Figure 7-4: Challenge-response procedure for mutual authentication [Source: FrSt 2004]
Version PDF (pour une impression) : http://www.eurecom.fr/~martinph/PAC-ID/SP1_2secur_annexes.pdf
Plan
Annexe "ASP-2" (sections 2.2, 2.4, 2.5 and 2.6 du rapport [ASP 08])
Annexe "ASP-2.4" - 2.4 Possible solutions for the RFID privacy and security issues
Annexe "ASP-2.5" - 2.5 Review of The ePrivacy and other Data Protection Directives
Annexe "ASP-2.6" - 2.6 Analysis: are The ePrivacy and Data Protection sufficient for RFID?
Annexe "ASP-7" (section 7 du rapport [ASP 08]) - 7 Auditing and certification
Annexe "ASP-7.1" - 7.1 Auditing privacy-friendly software and best practices
Annexe "ASP-7.2" - 7.2 Creating certification seals
Annexe "ASP-8" (section 8 du rapport [ASP 08]) - 8 Incorporating the ePrivacy and other Data Protection Directives in to ASPIRE
Annexe "ASP-8.1" - 8.1 Privacy-friendly algorithms and techniques
Annexe "ASP-8.2" - 8.2 Privacy-friendly practices
Annexe "ASP-8.3" - 8.3 Implementing the ePrivacy and other Data Protection Directives at software level
Annexe "BSI-7.7" (section 7.7 du rapport [BSI 04]) - 7.7 Security precautions
Annexe "BSI-7.8" (section 7.8 du rapport [BSI 04]) - 7.8 Evaluation of the threat situation and discussion of the security
Annexe "EPCarchi-11" (section 11 du rapport [EPCarchi 07]) - 11 Data Protection in the EPCglobal Network
Annexe "EPC-IS-FAQ-23-31" (questions 23 à 31 de [EPC-IS-FAQ 07]) - EPCIS in a Little More Detail
Annexe "EPC-IS-BRIDGE-criticalInfo" (sections 3.2 and 3.3 de [BRIDGE-NetworkConfidentiality 07])
Annexe "PRIME-policies" - Privacy-aware Access Control Policies
Annexe "XRAG2K" - The main features and command set of the XRAG2K tag
Whilst it is not the aim of this document (and the ASPIRE project) to solve all privacy and security concerns posed by RFID, we discuss possible solutions to help the reader understand the issues and scope of the ASPIRE project in regards to the protection of consumers and industry.
As illustrated above by the figure "Conception of the challenges of RFID (and some solutions)", possible solutions for the privacy and security issues are: (a) self-regulation by industry; (b) new legislation; (c) data protection; (d) privacy and security enhancing technologies (PETs); (e) consumer self-protection - e.g. by education etc. A detailed examination of these solutions follows:
Self-regulation by industry: in this approach, industrial players (end-users, technology vendors) engage in a "moral" agreement to respect and protect privacy and security of consumers and other users. This is the easier approach because it requires no new legislation, research and development, or the standardisation of best practices. However, practice has proven the ineffectiveness of self-regulation by industry - e.g. the case of The Internet. Moreover, privacy violations are very difficult to prove due the high fluidity and liquidity of information, which can be copied and transmitted without leaving trace. For this reason, violations of the self-regulatory "code of practice" would be very difficult to prove, and companies with therefore have little incentive to act responsibly.
New legislation: in this approach, the use and applications of RFID are regulated by law. The scope of this ranges from providing sufficient information to consumers, to enforcing the use of privacy enhancing technologies, to mandating the adoption of best practices, to establishing fines or punishment for violators. Some extreme groups are even pressing for a total ban of this technology. However, the formulation of RFID- specific legislation is very difficult due to a number of reasons. Firstly, RFID is a global phenomenon and countries where regulation takes place will have economic disadvantages with respect to countries where a "laissez-faire" approach is preferred. Secondly, any legislation will definitely hinder further innovation. Thirdly, the legislation of such an immature technology as RFID is very challenging because the technology and its full impact are still not fully understood. Finally, the formulation of RFID-specific legislation would stifle and delay ongoing RFID initiatives, and make this revolution lose momentum.
Data protection: many experts are currently discussing the suitability of existing legislation and regulations for the case of RFID, particularly the e-Privacy Directive. However, we believe that the e-Privacy Directive and other related legislation and recommendations are only partially suited for the case of RFID. This is fully discussed in section 2.6.
Privacy and security enhancing technologies (PETs): these are improvements of the RFID technology that feature privacy and security by design and by default. Among these we can mention more secure RFID tags and protocols - e.g. by using encryption; the automatic destruction or disabling of tags at the point of sale; RFID tags that require passwords or are activated through mechanisms that require direct or indirect user consent - e.g. pressing a button; and algorithms that protect privacy and security at software level - the ASPIRE approach. In the field of PETs there is no "silver bullet", and different approaches are required to guarantee privacy and security issues at different levels and/or in different applications; and to various extents.
Despite the fact that there are a number of PETs in existence - either commercial or experimental, most existing RFID technologies and dominant standards and guidelines do not consider privacy and security within their technological proposal. For one, the dominant RFID guiding body, the Auto-ID Centre which subsequently gave place to the ongoing EPCglobal/GS1, seems "stuck" at self-regulation and tag disabling at the point of sale. One possible explanation for this is that this set of standards and guidelines surged from technical and functional needs (from end-users) that did not consider social issues from inception - hence the need to "patch" their developments with the "emergency" option of disabling tags. For the same reason, there is a possibility that the current RFID situation is one of over-standardisation where such dominant standards as EPCglobal are hindering further innovation and therefore the improvement of this technology, particularly on the privacy and security domains. Of course, our statement is speculative so more research in this direction is suggested.
Finally, there is an urgent need to undertake further research in PETs, not only at software level as ASPIRE is aspiring; but also at tag, reader and protocol level. In the end, only PETs have the potential to solve most if not all privacy and security issues associated with RFID.
Consumer self-protection: another option is to educate consumers so everyone knows how to protect his or herself from the perils of RIFD. Consumers could learn to find and remove or disable all RFID tags on their property or groceries, or to block these - e.g. by using "jamming" or other security devices. However, it is clear that this approach is incomplete and unreliable because some vulnerable groups will surely fail to grasp the perils and protecting measures associated with RFID. Specifically, the elderly, children, tourists and technology-unaware people may fail to understand the threats and act upon them.
For this reason, the search for a reliable privacy-friendly and secure RFID approach that works by design and by default is still ongoing, and the debate continues.
At the moment, the most relevant legislative and regulatory approach for the RFID case is the ePrivacy Directive. However, there are other applicable Directives and legislation such as the Data Protection Directive. This section summarises the relevant legislation and its implications for the RFID process and ASPIRE. The relevant Directives are:
The history and details on these Directives are large and complex and unnecessary for this analysis, so we do not elaborate on these. Conversely and as follows, we focus on their main concepts and substance, and on their implications for ASPIRE and the RFID process.
Definition of Personal Data and relationship with RFID
These Directives clearly define the concept of "Personal Data". Particularly, the definition of "Personal Data" is established in the Article 2(a) of the Directive 95/46:
"'Personal data' shall mean any information relating to an identified or identifiable natural person ('data subject'); an identifiable person is one who can be identified, directly or indirectly, in particular by reference to an identification number or to one or more factors specific to his physical, physiological, mental, economic, cultural or social identity".
The definition of Personal Data is essential to our analysis because it determines whether RFID is covered by the Data Protection Directives or not, and determines what can be done in the context of ASPIRE as to protecting the privacy and security of citizens. In general, there is consensus that the ePrivacy and other European Data Protection Directives apply yet not suffice in the case of RFID, although this depends on the specific application. This is because the unique identification code associated with RFID-tagged objects carried by or owned by individuals can be used to indirectly identify them. Moreover, it can also be used to determine object nature (e.g. a specific medicine) and indirectly identify some of the physical, physiological, mental, economic, cultural or social identity factors of the individual. Applications where personal data and item-level tagging are involved seem to fall within the scope of the Data Protection Directives, whereas applications where RFID tags are applied to objects which are not carried or owned by individuals seem to be outside its scope - e.g. the tagging of pallets or cases.
To err on the safe side of the legislation and for the purpose of this analysis and the design, development and implementation of ASPIRE; we assume that all applications involving the item-level tagging of objects with RFID tags fall within the scope of the ePrivacy and other Data Protection Directives, and must therefore be implemented through PETs within ASPIRE's developments.
Data Controller
The concept of Data Controller establishes who collects and processes the data. The Directive 95/46 defines Data Controller as: "the natural or legal person, public authority, agency, or any other body which alone or jointly with others determines the purposes and means of the processing of personal data".
In the case of RFID, the data controller is the user of the tag. This entity determines the purpose of that tag used in combination with the network of readers and other means such as databases and information systems. One complication in the case of RFID is that third parties can access the identity and other information stored in some type of tags, particularly inexpensive passive ones - those proposed for item-level tagging. In these cases the Data Controller has limited control on the access to data, even when these data may directly or indirectly classify as Personal Data.
Consent
The applicable Treaties and Directives set limits within and beyond which the collection and process of Personal Data about an individual requires his or her unambiguous consent:
In the case of RFID the concept of consent is more challenging because some of these devices seamlessly provide information to any compatible reader. For instance, even if the individual fully understands how the technology works, it is not clear what the acceptable extent of consent is. For example, consent to gather and process RFID data related to Personal Data may be limited to a specific shop, to just one transaction, to one day of transactions, or to an entire year of data collection. Similarly, it may be related to one or more applications. As we will see below, ASPIRE considers a definition of consent that is the most restrictive (and therefore the most protective of consumers' privacy and security rights).
Principles of the ePrivacy Directive
The principles of the ePrivacy and other Data Protection Directives most relevant to our analysis are: (1) limitation, (2) quality, and (3) conservation, as established by Art. 6 of the Directive 95/46. A summary of the principles applicable to RFID follows:
Limitation: this principle establishes that Personal Data should be processed for the intended purpose only. Further processing is prohibited. In the case of RFID, this means that any transactions generated by the RFID system (e.g. when tracking and tracking objects in a retail shop), and that could potentially be linked to the Personal Data of the carrier (e.g. the shopper) cannot be used for such other purposes as collecting individual preferences or consumer behaviour at individual level; or registering the property of individuals. It also limits the use of RFID data which could potentially identify a customer to generate unsolicited publicity or promotions.
Quality: all collected data must be relevant for the intended purpose. Data which is not relevant for the purpose should not be collected. In the case of RFID, this means that Personal Data about an individual should not be linked to object data unless strictly necessary. For example, data that identifies a consumer who pays using his or her credit card or who uses his or her loyalty card should not be linked to the identification of the RFID tags on the objects being acquired. Similarly, RFID data produced by tags on objects that have been previously acquired in the same or other shop should not be collected and/or related to other Personal Data of the individual.
Conservation: Personal Data should not be stored and/or processed longer than necessary for the intended purpose. After the purpose has finished, these data have to be deleted. In the case of RFID, this means that any RFID data which could potentially identify the individual (e.g. the identity of tags on his or her shoes), and that must be collected for lawful purposes (e.g. service, warranty or returns) should not be kept for longer than necessary for these purposes (e.g. longer than the warranty or return periods).
Other rights and principles stated by the Directives
Apart from the aforementioned concepts and principles, the ePrivacy and Data Protection Directives establish rights as to the transference of Personal Data to countries with laxer data protection legislation; give individuals the right to access, rectify and delete their Personal Data; and establish especial considerations when data include racial or ethnic origin, political opinions, religious or philosophical beliefs, trade-union membership, or health or sex life.
