voici quelques raisons:
Pour éviter cela, un logiciel aidant réellement la
coopération devrait
Question: comment mesurer la confiance à accorder à un phrase ou à
une personne/source,
comment construire cette mesure collaborativement (i.e.,
comment les utilisateurs d'une BC peuvent-il construire collaborativement une
représentation de la réputation
d'une personne ou d'une phrase) ?
Voici un exemple de modèle de base pour une mesure par défaut destinée à évaluer "l'utilité d'une croyance".
Ce modèle ne précise pas les fonctions à utiliser pour les combinaisons et les pondérations. Le choix d'une fonction particulière est quelque peu arbitraire. Chaque utilisateur devrait donc connaître ces fonctions et devrait être autorisé à créer ses propres fonctions pour satisfaire ses buts ou ses préférences.
Les résultats des "mesures par défaut" doivent être utilisés par des méthodes de "présentation par défaut". E.g., les phrases ayant une très faible valeur d'utilité peut être par défaut affichées avec une police très petite.
Ainsi, les mesures par défaut prenant en compte au moins les
éléments cités ci-dessus devraient inciter les fournisseurs
d'informations à
- être prudent et précis dans leurs contributions, et
- à donner des arguments pour ces contributions.
En effet, contrairement à des discussions traditionnelles ou à des
commentaires anonymes, ici des phrases non réfléchies vont avoir une
influence sur les mesures d'utilité d'un auteur et donc sa réputation.
Cela peut conduire les utilisateurs à ne pas écrire des phrases en
dehors de son domaine d'expertise ou sans préalablement faire de
vérifications. Par exemple, quand une croyance d'un utilisateur est
contredite par un autre utilisateur, l'utilité de son auteur décroit
et il est ainsi incité à approfondir la structure argumentation sur
sa croyance ou à ôter cette croyance de la BC.
Avec le modèle ci-dessus, utiliser un nouveau pseudo lorsque l'on écrit n'importe quoi (diffamations, phrases non réfléchies/vérifiées, ...) mais aucune valeur d'utilité n'est associé à ce nouveau pseudo (et cette valeur pourra même devenir négative si d'autres utilisateurs repèrent la faible qualité des informations fournies via ce pseudo).
Le modèle ci-dessus a l'avantage de ne pas nécessiter de consensus mais peut être facilement adapté pour impliquer un consensus.
Question: découper une BC en modules la rend t-elle plus modulaire ?
(note: plus de modularité doit entrainer plus de ré-utilisabilité)
Vue: ensemble d'informations (dans une BC/BD ou un document) qui peut être spécifiée par une requête conceptuelle, typiquement une expression de chemin. Ainsi, la mise à jour d'un objet dans une vue est simplement l'ajout ou la suppression de relations à cet objet et a les même effets que sa mise à jour dans n'importe quelle autre vue montrant cet objet.
Module autonome [self-contained module]: ensemble d'informations dont les dépendances avec des informations externes sont rendues explicites dans le module via des commandes d'inclusion de module.
Module contextualisé: ensemble d'informations qui comprend - ou à qui est associé - une représentation de son contexte (source, hypothèses, restrictions, buts, ...). Ainsi, une phrase contextualisée est aussi un module contextualisée.
Module conteneur: module stocké dans un conteneur d'informations tel
un fichier ou un serveur de BCs. Une BC entière est un module conteneur et
peut être composée de sous-modules qui sont des modules conteneurs.
L'utilisation de "modules conteneurs qui ne sont pas aussi des vues sur une plus
grande BC" rend difficile pour les gens
1) de savoir quel fichier réutiliser, et
2) d'organiser les objets des différents BCs dans un réseau
sémantique bien organisé.
Ainsi, les modules conteneur conduisent à des redondances implicites et
des incohérences entre ces modules, et donc aux problèmes
répertoriés dans la page précédente.
De plus, pour le partage des connaissances, les approches basées sur les
modules conteneurs, la gestion des versions doit aussi être basés sur
des conteneurs (et donc des fichiers).
Cela conduit à divers problèmes qui ne peuvent avoir de solution
optimale en dehors d'une application particulière.
Une "BC construite coopérativement via une intégration sans perte"
n'a pas de tels problèmes. Par exemple, comment gérer la mise à
jour des identificateurs travers différentes BCs, comment répartir
les connaissances entre modules (i.e., combien et quels types de connaissances
chaque module doit avoir) ?
Il est préférable d'avoir une seule BC partagée et permettre
l'utilisation de requêtes conceptuelle laissant les gens
- utiliser des filtres conceptuels pour ne voir que ce qu'ils veulent voir
lorsqu'ils parcourent la BC, ou
- générer dynamiquement des fichiers à base de modules en fonction
de leurs préférences ou de contraintes d'application.