The design, development and implementation of ASPIRE will incorporate these and other Data Protection principles within its technology and best practices, and so protect consumers and the general public from the privacy and security threats associated with RFID. Sections 4.4 and 8 will elaborate on the implementation of the ePrivacy and other Data Protection Directives in the project ASPIRE.
The Working Party mentioned in section 2.3 concluded that most RFID threats fall within the Data Protection Directives. However, it also recognises that "It should be noted that RFID systems are very susceptible to attacks" and recommends the destruction or disabling of the tag at the point of sale. Moreover, it recommends: "The design of RFID tags, RFID readers as well as RFID applications driven by standardisation initiatives may have a great impact in minimising the collection and use of personal data and also in preventing any unlawful forms of processing by making it technically impossible for unauthorised persons to access personal data."
In this line and concerning RFID, the aforementioned communication on Radio Frequency Identification in Europe: steps towards a policy framework, stated that a number of changes might be needed in the Privacy and Electronic Communications Directive to also embrace RFID applications, as part of the EU Telecom Rules' review. The scope of the ePrivacy Directive is not as wide as the Data Protection Directive's one: the former is limited to "the processing of personal data in connection with the provision of publicly available electronic communications services in public communications networks."
Moreover, in November 2007 a "Proposal for a Directive of the European Parliament and of the Council amending Directive 2002/22/EC on universal service and user's rights relating to electronic communications networks, Directive 2002/58/EC concerning the processing of personal data and the protection of privacy in the electronic communications sector and Regulation (EC) No 2006/2004 on consumer protection cooperation34" was adopted. The proposal, part of a legislative package intended to amend the current framework regulating electronic communications, seeks to introduce a number of amendments in the two mentioned Directives. Concerning the ePrivacy Directive, the text establishes that "[...] the main proposals are as follows: [...] clarifying that the Directive also applies to public communication networks supporting data collection and identification devices (including Contactless devices such as Radio Frequency Identification Devices)". Therefore, this Proposal is aimed to clear up the conditions for RFID to fall within the scope of Directive 2002/58/EC.
However, whilst all current studies and publications have focused on whether RFID- related data can be directly or indirectly considered "personal data" in some circumstances and applications, and therefore whether the Data Protection Directives suffice to cope with RFID threats; most studies have failed to overtly address the perils of RFID beyond the point of sale - e.g. when personal data is not involved and/or RFID is abused by third parties. Specifically, the fact that most RFID numbering schemes (e.g. EPCglobal) reveal product characteristics (e.g. product type), and that these can violate privacy and compromise security even if no personal data is involved, has been systematically overlooked in the RFID analysis. For example, a terrorist could set a "bobby trap" to explode when an RFID-tagged copy of the "Old Testament" is detected; or a snooper can detect RFID-tagged medical implants or confidential medicines on people passing by.
Obviously, since the ePrivacy and other Data Protection Directives were conceived to regulate the use of data between two parties "controller" and "individual", these do not cover the case when privacy- or security-related RFID data (e.g. the identity of privacy- or security-sensitive objects) can be abused by third parties. Furthermore, most RFID tags can be interrogated surreptitiously by any party so the definition of consent loses ground.
Because of this, we believe that the ePrivacy and Data Protection Directives do not suffice to legislate in the case of RFID; although suffices to cope with many of its threats, principally those addressed by the ASPIRE project. At least, our initiative to incorporate the ePrivacy and other Data Protection Directives in ASPIRE is a good start, as explained in the following section.
On-site technical auditing of the implementation of ASPIRE: this involves periodic surprise or planned visits to the facilities in order to study the technical implementation, specifically the configuration of the equipment, environmental and application software, RFID network and configuration of the ASPIRE middleware. On-site visits are necessary to ensure that unscrupulous organisations do not tamper with the online auditing of the system detailed next.
Online technical auditing of the implementation of ASPIRE: to reduce auditing costs and reach many organisations, most of the technical auditing will be performed online, either manually or automatically. For this, ASPIRE adopters should open their RFID-supporting systems to the auditing organisation and allow 24/7/365 connections. Any change in the security of the system must be communicated in advance so the auditing background processes can keep with their work.
Auditing of operational procedures related to the implementation of ASPIRE: the operational procedures related to the implementation of ASPIRE will be audited to verify compliance. This will be performed through on-site visits to end users. Whilst most of these visits will be planned (e.g. annual or bi-annual); some will be surreptitious or surprise visits, more so if the end user has a story of privacy violations or when online audits have revealed recklessness or flaws.
Specialised auditing of technical or procedural modifications made to tailor ASPIRE to specific business needs: since some customers will tailor ASPIRE to their specific needs, a special certification programme will be developed to verify that these modifications have not negatively impacted in the ASPIRE privacy design. Specialised audits are expected to be rare and limited to those business that cannot accommodate their privacy and security practices within the limits of ASPIRE.
The cost of auditing will be covered by ASPIRE adopters, who will benefit from the use of certification seals to ensure their customers that their privacy and security is looked after. This certification seals are described in the following section.
The following table shows a preliminary approach to the tiered classification. This is however subject to change during the project execution as it depends on new findings and developments:
| 0 (no stars) | No privacy considerations - consumers beware! |
| * (one star) | Minimum privacy considerations. Personal data is registered, linked to object data and kept for more than one year. This data might be also sold to third parties for marketing or promotional purposes. |
| ** (two stars) | Little privacy considerations. Personal data is registered, linked to object data and kept for more than one year. This data will not be sold or transferred to other parties. |
| *** (three stars) | Moderate privacy considerations. Personal data is registered and linked to object data, but kept for no longer than one month. This data will not be sold or transferred to other parties. |
| **** (four stars) | High privacy considerations. Personal data is registered but not linked to object data or kept for longer than one month. This data will not be sold or transferred to other parties. |
| ***** (five stars) | Full privacy. Personal data is never collected or traded. |
Table 4: tiered classification of privacy
Upon the conclusion of the project ASPIRE, partners and principally Open Source Innovation will promote the use of these seals and their classification so as to provide consumers with a clear idea of what their privacy rights are when shopping.
The number of stars per organisation and facility depends on their configuration and implementation of ASPIRE. This will be determined during the auditing process, and the stars can be given or taken as audits are more or less successful respectively, or organisation can be fined if they are found in severe breach of their privacy controls and procedures.
Anonymity: this consists of eliminating the pieces of data that identify an individual, so its sensitive data becomes anonymous. Examples of data identifying an individual are his or her social security or identity number, address, phone numbers etc.
Use of pseudonymous or fake data: similar to the above, but replacing identifying data for other random or fake data. To even improve the privacy protection i.e. tracking, a list of rotating pseudonyms can be added.
Blurring: applicable to logical links between transactions such as transaction IDs, timestamps etc. This involves slightly changing this data so the previous relationship is difficult to establish. For example, it may involve randomising timestamps by ±20% to break the original relationship between object transaction and payment transaction.
Separation: this involves the physical separation of pieces of data - e.g. in different file-systems or databases; in order to make difficult the establishment of their relationships. For example, personal data may be kept in a database different than that hosting object and other company data.
Reduction of granularity: this consists of trimming data to reduce the level of detail. For example, the identity of an item-level tag may be trimmed so the item part of the code is removed so the data is only registered at the level of product type. This is more or less how retail shops work nowadays because they do not have a way to identify product at item-level.
Encryption: this involves the use of cryptography, either through private or public keys or other mechanisms. Encryption is well known in ICT and is commonly used for the safe storage and transmission of sensitive data.
Cumulative statistics: this is a simple but very effective mathematical trick to calculate statistics without registering data about individual transactions. For example, to calculate the average price of products sold in a day it suffices to add the total T and count the individual items I. The average will be given by T/I without requiring the storage of all individual transactions. Similar algorithms can be applied to find maximums and minimums, calculate standard deviation and compute other statistical data.
Shuffling: in some occasions transactions of different nature are registered in the same order. This allows putting them together as the logical relationship is still given by the order of registers. For example, even if we blur the relationship between object and personal data, if both transactions are registered in the same order it is still possible to put them together - hence breaching privacy. To avoid this we can use algorithms to shuffle either or both transaction sets.
Cleanup + overwrite: to get rid of old data we recommend cleanup background processes. These will run periodically or upon certain conditions such as arrival of new transactions or triggering of privacy alarms (see below). Moreover, cleanup processes will not just delete data using operating system or API functions: it will overwrite the previous data with dummy data to guarantee proper deletion.
"In memory" processing: this consists of processing as much of the transaction in memory as possible, and writing only the final results. For example, a payment transaction requiring object data such as price and stock levels will perform all necessary calculations in memory within the same transaction, and write the payment only (e.g. without the object data).
Copy + destroy: this involves the transfer of data without leaving a previous copy. For example, backups on data not longer necessary for daily purposes will remove these from the database once the backup is successfully completed and verified. Similarly, successful transactions sent to business partners will remove the original data if this is not longer necessary from a business perspective.
Volatile encryption: this involves encrypting data with a key that will be discarded after a period of time. For example, this can be used to backup personal data meant to be deleted after a certain period of time or under certain conditions. When this time expires or the conditions are met, the system will automatically delete the encryption key, so rendering the data irrecoverable.
Vigilance of personal or sensitive data: every process programmed in ASPIRE will require special electronic "permission" to access personal or sensitive data. This "permission" will be configured, documented and audited when the process is incorporated, and will be automatically marked to require further auditing when it changes. Any other process intending to access this data will trigger a Privacy Alarm as described below.
Filtering of non-related data: ASPIRE will automatically filter out any data which is not related to a valid transaction in the system. For example, the detection of tags which do not belong to the organisation will be ignored.
We will see in section 8.3 how these algorithms and techniques allow the incorporation of the ePrivacy and other Data Protection Directives in ASPIRE.
Customer identification: ASPIRE will incorporate mechanisms to identify and allow individuals to connect online. These mechanisms will be similar to but simplified versions of those used by modern online banking systems, where customer authentication is essential to provide financial data. For this, ASPIRE will incorporate the concepts of customer id and password, and authenticate customers by their username and some randomly selected digits of its password. Failed identification will generate a Privacy Alarm for investigation (see below).
Access and correction of data: linked to the previous point, ASPIRE will provide interfaces so end-users can access and correct or delete their personal data according to the Data Protection Directives.
Support for automatic tag deactivation or privacy mode when available: since there is ongoing research to allow the automatic deactivation of tags at the point of sale and so protect consumers' privacy and security; ASPIRE will incorporate and enforce this functionality when possible.
Numbering of reports and backups: a common source of data leaks are paper reports or backups. These can be printed out and easily taken out of the office, so compromising privacy. The individual numbering of reports and backups allows keeping track of them and hence auditing their correct destruction or storage. For example, all reports which are not longer necessary can be sent to a single person or department in charge of destroying them and informing ASPIRE of this destruction. If any reports or backups have not been reported as destroyed or archived within the normal period of time, the system will generate a Privacy Alarm (see below).
Privacy alarms: these will be triggered when the above algorithms are considered ineffective due to the amount of data or operational characteristics. For example, a Cumulative Statistic with only one record (or with less than a number of records) does not "dilutes" data sufficiently to protect privacy. Similar examples apply to Blurring, Reduction of Granularity, Shuffling etc. Another example is the accidental or intentional interruption of the Copy + Destroy, which may leave two copies of the data where it was initially intended to leave only one. These Privacy Alarms will be sent to the system administrator, privacy manager of the organisation, or auditor of the system for examination and correction if possible.
Privacy manager: ASPIRE will also propose minor organisational changes, in particular the creation of the Privacy Manager who will be responsible for enforcing policies and practices protecting privacy, specifically:
The privacy-friendly algorithms, techniques and practices described above allow the incorporation of the principles in the ePrivacy and other Data Protection Directives. This section explains how these techniques will support this incorporation and make ASPIRE privacy-friendly by design and by default.
Limitation (not processing the collected information for unintended purposes): the intelligence and programmability of ASPIRE, together with the privacy alarms detailed before, will allow limiting the use of personal data for the intended purposes. This is achieved by controlling access of fixed and programmable logic to the database structures where personal data is stored (Encryption and Vigilance of Personal Data). Any new logic must comply with specific business requirements and therefore be properly configured and documented in the system so as to be properly audited by the certification programme. If any programmable logic is changed to access personal data for unauthorised transactions a "privacy alert" will be triggered and the ASPIRE administrator and external auditor will be immediately notified.
Quality (not collecting information that is not essential): ASPIRE algorithms will address data quality by (a) limiting the amount of collected personal data to what is necessary as defined in the configuration of the system; and (b) managing the link between personal and object data so the latter cannot be misused to illicitly identify a person (does not become personal data). Data Quality will be enforced by using:
Conservation (not retaining personal data for longer than necessary): ASPIRE will incorporate "on-the-fly" transactions where the necessary data are kept only for the duration of the transaction and either deleted or "blurred" afterwards. Aspire will also incorporate automatic "cleaning" mechanisms to delete any personal data not longer necessary; and/or trigger privacy alarms requesting its deletion. Conservation will be enforced by: "In memory" processing, Copy + Destroy, Volatile Encryption, and Numbering of Reports and Backups when the data is not longer necessary for the normal operation of the system.
Other principles: ASPIRE will incorporate other mechanisms allowing individuals to identify themselves and access and correct or delete their personal data as required by the Directives. It will also incorporate measures for the protection of personal and object data such as encrypted storage and transmission. These other mechanisms and measures are:
To implement this, ASPIRE's auditing and certification programme will incorporate recommendations for the education of staff dealing with personal and object data, and for the creation of the necessary organisational structures and responsibilities (e.g. the privacy manager).
A detailed list of recommended privacy-friendly best practices to be delivered with ASPIRE is:
When authentication is carried out, the identity of a person or a program is checked. Then, on that basis, authorization takes place, i.e. rights, such as the right of access to data, are granted. In the case of RFID systems, it is particularly important for tags to be authenticated by the reader and vice-versa. In addition, readers must also authenticate themselves to the backend, but in this case there are no RFID-specific security problems.
When the RFID system detects a tag, it must check its identity in order to ascertain if the tag has the right to be part of the system at all. A worldwide and unambiguous regulation for issuing ID numbers, as proposed, for example, in the form of the Electronic Product Code (EPC), offers a certain amount of protection from falsified tags. At the very least, the appearance of numbers that were never issued or of duplicates (cloning) can be recognized in certain applications.
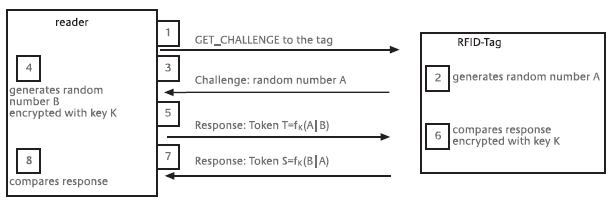
In addition, authentication may take place via the challenge-response system, in which the reader sends a random number or a time stamp to the tag (challenge) which the tag returns in encrypted form to the reader (response). The key used in this case is a jointly known secret by means of which the tag proves its identity. The decisive element in this procedure is the fact that the key itself is never transmitted and that a different random number is used for every challenge. As a result, the reader cannot be deceived by the communication being recorded and replayed (replay attack). This unilateral authentication procedure is defined as a "symmetric-key two-pass unilateral authentication protocol" in ISO Standard 9798.
An attacker would have to get hold of the key which is stored both on the tag and in the backend of the RFID system. In order to do so, it would be necessary to decode the response data that were transmitted in encrypted form, which is a very complex if not almost impossible task, depending on the length of the key. In principle, the key could also be read by physical means from the storage cells of the chip, but this would require very complicated laboratory methods, such as the "Focused Ion Beam" (FIB) technique. In this procedure, an ion beam removes very thin layers (a few layers of atoms) in separate steps so that the contents can be analysed microscopically.
A challenge-response method can also be used for the mutual authentication of reader and tag. In this case, the tag must also be capable of generating random numbers (see Section 7.7.1.3).
The simplest method of authenticating the reader in relation to the tag is to use password protection, i.e. the reader identifies itself to the tag by transmitting the password. The transponder compares this password with the password stored in memory. If both are identical, the tag grants full access to the stored data. Some products grant password protection for selected areas of memory.
In simple systems, all tags contain the same password in a protected area of their memories. In more sophisticated read-only systems every transponder is assigned an individual password by the manufacturer, which is then stored in its memory by means of a laser. Variable passwords are capable of providing better protection, but they only work with read-write transponders. The length of a typical password would be 8, 24 or 32 bits.
Password systems without encryption are regarded as a weak method of identification, because they allow eavesdropping on password transmission via the insecure air interface. In addition, short passwords can be cracked simply by systematic trial-and-error.
Password systems without encryption might be adequate in cases where the tag is addressed just once or where the danger of a password being discovered by spying is already low. If access is needed only a limited number of times, a list of once-only passwords stored in the transponder and in the back-end can also be used instead of a single password.
In contrast to cryptographic procedures, such password systems make few demands on the tags and can be implemented with simple read-only tags.
Improved security against unauthorized readouts is achieved by the hash-lock procedure. In this case, before a tag is written to for the first time, a so-called meta ID is generated from a key as a pseudonym for the tag. This is done with the aid of a hash function, the calculation of which is practically irreversible, and the meta ID is stored in the tag. From that moment on the tag is locked, that is to say, it reacts to the signals of a reader solely by transmitting the meta ID. To unlock the tag, the reader must retrieve from a backend database the key that belongs to the meta-ID and then transmit it to the tag. The tag applies the hash function to the key it has received and checks whether the result is identical with its meta ID. If this is the case, the reader is authenticated and the tag allows access to its data.
It would be almost impossible for an attacker to calculate back to the original key. Therefore in many practical deployment areas a meta ID is sufficient protection against unauthorized readout. However, during transmission via the air interface the secret key belonging to a meta ID can be spied out by an attacker who can later deceive the tag into recognizing a reader as authorized (replay attack). The hash procedure can be implemented for transponders even without using sophisticated cryptoprocessors [Source: Weis 03], so that this procedure can be used even for inexpensive transponders.
Maximum protection against unauthorized access to the tags is provided by authentication procedures with encryption according to the challenge-response principle (strong cryptographic procedures) mentioned above. However, these procedures presuppose that the tag can not only execute cryptographic algorithms but can also generate random numbers. In the case of tags which fulfill these requirements and can therefore check the authorization of the reader at a high security level, it is not worthwhile to make compromises when the reverse problem occurs (authentication of the tag to the reader), because the processing capacity of the reader or of the backend does not constitute a bottleneck. Consequently, in the case of high-performance transponders strong mutual authentication procedures are appropriate (see Section 7.7.1.3.).
ISO Standard 9798 defines various challenge-response procedures for strong authentication in the case of contact smart cards and RFID systems, including mutual authentication according to the "three-pass mutual authentication protocol".
When a tag receives a "get challenge" command from a reader, it generates a random number A and sends it to the reader. The reader in turn generates a random number B and with it and the random number A generates an encrypted data block (token T) on the basis of an encryption algorithm and a secret key K. The data block is then returned to the tag. Since both sides use the same encryption algorithm and since the key K is stored on the tag, the tag is capable of decrypting the token T. If the original random number A and the random number A', which has now been decrypted, are identical, this proves the authenticity of the reader. The procedure is now repeated in order to authenticate the tag to the reader. In this case, a second token S is generated in the tag and is transmitted to the reader. If the decrypted random numbers B and B' are identical, then the authenticity of the tag vis-à-vis the reader has also been proved.
In this procedure no secret keys are ever transmitted via the insecure air interface. Instead only encrypted random numbers are used, which gives a high degree of protection against unauthorized access. Nor can recording and subsequently replaying the initializing sequence (replay attack) gain access to the tag or the reader.
Apart from the authentication procedures based on symmetrical cryptography, which are described here, procedures based on asymmetrical cryptography are also conceivable for use within RFID systems.
Figure 7-4: Challenge-response procedure for mutual authentication [Source: FrSt 2004]
Encryption of the data being transmitted is one method of protecting against anyone eavesdropping on communication via the air interface. Encryption is closely linked with authentication. If a transponder is designed for strong cryptographic procedures, not only strong mutual authentication but also secure encryption of the data that are subsequently transmitted can be achieved. In particular, the three-pass authentication procedure described above can be used to generate a joint temporary key (session key) from the random numbers of the initialization sequence to encrypt the data which will subsequently be transmitted.
If, however, the transponder does not support strong cryptographic procedures, only weak authentication is possible. For the same reasons, reliable encryption of subsequently transmitted data is then not possible either.
The most effective protective measure against an attack involving eavesdropping at the air interface is, however, not to store any contents on the tag itself and instead to read only the ID of the tag. The data associated with the tag are retrieved from a backend database. This measure, which is most often recommended in the technical literature and which is assumed by EPCglobal [EPC 04], offers the additional advantages that less expensive tags can be used, the memory for the associated data in the backend is practically unlimited, and the usual procedures for data management and IT security can be employed.
The problem of protecting the air interface against eavesdropping is thus limited to the authentication procedure and the transmitting of the ID number. The authentication problem is solved by applying the authentication procedures (see Section 7.7.1.), and eavesdropping to obtain the ID does not constitute a threat in many applications, for example in a production process. In the case of widespread applications, however, eavesdropping on the ID may threaten the location privacy of the persons carrying tagged items and may thus raise data protection problems. In such situations countermeasures such as eavesdropping-proof anti-collision protocols and pseudonymizing of the tags could offer a solution (see the following Sections).
For applications where relevant contents have to be stored on the tags themselves, only strong encryption procedures can provide reliable protection against eavesdropping.
With anti-collision protocols based on a binary tree search (tree walking) (see Section 5.2.4), the ID numbers of the tags can be deduced from the signals of the reader, even from a considerable distance [Source: LLS 00]. For this reason, alternatives to the tree-walking procedure have been suggested which would preclude the extraction of ID numbers through eavesdropping on the downlink (data transmission from reader to tag).
Neither of the measures mentioned have any influence on the possibilities that exist for obtaining ID numbers through eavesdropping on the uplink (data transmission from tag to reader). Their usefulness is derived from the fact that, because of the low transmitting power of the passive transponder and because of the superimposition of the strong signals from the reader, the uplink can normally only be monitored at a shorter distance than the downlink. However, this evaluation is called into question by more recent investigations conducted by the BSI, at least for inductively coupled transponders in the 13.56 MHz range [Source: FiKe 04].
This modification of the tree-walking procedure was suggested by Weis et al. [Source: WSRE 03]. Instead of actively "calling out" in clear text the next branch in the binary tree, the reader merely transmits to the tags in the reading field the request for them to transmit the next bits of their ID numbers. The reader interrogates the areas of corresponding bit sequences of all tags in descending order until a collision occurs at point i. At this point the reader branches off the query of the sub-trees by means of a SELECT command. Then, in contrast to normal tree walking, it is not the entire already known section of the address space that is transmitted, but rather an XOR value made up of the current bit at point i together with the preceding bit. The tags in turn form an XOR value out of this particular value and their own bit and compare the result with the next digit of their ID number. If there is a match, they are selected and transmit the next bit. An attacker operating from a distance, who can only eavesdrop on the downlink from the reader to the tag, does not find out the complete ID number. Those areas of the ID numbers where no collision occurs remain hidden to him, so that the attacker cannot find out the selected sub-tree, nor can he, by reversing the XOR function, ascertain the bit values transmitted by the reader.