Si des modules conteneurs sont utilisés à des fins de partage des
connaissances (i.e., pendant la phase de modélisation et non celle de
l'exploitation),
- un module conteneur doit être une "vue" sur l'ensemble de la BC; ainsi,
mettre à jour un module doit être équivalent à directement
mettre à jour l'ensemble de la BC,
- comme n'importe quels autres types de modules dans une BC, les modules conteneurs
doivent être contextualisés ou bien seulement comprendre des
phrases contextualisées
- il doit être possible de parcourir et interroger l'ensemble de la BC
de la même façon que si elle n'était pas distribuée en modules conteneurs.
Pour conclure, utiliser ou non des modules conteneurs est essentiellement un
choix d'implémentation ou un choix dépendant des contraintes d'une
application.
Une BC unique est plus modulaire qu'un ensemble de modules conteneurs s'ils
peuvent être générés à partir de la BC et non l'inverse.
Rendre une BC plus organisée - i.e., augmenter le nombre de relations directes
ou indirectes entre les objets de la BC - augmente sa modularité (et sa
précision).
Une BC bien organisée peut ne jamais devenir "trop grosse" pour le partage
des connaissances. En effet, le qualificatif "trop grosse" dépend de
préférences particulières et une BC peut être vue/parcourue
avec un filtrage dépendant de ces préférences.
Question: serait-il avantageux de stocker des objets logiciels dans une
BC construite collaborativement ?
Tous les modèles de conception de logiciels, modèles architecturaux de logiciels et langages de programmation de haut niveau proposent des moyens pour
Cela rend le code plus générique ou modulaire.
La (programmation) logique a l'avantage de permettre de quantifier des objets. Dans la plupart des LRCs et en logique du premier ordre, tous les objets sauf les quantificateurs sont objets de première classe, mais les prédicats ne peuvent être quantifiés. En logique du second ordre, les prédicats du premier ordre peuvent être quantifiés et des quantificateurs peuvent être définis.
Idéalement, les programmes devraient être écrits directement en utilisant un LRC mais c'est clairement difficile. Lorsque les objets logiciels sont très petits ou bien relativement grands (i.e., des instructions ou bien des programmes), les organiser par des relations sémantiques est difficile, surtout lorsque les objets ne sont pas déclaratifs (c'est pourquoi les méthodologies de génie logiciel se concentrent sur le développement et la réutilisation d'objets logiciels génériques et relativement petits mais multi-instructions). Ce problème n'existe pas avec des représentations de connaissance: il est plus facile de relier des phrases indécomposables que les groupes de phrases.
Dans tous les cas, l'utilisation d'une BC construite collaborativement serait intéressante pour stocker une bibliothèque d'objets logiciels. Cela permettrait à des programmeurs d'organiser des objets logiciel (e.g., des structures de données, classes, instructions, règles, procédures, modules) par des relations sémantiques et de les relier à des objets de connaissances plus classiques (i.e., non liés aux logiciels). Cela permettrait alors ensuite à des utilisateurs d'écrire des requêtes conceptuelles pour générer et à assembler des modules logiciels.
Il peut sembler impossible d'utiliser des "modules-qui-soient-aussi-des-vues"
sur une grande échelle sans avoir un système centralisé.
Pourtant, il est possible de combiner
- la centralisation des informations (qui conserve un réseau unique
sémantique,
ce dont le partage des connaissances a besoin) avec
- l'approche basée sur le Web pour des actions distribuées.
A l'échelle du Web, cela impliquerait une BC virtuelle mondiale
composée de BCs réelles (qui seraient des modules-vues, comme
décrit précédemment) créées par des individus ou
des communautés,
sans système central de répartition/retransmission
d'informations/requêtes,
sans restrictions sur le contenu de chaque BC, et
sans que les serveurs de BCs individuels aient nécessairement à
s'inscrire à une super-communauté ou
à un réseau pair-à-pair (P2P).
Pour arriver à cela, il est nécessaire que le choix de la BC qu'un agent décide d'interroger ou de mettre à jour n'ait pas d'importance. Des ajouts, mises à jour ou requêtes d'objet effectués dans une BC doivent être retransmis toutes les autres BCs dont le domaine couvre cet objet. Plus précisément, pour satisfaire les spécifications ci-dessus, pour qu'un serveur de BCcc (BC construite coopérativement) soit un module-vue d'un ou plusieurs BCcc-GV (BCcc global virtuel), il faut que pour chaque terme T stocké dans sa BCcc, ce serveur
Ainsi, via des retransmissions entre serveurs, tous les objets utilisant T peuvent être ajoutés ou trouvés dans chaque nexus pour T. Cette exigence est une adaptation et un raffinement de la 4ème règle de l'approche "Web de données" du W3C: "il faut lier le plus possible de choses d'un module à des choses d'autres modules". En effet, pour obtenir un BCcc-GV, les modules doivent être gérées via des serveurs BCcc et il doit y avoir au moins un nexus pour chaque terme. Une conséquence est que lorsque les domaines de deux nexus se chevauchent, ils partagent les mêmes connaissances communes et il n'y a ni contradictions ni "redondances implicites" entre ces deux nexus. En d'autres termes, chaque BCcc est bien une vue sur une partie du BCcc-GV.