In contrast to normal tree walking, this procedure cannot be implemented with read-only tags, because a dynamic memory is needed. This makes silent tree-walking more expensive than simple tree- walking.
The specifications of the Auto ID Centre for Class 0 tags contain an alternative procedure to tree walking in which the ID numbers of the tags are not transmitted on the forward channel (downlink), which is subject to eavesdropping [Source: Auto 03]: Instead of identifying themselves with their ID numbers, the tags initially identify themselves with a random number which is newly generated in each reading cycle and serves as a temporary ID number. The reader uses this number in order to mute a recognized tag individually. After all the tags in the reading field have been recognized, their actual ID numbers are queried by transmitting the temporary ID. With this procedure, an attacker eavesdropping on the downlink can merely detect the random numbers used for temporary identification. As a precondition for this procedure, tags must have a random number generator and also possess a function for being muted.
Pseudonymization can mask the identity of a tag so that only authorized readers can find out the "true" identity of the tag. The hash-lock procedure described above (see 7.7.1.2.) is based on pseudonyms (meta IDs) being assigned. However, since a tag retains the same meta ID over its entire lifetime, this procedure does not offer any protection against the tracking of tags. The hash-lock procedure can thus contribute to the protection of data privacy but it does not help to improve location privacy. For this reason, several extensions of the hash-lock procedure have been suggested.
This procedure, proposed by Weis et al. [WSRE 03], is based on the dynamic generation of a new meta ID every time a readout event occurs. For this purpose, at every activation the tag generates a random number r which is hashed with the true ID number of the tag. The random number and the hash value h are transmitted to the reader by the tag. In order to calculate the true ID number of the tag, the operator of the reader must know all the ID numbers belonging to the application in question. The reader or its server now generates the hash values of all known ID numbers, using the random number generated by the tag, until a corresponding hash value is found. At that point the ID number of the tag has been found.
If there are a large number of tags, this procedure is not really practicable. But despite these limitations it is of interest for use with an RFID system, because it can be implemented with minimal cost. However, it presupposes that the tags have a random number generator.
Ohkubo et al. [Source: OSK 03] suggest the chained hash procedure as a cryptographically robust alternative. At every activation the tag calculates a new meta ID, using two different hash functions. First the current meta ID is hashed in order to generate a new meta ID which is then hashed again with the aid of the second function. It is this second meta ID that is transmitted to the reader. For the purpose of decoding, the reader must hash until a match with the meta ID transmitted from the tag has been found. The advantage of this procedure is that it is not sensitive to repeated attempts to spy out the meta ID during transmission via the air interface. An attacker would not be able to back calculate the meta IDs that have been spied out, with the result that the anonymity of all preceding database entries (log entries) of the tag in question is preserved.
Henrici and M�ller [Source: HeM� 04] propose a procedure which makes possible the mutual authentication of tag and reader, as well as encryption of communication, and which also ensures the protection of "location privacy". In addition, no keys or other usable data are stored for any length of time on a tag, thus making physical attacks on the chip hardware uninteresting. The procedure gets by with a minimum exchange of information and is also resistant to interference on the transmission channel (air interface).
In order to ensure location privacy, the tag ID is changed regularly. The tag never discloses the current ID but only its hash value. The latter is calculated by the tag on the basis of in each case new transaction numbers which are synchronized with the back-end of the reader. These features prevent attacks such as replay attacks and detect information losses. Two entries per tag are stored in the backend database, because the possibility of losing the last message from the backend to the tag must be taken into account. The more complicated data management and synchronization in the backend area do not, however, represent any significant limitation, because sufficient resources exist here. By contrast, relatively modest demands are made regarding the hardware of the tag. The chip must be capable of calculating hash values, whereas a random number generator is not needed.
The scalability of the procedure makes it interesting for mass deployment. Assuming mass production, the authors of the procedure estimate the implementation costs at 0.5 euro cents per tag. This means that the procedure can be implemented economically even for low-end tags.
In contrast to most other everyday electronic products, RFID tags do not have an on/off switch. Therefore they can be activated from outside at any time without the owner even noticing that this has happened.
So-called blocker tags were developed [Source: JRS 03] as a method of temporarily preventing the authorized or unauthorized reading of a tag.
A blocker tag is a transponder or a piece of equipment with a high degree of functionality that pretends to be a transponder and simulates all possible ID numbers to a reader. By constantly replying to every demand by the reader to transmit data, a blocker tag makes it impossible to scan the tags that are simultaneously present in its environment. The tags that are actually present are effectively hidden within a mass of virtual tags (in practical terms, several billions of tags). Juels et al. have suggested equipping blocker tags with two aerials so that any prefix singulation can be answered simultaneously with 0 and 1. This kind of blocker tag can effectively block readers that function according to the binary tree procedure.
In order to prevent blocker tags from causing a complete blockage of all RFID applications in practice, procedures have been proposed which would allow blocker tags to block only certain areas of the ID address space [Source: JRS 03]. In this way protected address spaces can be set up where reading is blocked without other applications being impaired.
The reliability of passive blocker tags is poor. Since a passive blocker tag is activated through the energy of the electromagnetic field of the reader to be blocked, the reliability of the protection is restricted by the random spatial orientation, by shielding effects and by the distance between the blocker tag and the reader. In addition, the user is unable to ascertain that the blocker tag is functioning correctly.
Unwanted interference from desired RFID applications in the vicinity cannot be excluded and also cannot be directly detected.
Permanent deactivation of a transponder at the end of its use phase is the most reliable method of protecting it from future misuse of any kind. On the other hand, permanent deactivation also prevents any advantages from being derived at a later date from RFID - e.g. in the case of smart labels the use of data for exchange, repair, reselling or recycling.
A kill command enables the anonymization of transponders by making the readout of tags permanently impossible. This protects persons carrying tagged items from being surreptitiously identified and thus from being tracked.
A kill command was already included in the Auto ID specification [Source: Auto 02] published in 2002. The current EPCglobal specification of the Auto ID Center defines an 8-bit kill command protected by a password. According to the specification, once they have been deactivated by the password-protected kill command, conforming tags may no longer react to the signals of a reader [Source: Auto 03].
The procedures discussed so far are based on deactivation by software technology. This means that theoretically the future reactivation of a tag would be possible.
The kill command is being discussed as a possible means of deactivating smart labels on consumer goods at the point of sale. However, consumers are hardly able to check whether the labels have actually been permanently deactivated. From the point of view of data protection, the effectiveness of the kill command remains questionable, because kill procedures used up to now delete merely the variable memory cells in the transponder but not the unique ID number. In addition, deactivation by means of a password is not very practical if, after shopping, consumers must deactivate the tags one by one and manually.
Electromagnetic deactivation of the hardware via a predetermined rupture (burnout) point, as used in known anti-theft systems (1 bit transponders) would also be feasible but it is so far not being offered.
Starting with the principles of "Fair Information Practices (FIP)" which are the basis of, among other things, the European Data Protection Directive 95/46/EC [Source: EC95], Fl�rkemeier et al. propose measures which are meant to create transparency regarding the operators of a reader and the use to which data are put [Source: FSL 04]. Proceeding from the assumption that current RFID protocols were optimized above all according to technical performance criteria and costs but not with regard to privacy protection, the proposals suggest modifications of current RFID protocols which would be easy to implement. Basic principles of FIP regarding purpose, limited usage, transparency and responsibility can be implemented through relatively minor changes in existing RFID protocols.
This also means that queries by readers must not remain anonymous but must show the unambiguous ID of the reader. If data protection principles are violated, the operator of the reader could then be identified and held responsible. Also, in each case the purpose of gathering the data should be communicated by the reader, for example a readout of serial numbers for marketing purposes. RFID transponders could be programmed in such a way that they only respond by giving their serial numbers when asked to provide the desired declaration of purpose, e.g. for payment.
The additional information about the operator of the reader and the purpose of the data gathering could be decrypted with the aid of a special display device and made visible to the owner of the tags. In this way, the user of the tags is to a certain degree given the chance of checking the function of the tags and of understanding the use to be made of the data that have been read out. The advantage of this procedure is that relatively minor additional effort is required in order to implement it in existing RFID systems. The transparency thus created could contribute to retaining or regaining the trust of the passive party.
The experts were initially asked for their general estimate of how relevant security questions are in the case of RFID applications. The following points emerged:
The results of expert assessments have been collected in Table 8-1 and will be explained below. The attacks listed correspond to the attacks (a) to (n) described in Section 7.5. The costs that the attacker must incur as well as the costs that arise from countermeasures are essential elements in any evaluation of the mid- to long-term risks arising from the attacks. We can only make a qualitative estimate of these costs. The estimates given in Table 8-1 have been derived from the technical preconditions of the attack in question, or of the countermeasures. Countermeasures that are incorporated on the tag can often be cheaply implemented during large production runs. In this context, additional costs for security measures which are in the same order of magnitude as the costs for the system without additional security are designated as medium-range costs. High-cost countermeasures are those that cannot be implemented in practical terms without a generational change in technology.
Eavesdropping on the communication between the tag and the reader
Eavesdropping on the air interface is in principle possible. The risk increases with the maximum reading distance needed for the regular reading process. In the case of transponders with a very short range, the risk is small.
In the case of inductively coupled systems (below 135 kHz, 13.56 MHz) eavesdropping on the downlink is possible over a distance of up to several tens of meters, whereas the uplink can only be eavesdropped on over a much shorter range, namely approximately up to five times the maximum specified reading distance. These are theoretical estimates which are based on the relation between the transmitting power of the reader and of the tag. In their experiments, Finke and Kelter have shown that eavesdropping on the communications of RFID cards according to ISO 14443 (13.56 MHz, operating range 10 to 15 cm) is possible at a distance of up to at least two meters [Source: FiKe 04]. In that study by the BSI the difference between the transmission power of the reader and that of the tag proved to be not very important for eavesdropping purposes. It would be advisable to carry out more investigations regarding the possibilities and conditions for eavesdropping on inductively coupled tags.
In the case of backscatter systems (868 MHz and 2.45 GHz) eavesdropping on the downlink is possible up to a distance of 100 to 200 m, at a power output of 2 Watts; with the help of a directional aerial, this type of eavesdropping is possible up to a range of 500 to 1000 meters. The distances at which eavesdropping can be carried out on uplinks are shorter by two to three orders of magnitude and are therefore in the range of just a few meters. The fact that these data are so imprecise reflects the lack of reliable knowledge. Here, too, we are dealing with theoretical estimates which still need to be validated by systematic experiments.
In general, when eavesdropping occurs from a distance there is a problem in spatially allocating signals, because signals from different sources are superimposed on each other. This makes eavesdropping from a long distance even more difficult.
The costs for the attacker are high, since in every case professional equipment and know-how for decoding the data are needed. It should be remembered that building a normally functioning RFID system configuration is also not a trivial matter, because its reliability depends on a multitude of influencing factors (reflections, shielding, signal-to-noise-ratio, etc.). The conditions for an eavesdropping attack from a great distance would be even less favourable, especially at high bandwidths such as 106 - 848 Kbit/s in systems according to ISO 14443.
Countermeasures:
Under normal conditions, the costs for countermeasures need not be high in order to provide good protection against eavesdropping at the air interface.
Unauthorized reading of the data
This kind of attack requires a reader that can be deployed covertly, without being noticed. For the customary reading distance, this is feasible without incurring unreasonable costs. The attacker has to acquire a reader and possibly take the trouble of surreptitiously installing it. Software products are already being advertised which are used on mobile readers and are capable of reading and writing on simple tags, e.g. in supermarkets (Klaß 04).