Décision par consensus/délibération:
processus de décision de groupe
qui,
avant qu'une décision soit prise (e.g., via un vote), implique
- des délibérations
(exploration et comparaison des différentes options) et/ou
- des négociations
(dialogue pour parvenir à un accord entre les participants
et par conséquent à la résolution ou l'atténuation des
objections).
C'est une étape obligatoire d'une approche véritablement collaborative
car
aucun système de vote n'est "juste" quand il n'y a pas de
consensus
(section 3.2.2).
Conformément à ce qui est indiqué en section 1.3,
cette étape n'a pas pour but d'inciter
les participants à s'aligner sur une certaine idée/opinion mais à
générer, comparer, évaluer et
sélectionner des idées (il est donc important d'avoir des
règles/outils imposant/facilitant un rapport d'égal à égal entre les membres du groupe).
Toutefois, créer un consensus peut impliquer du
- marchandage ("je suis ok pour ceci si tu es ok pour cela"),
- des compromis, et parfois,
- des sacrifices individuels au profit du groupe.
L'unanimité réfère à
un accord complet de tous les participants.
Un vote unanime ou l'absence d'objections permet de supposer l'unanimité.
Le consensus entre des parties adverses peut s'obtenir via
- une médiateur (partie neutre
faisant des propositions pour l'obtention d'un accord),
- un arbitre (partie neutre
décidant de l'accord),
- un "facilitateur" [facilitator]
(partie neutre structurant les discussions pour aider à un accord).
Négociation distributive/intégrante:
- "distributive" réfère ici à la répartition de quelque chose
entre les participants;
- "intégrante" réfère à l'union des participants pour
réaliser quelque chose ensemble.
Selon cette source et
cette source, il semble que
- les occidentaux ont tendance à considérer la prise de décision et
la négociation comme un
processus de résolution de problème
(par conséquent, ils procèdent étapes par étapes et
considèrent l'accord final comme la somme d'une séquence de
petits accords), alors que
- les japonais ont plus tendance pour voir la prise de décision
comme un moyen de
i) négocier et définir les problèmes à résoudre de
telle sorte que la solution soit impliquée
par la
définition trouvée, et
ii) évaluer les chances d'obtenir une coopération mutuellement
avantageuse à long terme
(il n'y a donc pas/moins d'étapes particulières et les concessions
sont faites sur toutes
les questions à la fin de la
négociation plutôt que à la fin de chaque étape).
Exemples d'applications:
Exemples de techniques:
Sujet d'exposés.
Cliquez sur les liens suivants:
- techniques de résolution de problèmes: 1, 2, 3
- les chapeaux de De Bono
- 10 façons de générer des idées pour la négociation.
Sujet d'exposés.
Sujet d'exposés.
Sujet d'exposés.
Sujet d'exposés.
Sujet d'exposés. Ci-dessous, pointeurs en anglais.
Decision theory: field related to game theory, concerned with identifying the values, uncertainties and other issues relevant in a given decision, its rationality, and the resulting optimal decision. This is a subfield of economics, psychology, philosophy, mathematics and statistics. It is normative or prescriptive, i.e., concerned with identifying the best decision to take (i.e., how people ought to make decisions), assuming an ideal decision maker who is fully informed, able to compute with perfect accuracy, and fully rational.
Decision analysis: application of decision theory to create decision support systems for helping people make better decisions.
Decision support system: methodology or software used to structure information, identify problems, solve them and make decisions.
Sujet d'exposés. Ci-dessous, pointeurs en anglais.
Multi-criteria decision analysis/making (MCDA/MCDM) technique: technique which 1) highlights conflicts between the preferences of different persons on various criteria of various alternatives, and 2) proposes one way to select an alternative (if there are conflicts, different techniques often give different results).
Decision making software (DMS): software integrating decision analysis tools to choose among several alternatives. DMSs are Decision Support Systems.
Sujet d'exposés.
Sujet d'exposés.
3.2. Prendre/prédire des décisions de groupe
Sujet d'exposés.
Voir les sous-sections suivantes et explorer aussi sur Wikipedia diverses formes de gouvernements, dont l'adhocratie.