The possibilities of such attacks are very limited due to the short range involved and can therefore be prevented in a controlled environment. Special manufacturing of readers with longer ranges is only possible within narrow physical limits and at great expense. In the case of inductively coupled systems, the range can be approximately doubled, but only with considerable effort. One meter is regarded as the definitive upper limit in the case of inductive coupling.
In the UHF range, transmitting power is limited by law to two Watts, which enables readers to operate at a maximum distance of three to five meters. In order to read at a distance of ten meters, a transmitting power of about 30 Watts would be needed, and for reading at a distance of 20 meters, as much as 500 Watts of transmitting power would be required. This is the kind of power put out by broadcast transmitters and would not be practical for a covert operation. Increasing the reading distance is also complicated by the fact that the weak signal of the tags is more and more "overwhelmed" by the stronger signal of the reader. For functional reasons alone, many RFID applications will use tags with very short reading distances, for example smart cards or banknotes.
Thus, the chances of surreptitiously reading passive transponders are spatially very limited. The situation is totally different where active transponders are concerned, but most of the time it is not necessary to use active tags for identification purposes (a typical application is finding the location of objects). As a result, these applications normally do not come under the RFID category.
Countermeasures:
The costs of the countermeasures may be low, if the desired goal can be achieved by using only a few detectors. A weaker variant could also be to conduct a random search for readers. Authentication would raise the unit price of tags significantly in cases where otherwise simple read-only tags would be sufficient. According to expert estimates it can be expected that mass-produced tags using the challenge-response procedure will remain three to five times more expensive than the simplest tags.
According to Infineon, however, the price difference should not be greater than 20 per cent.
Unauthorized modification of data
In the case of re-writable tags the possibilities for unauthorized modification of the data as well as the countermeasures are the same as those in the case of unauthorized readout (see above). If, on the other hand, read-only tags are used, unauthorized modification of the data is intrinsically impossible. This must be weighted against other security disadvantages of the read-only tags, which do not permit any encryption and at best allow only weak authentication (password without protection against replay attacks).
Cloning and emulation
In the case of cloning, the data content of a tag is read out or discovered in some other way in order to write a new tag with the data. This tag is then used to simulate the identity of the original tag.
In addition, it is conceivable to employ devices having a high degree of functionality which are used to emulate any kind of tag with a given data content. Such an emulator could be relatively small (although larger than the tags). If it is possible each time to bring the emulator manually close to the reader, highly flexible means of falsification become available: Someone removes an item from a stream of products; its tag is read using a portable reader (which may also be integrated into the emulator); next, the person goes to the intended reader where, with the help of the emulator, he unobtrusively simulates that the item has passed this point.
A duplicated tag could be used in similar fashion, for example by taking an item off a "smart shelf" and replacing it with the duplicate, so that the intended theft protection does not take effect.
Because cloning and emulating require prior readout or eavesdropping, the countermeasures are the same as those used against these attacks (see above). Both types of attack must be prevented in order to exclude the possibility of cloning and emulation taking place.
Another countermeasure could take the form of plausibility checks in the backend which detect duplicates (e.g. because these crop up at different locations).
Detaching the tag from the tagged item
This attack appears trivial, but that is precisely why it should also be borne in mind. Each RFID system depends on the tags being present on the intended items. "Switching" tags (as is also done nowadays with price labels) with fraudulent intent or merely with the intention of creating confusion is an obvious manipulation.
The mechanical manipulation does not involve any special requirements and therefore tends to be cheap to perform.
Countermeasures:
Mechanical or chemical destruction
RFID tags can be mechanically or chemically damaged. The antennae in particular are vulnerable.
Countermeasures:
Destruction by exposure to an electro-magnetic field
Destruction by exposure to an electromagnetic field is standard practice in the case of anti-theft EAS tags (1-bit transponders) which are deactivated at the point of sale. Although the deactivation could be carried out with relatively simple means also by the customer while in the store, this does not seem to happen in practice.
This type of deactivation is fundamentally possible in the case of all inductively coupled tags, even when no predetermined rupture (burnout) point is provided, as in the case of EAS. Normally, Zener diodes or internal stabilizing circuitry limit the voltage that is induced in the antenna to the intended operating voltage. However, if the voltage induced in the coil exceeds the load limit of the voltage stabilizing system, the chip may be irreversibly destroyed. Only limited protection is possible against over-voltages because the ability of the stabilizing circuitry to absorb excess energy through its surface (heat removal) is limited in the chip. In general, a field strength of at least 12 A/m is required.
Because of the high field strength that is required, this attack can only be carried out at very close range. The same holds true for UHF tags.
Because the field strength decreases with the cube of distance, a transmitter with a very large antenna and a very high power output (broadcast transmitter) would be needed for the mass destruction of tags at several meters distance. This would be scarcely practical for an attacker to accomplish.
In principle, tags could be destroyed with a microwave oven, but not reliably so. If the tag is closely connected to the item bearing it (and that is a good reason for destroying it in a microwave oven) the severe heating of the tag might damage the product.
In addition, there is good reason to suspect that induction coils and high voltage switching events occurring in the near vicinity would induce sufficiently high voltage peaks in the tag to damage the chip. Experiments on this topic are at present being conducted at the EMPA.
Self-healing fuses might be considered as a possible countermeasure against the destructive effect of an electromagnetic field. So far, these have not been included in the standards. However, this countermeasure would not alter the fact that the capacity to absorb superfluously induced energy is limited by the surface area over which the heat can be given off. Therefore, in principle, there is no absolute protection against destruction by exposure to an electromagnetic field.
Destruction by misuse of a kill command
If, for data privacy reasons, tags are equipped with a kill function that partially or totally erases the data content, this function can be misused.
One countermeasure is to provide authentication for the kill command (e.g. password protection). Relatively complicated organizational measures are required in order to communicate the password to authorized persons (e.g. the purchaser of the item bearing the tag), but to keep it secret from others. This procedure is comparable to issuing a chip card with a PIN.
Discharging the battery (only in the case of active tags)
In the case of active tags which have a back-up battery, the latter can be discharged by causing the tag to transmit frequently in response to a rapid sequence of queries.
A possible countermeasure in this case would be a "sleep mode" which forces a pause after an interaction has occurred. This would limit the number of possible interactions per unit of time. Similar functions exist already to prevent duplicate readouts.
Blocking
In contrast to the use of jamming transmitters, the use of blocker tags is not forbidden by law, because due to their passive design they are not transmitting systems. However, their use could be forbidden in the standard business conditions, e.g. of supermarkets. But this would not prevent blocking for the purpose of committing fraud.
One advantage of blocker tags is in principle the fact that their jamming range is scalable and they can be configured for certain address spaces. As a result, privacy protection can be selectively adjusted.
However, it is precisely these individual adjustments that permit people to be tracked, so that the actual goal of ensuring location privacy becomes absurd.
The blocker chip available on the market from RSA is effective only in the tree-walking anti-collision procedure. However, blocker tags may also be developed against the Aloha protocol. In principle, there is no absolute protection against blocking within a given protocol. Since various protocols are in use, the user of the blocker tag must either carry several such tags with him in order to cover all the possible protocols, or he must use a single (slightly larger) blocker device that copes with all the protocols.
The only countermeasure against blocker tags is to ban their use in the standard terms and conditions of business - there are no technical countermeasures that can be taken.
Jamming transmitters
Effective interference of operation at a distance calls for powerful transmitters. Operating such jamming transmitters is illegal and it is difficult for technically inexperienced persons to obtain them: But radio amateurs do have access to this technology.
Close-range jamming is possible using weaker transmitters or also through interactions with other electronic devices (interferences, protocol collisions), but it is difficult to employ such effects reliably in a targetted manner.
Countermeasures:
Field cancellation
Cancellation zones are a normal phenomenon in the UHF range, but are difficult to model. Therefore it seems unlikely that an attacker will succeed in using this effect in a targetted manner, e.g. by setting up reflectors.
There are no general and preventive countermeasures. If targetted field cancellation does, however, become an element of attacks, it will be necessary to find countermeasures tailored to each individual case.
Frequency detuning
This attack is carried out by bringing relevant amounts of, for example, water, metal or ferrite into close proximity of the field or the tag antenna. It might even be enough simply to cover the tag with the hand. However, frequency detuning is less reliable in its effect than shielding and no less obvious.
In principle, it is feasible to counter this type of attack by employing active frequency control. However, the technical effort required seems disproportionate because other, easier forms of attack, such as shielding, are not prevented by this measure. In addition, under certain circumstances, the high frequency licensing requirements for such systems would be infringed.
Shielding
Tags can be shielded by wrapping them in metal foil (e.g. aluminium foil) or by placing them in aluminium-coated freezer bags, or in handbags equipped with metal strips.
As a countermeasure, it is possible in the case of inductively coupled systems to use improved reading stations which are less sensitive to shielding. In particular, several antennae at different angles can make shielding difficult. There is no reliable protection against shielding.
| Attack | Cost | Countermeasures | Cost |
|---|---|---|---|
| Eavesdropping on communication between tag and reader | high | Shift data to the backend Shielding Encoding | medium |
| Unauthorized reading of data | medium to high | Detectors Authentication | medium |
| Unauthorized modification of data | medium to high | Read-only tags Detectors Authentication | low to medium |
| Cloning and emulation | medium | Recognizing duplicates Authentication | medium |
| Detaching the tag from the tagged item | low | Mechanical connection Alarm function (active tags) Additional features | low to mittel |
| Mechanical or chemical destruction | low | Mechanical connection | gering to medium |
| Destruction through field effect | medium | Self-healing fuse (only limited effectiveness) | low when series-produced |
| Destruction through misuse of a kill command | medium | Authentication | medium |
| Discharging of battery (only active tags) | medium | Sleep mode | low when series-produced |
| Blocker tag | low | Banned in standard business conditions | low |
| Jamming transmitter | medium to high | Measurements, Frequency Division (Duplex) (FDD) | medium to high |
| Cancellation of fields | low (but difficult) | none | - |
| Field detuning | very low | Active frequency control | medium to high |
| Shielding | very low | Improved reading stations (only limited effectiveness) | medium |
Table 8-1: Attacks on RFID systems and the respective countermeasures
The results of the expert assessment are compiled in Table 8-2 and will be discussed below. Where the expert opinions diverge, the various standpoints are described in the text.
The general relevance of RFID in terms of the threat posed to privacy or data protection is a controversial topic. Some of the experts whom we asked do not see that there is any such relevance. Their reason for saying so is that, even without RFID, a very large number of data traces are already being generated by credit card payments, mobile telephone calls and customer cards. RFID would not add anything of significance to these databases, which even today are scarcely used.
Other experts see an RFID-specific privacy threat in particular in the possible future ways of tracking people, and they categorize this as a relevant risk of this technology, especially when the tags end up in the possession of the consumer. In many cases the latter will have to weigh up the opportunities and risks, because the more sophisticated and data-intensive future applications such as "Supply Chain Recording" or "Product Life Time Recording" might be of relevant use to him - for example, as regards the transparency of the supply chain (origin, social and ecological aspects) as well as in the case of leasing, maintenance, repair, resale or recycling.
Eavesdropping on communication between tag and reader
This is an attack that threatens the active and passive party in the same way.
The countermeasures are therefore essentially identical (cf. Section 7.4.2):
These measures should, however, be implemented in such a way that the passive party has authorized access to the data that concern it. Otherwise, shifting the data to the backend or encryption would reduce the transparency of the system for the passive party, which would be contrary to that party's need to have control over its own data.
The expense incurred for these security measures is considerably increased by the need to administer access rights.
A further countermeasure may take the form of the passive party protecting itself by (legitimately or illegitimately) attacking the RFID system, as was described in Section 7.3.2.
Unauthorized readout of data
Here again, this is an attack that threatens both the active and the passive party in the same way.
Countermeasures:
A further countermeasure here, too, may take the form of the passive party protecting itself by (legitimately or illegitimately) attacking the RFID system, as was described in Section 7.3.2.
Tracking of people
Opinions vary on the risk that persons might be tracked by RFID. Here is consensus that tracking using covert reading processes (eavesdropping, unauthorized readout) is rather unlikely and it is more probable that regular data capture will form the basis for establishing movement profiles. This view is justified by pointing out, among other things, the technical difficulty of performing covert readouts (see Section 7.3.2). However, opinions differ on the contribution made by RFID to the risk of people being tracked.
On the one hand it is argued that data that would permit such tracking are already being collected today (e.g. through customer cards), but they are not being used for this purpose. No RFID applications which would contribute anything decisive in this area are being planned, nor would they be practical. In particular, no firm is currently considering collecting RFID data outside the logistics chain. Hypothetical applications such as auto-checkout in the supermarket will not be used on a large scale in the next 10 years. The costs of a tag (>5 euro cents) and technical difficulties at the physical level prevent tags from being profitably used for this application. Nor would enterprises wish to jeopardize their reputation and the trust of their customers. The aim of the present rationalization efforts is solely to optimize the supply chain all the way through to the shelf in the store (smart shelf). And even then, RFID labels will probably only be used on individual high-value products, whereas in most cases the labels will be used simply on the delivery package (e.g. pallet). This does not give rise to any additional risk of people being tracked through goods. Even if one wanted to use RFID for tracking purposes, it would be very difficult to derive movement profiles from the extremely fragmented data. It would be enormously expensive to generate an overall picture. There is no economic interest in doing so. Even the data captured currently by customer cards for the most part turn into data graveyards because it is not worth drawing up customer profiles.
On the other hand it is pointed out that if RFID is used on a widespread basis, significantly more events (even if not every purchase of a cheap mass product) will be digitally recorded, and more data traces will be generated that also offer more opportunities for evaluation. This will create new desires, e.g. in government agencies, to perform the evaluations. In addition, retailers are interested in the movement profiles of customers within their stores. Covert readout will remain the exception, but it cannot be completely ruled out. If RFID tags are not definitively deactivated when products are discarded, it might be possible to draw conclusions about the point and time of sale and also about the purchaser of the product by reading data from the tags in the garbage. One particular property of RFID compared with other identification systems is that this technology has the potential to limit the otherwise anonymous nature of the waste disposal process. Furthermore, storing biometric characteristics on transponders is an especially delicate matter. One possible countermeasure would be to use variable ID numbers, e.g. based on the extended hash-lock procedure (see Section 7.7.4).
| Threat | Countermeasures |
|---|---|
| Eavesdropping on communication between tag and reader | Shift into backend with authorized access by the passive party Encryption with authorized access by the passive party Attacks for self-protection (see Table 7-2): Detach the tag, Destroy the tag Blocker tag, Jamming transmitter Field cancellation. Field detuning, Shielding |
| Unauthorized readout of data | Detectors in the possession of the passive party Authentication with authorized access by the passive party Attacks for self-protection (see Table 7-2): Detach the tag, Destroy the tag Blocker tag, Jamming transmitter Field cancellation, Field detuning, Shielding |
| Tracking of people | Variable ID numbers Attacks for self-protection (see Table 7-2): Detach the tag, Destroy the tag Blocker tag, Jamming transmitter Field cancellation, Field detuning, Shielding |
| Manipulation of data to the disadvantage of the passive party | Authentication with authorized access by the passive party Detection of duplicates |
| Improper evaluation of the data | No technical countermeasures |
Table 8-2: Privacy threats due to RFID systems, and corresponding countermeasures
Manipulation of data to the disadvantage of the passive party
Not only unauthorized reading, but any type of manipulation of the data by a third party may be a threat to the passive party, particularly if initially the latter has no means of monitoring such manipulation.
Adequately secure authentication procedures are needed in order generally to prevent third parties from being able to access the data. In order to prevent manipulation, it is especially important for the passive parties themselves to have authorized access to the data that concern them, in order to be able to verify that they are correct.
In this case, also, legitimate or illegitimate self-protective attacks on the RFID system by the passive party, as described in Section 7.3.2, could be regarded as an additional countermeasure.
This section describes and assesses the data protection and security mechanisms within the EPCglobal architecture. It provides general information for EPCglobal members wishing to gain a basic understanding of the data protection provisions within the EPCglobal network and its related standards.
This document does not contain a security analysis of the EPCglobal architecture or any systems based on the EPCglobal architecture. Security analysis requires not only detailed knowledge of the data communications standards, but also the relevant use cases, organizational process, and physical security mechanisms. Security analyses are left to the owners and users of the systems built using the EPCglobal network.
Section 11.2 introduces security concepts. Section 11.3 describes the data protection mechanisms defined within the existing EPCglobal ratified standards. Section 0 introduces the data protection methods that are being developed in evolving EPCglobal standards.
Security is the process by which an organization or individual protects its valuable assets. In general, assets are protected to reduce the risk of an attack to acceptable levels, with the elimination of risk an often unrealizable extreme. Because the level of acceptable risk differs widely from application to application, there is no standard security solution that can apply to all systems. The EPCglobal architecture framework cannot be pronounced secure or insecure, nor can an individual standard, specification or service.
Data security is commonly subdivided into attributes: confidentiality, integrity, availability, and accountability. Data confidentiality is a property that ensures that information is not made available or disclosed to unauthorized individuals, entities, or processes. Data integrity is the property that data has not been changed, destroyed, or lost in an unauthorized or accidental manner during transport or storage. Data availability is a property of a system or a system resource being accessible and usable upon demand by an authorized system entity. Accountability is the property of a system (including all of its system resources) that ensures that the actions of a system entity may be traced uniquely to that entity, which can be held responsible for its actions [RFC2828].
Security techniques like encryption, authentication, digital signatures, and non- repudiation services are applied to data to provide or augment the system attributes described above.
As "security" cannot be evaluated without detailed knowledge of the entire system, we focus our efforts to describe the data protection methods within the EPCglobal standards. That is, we describe the mechanisms that protect data when it is stored, shared and published within the EPCglobal network and relate these mechanisms to the system attributes described above.
This section summarizes the existing data protection mechanism within the standards and specifications forming the EPCglobal network.
Many of the standards within the EPCglobal framework are based on network protocols that communicate EPC information over existing network technology including TCP/IP networks. This section summarizes the data protection mechanisms described within the interface specifications.
Some network standards within EPCglobal rely on Transport Layer Security [RFC2246] [RFC4346] as part of their underlying data protection mechanism. TLS provides a mechanism for the client and server to select cryptographic algorithms, exchange certificates to allow authentication of identity, and share key information to allow encrypted and validated data exchange. Mutual authentication within TLS is optional. Typically, TLS clients authenticate the server, but the client remains unauthenticated or is authenticated by non-TLS means once the TLS session is established. The protection provided by TLS depends critically on the cipher suite chosen by the client and server. A Cipher suite is a combination of cryptographic algorithms that define the methods of encryption, validation, and authentication.
Some EPCglobal network interface standards rely on HTTPS (HTTP over TLS) for data protection. HTTPS [RFC2818] is a widely used standard for encrypting sensitive content for transfer over the World Wide Web. In common web browsers, the "security lock" shown on the task bar indicate that the transaction is secured using HTTPS. HTTPS is based on TLS (Transport Layer Security). A HTTPS client or endpoint acting as the initiator of the connection, initiates the TLS connection to the server, establishes a secure and authenticated connection and then commences the HTTP request. All HTTP data is sent as application data within the TLS connection and is protected by the encryption mechanism negotiated during the TLS handshake. The HTTPS specification defines the actions to take when the validity of the server is suspect. Using HTTPS, client and server can mutually authenticate using the mechanisms provided within TLS. However, another approach (and the one more frequently used) is for the client to authenticate the server within TLS, and then the server authenticates the client using HTTP-level password-based authentication carried out over the encrypted channel established by TLS.
All of the data protection methods below are specified as optional behaviors of devices that comply with the relevant network interface standards. An enterprise must make the specific decision on whether these data protection mechanisms are valuable within their systems.
The ALE 1.0 standard describes the interface to the Filtering and Collection Role within the EPCglobal architecture framework. It provides an interface to obtain filtered, consolidated EPC data from variety of EPC sources. For a complete description of the ALE 1.0 specification, see [ALE1.0].
ALE is specified in an abstract manner with the intention of allowing it to be carried over a variety of transport methods or bindings. The ALE 1.0 specification provides a SOAP [SOAP1.2] binding of the abstract protocol compliant with the Web Services Interoperability (WS-I) Basic Profile version 1.0 [WSI]. SOAP provides a method to exchange structured and typed information between peers. WS-I provides interoperability guidance for web services. SOAP is typically carried over HTTP and security based on HTTPS is permitted by the WS-I Basic Profile. ALE can utilize this SOAP/HTTPS binding for the ALE messages and responses to provide authentication and transport encryption. Authentication and encryption mechanisms together provide for confidentiality and integrity of the shared data.
The ALE interface also allows clients to subscribe to events that are delivered asynchronously. ALE implementations deliver these notifications by posting or sending XML data to a specified URI. The notification channel URIs specified by the standard are based on protocols that do not protect data via encryption or authentication, but allows vendors to provide additional notification mechanisms that may provide these protections.
The current RP 1.1 specification provides a standard communication link between device providing services of a reader, and the device proving Filtering and Collection (F & C) of RFID data. For a complete description, see [RP1.1]
The RP protocol supports the optional ability to encrypt and authenticate the communications link between these two devices when using certain types of communication links (transports). For example, HTTPS can be used as an alternative to HTTP when desiring a secure communication link between reader and host for Control Channels (initiated by a host to communicate with a reader) and/or Notification Channels (initiated by a reader to communicate with a host). This information is relevant to the authentication of the RP communications as the cipher suite provided requires only server authentication. The RP specification provides information and guidance for those desiring secure communication links when using other defined transports; see the RP specification for more details.
The reader management specification describes wire protocol used by management software to monitor the operating status and health of EPCglobal compliant tag Readers. For a complete description, see [RM1.0].
RM divides its specification into three distinct layers: reader layer, messaging layer, and transport layer. The reader layer specifies the content and abstract syntax of messages exchanged between the Reader and Host. This layer is the heart of the Reader Management Protocol, defining the operations that Readers expose to monitor their health. The messaging layer specifies how messages defined in the reader layer are formatted, framed, transformed, and carried on a specific network transport. Any security services are supplied by this layer. The transport layer corresponds to the networking facilities provided by the operating system or equivalent.
The current RM specification defines two implementations of the messaging layer or message transport bindings: XML and (Simple Network Management Protocol) SNMP. The XML binding follows the same conventions as RP described in section 11.3.1.2. The RM SNMP MIB is specified using SMIv2 allowing use of SNMP v2 [RFC1905] or SNMP v3 [RFC3414]. SNMP v2c has weak authentication using community strings which are sent in plain-text within the SNMP messages. SNMP v2c contains no encryption mechanisms. SNMP v3 has strong authentication and encryption methods allowing optional authentication and optional encryption of protocol messages.
EPCIS provides EPC data sharing services between disparate applications both within and across enterprises. For a complete description of EPCIS, see [EPCIS1.0]
EPCIS contains three distinct service interfaces, the EPCIS capture interface, the EPCIS query control interface, and the EPCIS query callback interface (The latter two interfaces are referred to collectively as the EPCIS Query Interfaces). The EPCIS capture interface and the EPCIS query interfaces both support methods to mutually authenticate the parties' identities.
Both the EPCIS capture interface and the EPCIS query interface allow implementations to authenticate the client's identity and make appropriate authorization decisions based on that identity. In particular, the query interface specifies a number of ways that authorization decisions may affect the outcome of a query. This allows companies to make very fine-grain decisions about what data they want to share with their trading partners, in accordance with their business agreements.
The EPCIS specification includes a binding for the EPCIS query interface (both the query control and query callback interfaces) using AS2 [RFC4130] for communication with external trading partners. AS2 provides for mutual authentication, data confidentiality and integrity, and non-repudiation. The EPCIS specification also includes WS-I compliant SOAP/HTTP binding for the EPCIS query control interface. This may be used with HTTPS to provide security. The EPCIS specification also includes an HTTPS binding for the EPCIS query callback interface.
EPCglobal provides core services as part of the EPCglobal network. The following section describes the data protection methods employed by these services.
The EPCglobal ONS core service is based on the current internet DNS. ONS provides authoritative lookup of information about an electronic identifier. See [ONS1.0] for a complete description. Users query the ONS server with an EPC (represented as a URI and translated into a domain name). ONS returns the requested data record which contains address information for services that may contain information about the particular EPC value. ONS does not provide information for individual EPCs; the lowest granularity of service is based on the objectID within the EPC. ONS delivers only address information. The corresponding services are responsible for access control and authorization.
The current Internet DNS standard provides a query interface. Users query the DNS server for information about a particular host, and the domain server returns IP address information for the host in question. The system is a hierarchical set of DNS servers, culminating that the root DNS, serving addresses for the entire Internet community. As the DNS infrastructure is designed to provide address lookup service for all users of the internet, there is no encryption mechanism built into DNS/ONS. Any user wishing to gain Internet address information, can query DNS/ONS directly, hence the encryption of DNS traffic would have little or no benefit.
New records are added to ONS manually, by electronic submission via a web interface. These submissions are protected by ACL (access control list) and by shared secret (password).
For a complete security analysis of DNS, see [RFC3833].
Discovery has not been addressed in the existing architecture.
Manager ID number assignment is provided by EPCglobal core services. These documents are provided as standard text files on the EPCglobal public web site. Currently, these files contain only a list of the assigned manager numbers, and do not contain any information on the assignee of each ID.
A Tag Air Interface specifies the Radio Frequency (RF) communications link between a reader device and an RFID tag. This interface is used to write and read data to and from an RFID tag.
In general, transmitted RF energy is susceptible to eavesdropping or modification by any device within range of the intended receiver. To this end, each Tag Air Interface may have various countermeasures to protect the data transmitted across the interface specific to the application of the particular standard.
The Class 1 Generation 2 Tag Air Interface standard specifies a UHF Tag Air Interface between readers and tags. The interface provides a mechanism to write and read data to and from and RFID tag respectively. A tag complying with the Gen2 standard can have up to four memory areas which store the EPC and EPC related data: EPC memory, User memory, TID memory, and reserved memory. For a complete description of the Gen2 Tag Air Interface see [UHFC1G21.0.9].
The Gen2 Tag Air Interface, as its name professes, is the second generation of Class 1 Tag Air Interfaces considered by EPCglobal. To this end, many of the security concerns of previous generation Tag Air Interfaces were well understood during the development of Gen2.
The following describes the key data protection features of the Gen2 Tag Air Interface.
Class 1 tags are passive devices that contain no power source. Tags communicate by backscattering energy sent by the interrogator or reader device. This phenomenon leads to an asymmetric link, where a very high energy signal is sent on the forward link from the interrogator to the tag. The tag responds by backscattering a very small portion of that energy on the reverse link, which can be detected by the interrogator, forming a bi- directional half-duplex link.
Depending on the regulatory region, antenna characteristics, and propagation environment, the high power forward link can be read hundreds to thousands of meters away from the interrogator source. The much lower power reverse link, often with only one millionth the power of the forward link, can typically be observed only within 10's of meters of the RFID tag.
To prevent the transmission of EPC information over the forward link, the Gen2 standard employs pseudonyms, or temporary identities for communication with tags. A pseudonym for a tag is used only within a single interrogator interaction. The interrogator uses this pseudonym for communication with the tag rather than the tag's EPC or other tag data. The EPC is only presented in the interface on the backscatter link, limiting the range of eavesdropping to the range of backscatter communications. Eavesdroppers are still able to obtain EPC information during tag singulation, but cannot obtain this information from the high power forward link.
Gen2 provides a select command which allows an interrogator to identify a subset of the total tag population for inventory. Using the select command requires the interrogator to transmit the forward link the bit pattern to match within the tag memory. Forward link transmission of this bit pattern may compromise the effectiveness of the pseudonym.
For the same reasons described above, it may be undesirable to transmit non-EPC tag data on the forward link. To this end, Gen2 includes a technique called cover coding to obscure passwords and data transmitted to the tag on the forward link. Cover coding uses one-time-pads, random data backscattered by the tag upon request from the interrogator. Before sending data over the forward link, the interrogator requests a random number from the tag, and then uses this one-time-pad to encrypt a single word of data or password sent on the forward link. An observer of the forward communications link would not be able to decode data or passwords sent to the tag without first "guessing" the one-time-pad. Gen2 specifies that these pads can only be used a single time.
An observer of the forward and reverse link would be able to observe the one-time-pads backscattered by the tag to the interrogator. This, in combination with the encryption method specified in Gen2 would allow this observer to decode all data and passwords sent on the forward link from the interrogator to the tag.
Gen2 specifies an optional Block Write command which does not provide cover coding of the data sent over the forward link. Block write enables faster write operations at the expense of forward link security.
Gen2 contains provisions to temporarily or permanently lock or unlock any of its memory banks.
User, TID, and EPC memory may be write locked so that data stored in these memory banks cannot be overwritten. Reading of the TID, EPC and User memory banks are always permitted. There is no method to read-lock these memory banks. This memory can be temporarily or permanently locked or unlocked. Once permanently locked, memory cannot be written. When locked but not permanently locked, memory can be written, but only after the interrogator furnishes the 32-bit access password.
Reserved memory currently specifies the location of two passwords: the access password and kill password. In order to prevent unauthorized users from reading these passwords, an interrogator can individually lock their contents. Locking of a password in reserved memory renders it un-writeable and un-readable. The read locking and write locking of password memory is not independent, e.g. memory cannot be write-locked without also being read-locked. A password can be temporarily or permanently locked or unlocked. Once permanently locked, memory cannot be written or read. When locked but not permanently locked, memory can be read and written only after the interrogator furnishes the 32-bit access password.
Gen2 contains a command to "kill" the tag. Killing a tag sets it to a state where it will never respond to the commands of an interrogator. To kill a tag, an interrogator must supply the 32-bit kill passwords. Tags with a zero-valued kill password cannot be killed. By perma-locking a zero valued kill password, tags can be rendered un-killable. By perma-unlocking the kill password, a tag can be rendered always killable.
The Tag Data Standard, currently version 1.3, specifies the data format of the EPC information, both in its pure identity URI format and the binary format typically stored on an RFID tag. The TDS specification provides encodings for numbering schemes within an EPC, and does not provide encodings or standard representations for other types of data. For a complete description of the TDS specification, see [TDS1.3]
RFID users are sometimes concerned with transmitting or backscattering EPC information that can directly infer the product or manufacturer of the product. Current Tag Air Interface standards do not provide mechanisms to secure the EPC data from unauthorized reading.
TDS allows for the encoding of data types that contain manufacturer or company prefix, object ID information (e.g. SGTIN) and serial number. TDS also specifies encoding of formats that contain company prefix and serial number, but do not contain object identification information.
The TDS specification does not provide any encoding formats that standardize the encryption or obstruction of the manufacturer, product identification, or any other information stored on the RFID tag.
Several standards within the EPCglobal network were created specifically to address security issues of shared data.
The authentication of entities (subscribers, services, physical devices) operating within the EPCglobal network serves as the foundation of any security function incorporated into the network. The EPCglobal architecture allows the use of a variety of authentication technologies across its defined interfaces. It is expected, however, that the X.509 authentication framework will be widely employed within the EPCglobal network. To this end, the EPCglobal Security 2 Working Group produced the EPCglobal X.509 Certificate profile. The certificate profile serves not to define new functionality, but to clarify and narrow functionality that already exists. For a complete description, see [Cert1.0]
The certificate profile provides a minimum level of cryptographic security and defines and standardizes identification parameters for users, services/server and device.
EPCglobal electronic pedigree provides a standard, interoperable platform for supply chain partner compliance with state, regional and national drug pedigree laws. It provides flexible interpretation of existing and future pedigree laws.
In the United States, current legislation in multiple states dictates the creation and updating of electronic pedigrees at each stop in the pharmaceutical supply chain. Each state law specifies the data content of the electronic pedigree and the digital signature standards but none of them specifies the actual format of the document. The need for a standard electronic document format that can be updated by each supply chain participant is what has driven the creation of the specification.
The Standard does not identify exactly how pedigree documents must be transferred between trading partners. Any mechanism chosen must provide document immutability, non-repudiation and must be secure and authenticated. Although the scope of the standard focuses on the pedigree and pedigree envelope interchange formats, secure transmission relies on the recommendations for securing pedigree transmissions defined by the HLS Information Work Group.
23. Q: What is specified in the EPCIS standard?
A: The EPCIS standard specifies two interfaces and a data model. The EPCIS Data Model specifies a standard way to represent visibility information about physical objects, including descriptions of product movements in a supply chain. The main components of the data model include EPC, Event Time, Business Step, Disposition, Read Point, Business Location, and Business Transaction. The data model is designed to be extended by industries and end users without revising the specification itself. Some extensions that have been used in EPCIS pilots to-date include Expiration Date, Batch Number, and Temperature.
Visibility information in EPCIS takes the form of “events” that describe specific occurrences in the supply chain. An example event would be that EPC 123 (product) was Received (business step) in Non Sellable condition (disposition) at Distribution Center X (location) yesterday at 2pm EDT (time). A quick way to summarize the components of an EPCIS event are what (product), when (time), where (location), and why (business step and disposition).
The EPCIS Event Capture Interface specifies a standard way for business applications that generate visibility data to communicate that data to applications that wish to consume it. In many cases, the receiving side of the Event Capture Interface will be a repository, but this is not necessarily the case.
The EPCIS Query Interface provide a standard way for internal and external systems to request business events from repositories and other sources of EPCIS data using a simple, parameter-driven query language. There are two types of queries - Poll Queries for a synchronous, on-demand response, and Subscription Queries for an asynchronous, scheduled response.
24. Q: So EPCIS is a repository?
A: No. The EPCIS specification only specifies interfaces, not implementations. Many types of applications may implement the interfaces. A repository is certainly one such type of application, but not the only type. A pure EPCIS repository application might implement the EPCIS Event Capture Interface to receive events, store them in a relational database, XML database, file system, or other persistent store, and implement the EPCIS Query Interface to make those events available to other applications. A Warehouse Management System application, in contrast, carries out many more functions than pure storage of events; nevertheless it may too implement EPCIS interfaces. For example, it might implement the EPCIS Capture Interface so that EPCIS data may serve as one of many sources of input data. Likewise, it might implement the EPCIS Query Interface to expose visibility information to other applications, where that visibility information was calculated from other inputs, though not necessarily exclusively from the EPCIS Capture Interface.
ERP systems, track-and-trace applications, visibility services, and others are all examples of applications that might implement one or both of the EPCIS interfaces. Nothing in the EPCIS specification limits its use to one type of application or another.
25. Q: What are the data elements in the EPCIS standard?
A: The data elements in the EPCIS standard data model define WHAT (product), WHERE (location), WHEN (time), and WHY (business step and status) for granular product movements in the supply chain.
WHAT
WHERE
WHEN
WHY
The final standard field is Action, which has three values:
26. Q: How can implementers extend the data elements in the EPCIS standard?
A: Implementers can freely define field names in the Extension section of the XML data model. It is readily possible to capture and query for extension fields. Many pilots to- date have successfully used the extension capability - with examples including Expiration Date, Batch Number, Temperature, Receiver Name, and Shipper Name.
27. Q: What are the appropriate values for the data elements in the EPCIS standard?
A: The EPCIS specification does not define required values for many data elements. Instead it leaves the definition to trading partners. Within the EPCglobal Data Exchange Joint Requirements Group, we are well-underway in defining standard values for the data elements involved in sharing business events between trading partners. These data elements are Business Step, Disposition, Business Location, and Business Transaction Type. This Joint Requirements Group currently has membership from the Retail, Consumer Products, Health Care & Life Sciences, Transport & Logistics, and Aerospace industries.
EPCglobal defines the standard values for the EPC code within the Tag Data Standards specification.
28. Q: What are the business events specified in the EPCIS standard?
A: There are four business events defined in the EPCIS 1.0 specification.
29. Q: How is EPCIS data secured?
A: There are two forms of data security described in the EPCIS specification - authentication and authorization.
30. Q: How does the EPCIS standard define error conditions?
A: The EPCIS standard provides a range of standard errors that can be raised by an implementation when responding to a query. These errors include Query Parameter Exception (a query parameter is invalid), Query Too Large Exception, Subscription Controls Exception (invalid control definition for a subscription query), Validation Exception (query syntax not correct), Security Exception (query not permitted), and Implementation Exception (implementation had a failure).
31. Q: How did you test that the EPCIS standard works?
A: Twelve large and small solution providers from Japan, Korea, and North America met in July 2006 to thoroughly test their ability to interoperate using the prototype EPCIS specification. We used test cases from the EPCglobal EPCIS pilots. Based on the successful interoperability event and the minor changes that we made to the EPCIS standard to further ease interoperability, we are confident that the final EPCIS standard will work well in deployments.
As presented in section 3.1.1, competitive intelligence methodology basically relies on gathering data from different sources, and on analyzing those data in order to obtain (to extract) critical information. So, in the context of competitive intelligence, would it be possible to use the information shared within supply chains as a source of information? Considering both literature review and industry survey as presented in section 3.1.2, this seems one of the biggest concerns when considering sharing of item-level data.
In an EPC-enhanced supply chain, information can be extracted from data gathered querying EPCIS repositories. Such data are called EPCIS events. By extension, we could say that critical information can be extracted starting from those events too. This can be demonstrated considering a three-partner supply chain as shown in Figure 44.
Goods flow from the manufacturer to the retailer; the wholesaler acts as a broker in the middle. All partners implement the EPCglobal architecture for both internal and external operations (e.g., shipping or storing). Figure 44 shows only the external operations (connections), i.e., those useful for the integration with external partners. In order to maximize the benefit of the implementation of RFID technology, each entity shares external operational information with the other partners (internal information are considered not public). External information includes: shipping events, shared with the receiver in order to automate the recognition and receipt of the received item (CHK_REC, through the purchase order number present in the bizTransaction field), and receiving events, shared with the sender as acknowledgement of receipt for the sent item (ACK_SHIP).
Having access to all shared events, information considered critical like structure of the supply chain, delivery quantities, and delivery times (as mentioned in section 3.1.2), could be extracted. As an example, the wholesaler can be considered: this entity buys large quantities of products from one manufacturer (maybe in an exclusive way) and sells smaller quantities to several retailers. Within its business, it may consider critical information the time that a certain item remains in its domain (stocking time). Reasons can be the comparisons with other wholesalers by the retailer (price vs. products' freshness), or by the manufacturer (market penetration and distribution times) during negotiation phase (so, in order to decrease wholesaler's negotiation power, as mentioned in section 3.1.2). Considering the presented situation, it is possible to identify at least three different ways to obtain that critical information:
Intra-domain queries: the stocking time is computed only from the wholesaler's
shared information. In fact, this is simply the difference between the time when an
item is received by the wholesaler (eventTime at RW1), and the time when the same
item is shipped by the wholesaler (eventTime at RW2). Both times can be retrieved
from the wholesaler's EPCIS repository with two queries:
a. Query = MATCH_epc: 123; EQ_bizStep: receiving
b. Query = MATCH_epc: 123; EQ_bizStep: shipping
Mix-domain queries: the stocking time is calculated starting from both wholesaler's shared information and its partners' shared information. An upper-bound of the stocking time can be computed by:
Extra-domain queries: the stocking time is calculated without any interaction with the wholesaler. In fact, an upper-bound of the stocking time can be computed by the difference between the time when an item is shipped by the manufacturer (eventTime at RM1), and the time when the same item is received by the retailer (eventTime at RR1) (Same note as above.)
Each of the three different cases (intra-domain, mix-domain, and extra-domain) shows a different stocking time. In fact, both mix-and extra-domain cases present an upper-bound of the stocking time that includes the time spent to transport an item from one location to another. This shows how different sets of events can lead to the same critical information but with different accuracies (considering the stocking time found in intra-domain case as the reference one), and introduces the notion of level of knowledge.
For level of knowledge of certain critical information, we mean how much, or how much precisely, the requester (who queries the EPCIS repositories) knows about that critical information. Considering the previous example: the intra-domain case shows a high level of knowledge, since the requester knows exactly the stocking time, while both mix-and extra- domain cases show a lower level of knowledge, since the requester has just an approximate idea of the stocking time.
As already mentioned, in a competitive intelligence context, different sources of information can be considered. Therefore, EPCIS repositories could be just one of these sources. By considering other sources, it would be possible to fulfill the lack of information due to a limited number of EPCIS events, and consequently, increase the accuracy of the extracted critical information. Considering the presented case, by simply investigating the location of each entity, and assuming a certain means of transport, it is possible to estimate the time necessary to transport an item from one location to another. Therefore, by taking in account this time, it would be possible to increase the level of knowledge on the stocking time for both mix-and extra-domain cases.
Figure 44. Manufacturer-Wholesaler-Retailer Supply chain
Starting from a basic example, it was possible to show how the concept of competitive intelligence can be applied within supply chain. In particular, we showed: (i) how critical information can be extracted from EPCIS events shared among partners, (ii) that it is not necessary to interact directly with the entity to which the critical information refers, in order to obtain that information, and (iii), how is possible to increase the accuracy of the extracted information.
Once demonstrated that EPCIS events can be used to extract critical information, the next question is: how is it possible to prevent such a leakage of information? That is, considering a data request coming from a certain user (the requester), how and by which means can the decision be taken on whether to release that data?
In a collaborative environment such as a supply chain, it is not possible just to consider a party (e.g., a company) as a stand-alone entity; a decision of one party (e.g., to share certain information) may affect other parties. That is, in a supply chain, critical information of an entity can be (partially) leaked by its partners (as shown on the example in section 3.2). Therefore, an entity that receives a data request, should decide whether releasing that data considering: (i) the possible leakage of its own critical information based on its internal information (intra-domain), (ii) the possible leakage of its own critical information based on both internal and external information (mix-domain), and (iii) the possible leakage of partners' critical information (extra-domains).
So, what is needed is a procedure that allows an entity to evaluate the requester's level of knowledge with respect to certain critical information, and a framework that hosts such a procedure and presents the capability of invoking different evaluation procedures (i.e., from different domains). Staring from these remarks and considering the example in section 3.2, it is possible to identify some basic requirements/needs of such a procedure/framework:
Starting from these basic requirements, it is possible to identify and define three parts/needs related to the evaluation procedure:
First, we need a formalization of the system into entities -data -critical information. In section 3.2, the critical information has been described in natural language. In order to use this description in technical domains (e.g., automated evaluation procedure or data mining), a translation to a more formal definition is needed. Therefore, it is necessary to define a language or system that allows describing critical information (and its levels of knowledge) with respect to entities and data (both EPCIS events and information coming from other sources) in a more general and mathematical way. Once defined, this language or system (based e.g., on dependency graphs or Bayesian networks) can be employed to represent each piece of critical information by mean of its rules and symbols.
Second, the critical information evaluation procedure needs to be able to (i) collect all the necessary information with respect to certain critical information and regarding the requester (this means past requests or released data from both intra-and extra-domains), (ii) merge that information, plus the new request, with the formalized critical information, and (iii) obtain and indicate the new level of knowledge with respect to that critical information.
Third, the evaluation procedure needs to be integrated in an existent secure framework, such as an access control system. Therefore, the procedure could be seen as some criticalinformation- rule that will be one of the elements to consider in order to grant access to a certain data. For example, there could be a rule that defines users' maximum level of knowledge. This rule indicates, for each user, the maximum level of knowledge of certain critical information. Therefore, the access control system will invoke the evaluation procedure, pass to it user information, critical information to evaluate, and requested data, get back the levels of knowledge, and compare them to the limits set by the rule. Once one of these limits is exceeded, access is denied.
Considering the extra-domain information needed for the evaluation, the access control system has to present some distributive characteristic, like e.g., the sharing of users' requests (or released data). A distributed access control system will also give the possibility to implement extra-domain rules. For example, there could be a rule that defines the users' maximum level of knowledge with respect to external evaluation. Therefore, the access control system will contact an external access control system, pass to it user information and requested data, get back a certain level of knowledge, and compare it to the limit set by the rule. Once exceeded this limit, the access is denied.
Additionally, considering the nature of both EPCIS queries and possible answers (that can contain more events and several fields in each event), it seems reasonable to not only evaluate the entire answer, but also parts of it. Therefore, it could be useful to integrate in the access control system a mechanism that tailors the answer (e.g., strips off some event's field) until the level of knowledge reaches a reasonable amount (defined, e.g., in the rule "users' maximum level of knowledge").
Considering the example in section 3.2, and the presented evaluation procedure / access control system, prevention of wholesaler's critical information could be obtained as follows:
PRIME project is a large-scale research effort aimed at developing an identity management system able to protect users personal information and to provide a framework that can be smoothly integrated with current architectures and online services. In this context an important service for helping users to keep the control over their personal information is represented by access control solutions enriched with the ability of supporting privacy requirements. To fully address the requirements posed by a privacy-aware access control system, the following different types of privacy policies have been defined in the context of PRIME Project.
Access control policies. They govern access/release of data/services managed by the party (as in traditional access control). Access control policies define authorization rules concerning access to data/services. Authorizations correspond to traditional (positive) rules usually enforced in access control systems. An access control rule is an expression of the form:
<subject> with [<subject_expression>] can <actions> on
<object> with [<object_expression>] for <purposes> if [<conditions>]
Release policies. They govern release of properties/credentials/personal identifiable information (PII) of the party and specify under which conditions they can be released. Release policies define the party's preferences regarding the release of its PII by specifying to which party, for which purpose/action, and under which conditions a particular set of PII can be released. Although different in semantic access control and release policies share the same syntax.
Data handling policies. They define how personal information will be (or should be) dealt with at the receiving parties. Data handling policies regulate how PII will be handled at the receiving parties (e.g., information collected through an online service may be combined with information gathered by other services for commercial purposes). Users exploit these policies to define restrictions on secondary use of their personal information. In this way, users can manage the information also after its release. Data handling policies will be attached to the PII or data they protect, and transferred as sticky policies to the counterparts. A DHP rule is an expression of the form:
<recipients> can <actions> for <purposes> if
[<gen_conditions>] provided [<provisions>] follow [<obligations>]
A prototype providing functionalities for integrating access control, release and data handling policies evaluation and enforcement has been developed in the context of PRIME project.
The reference scenario is a distributed infrastructure that includes three parties: i) users are human entities that request on-line services; ii) service provider is the entity that provides on-line services to the users and collects personal information before granting an access to its services; iii) external parties are entities (e.g., business partners) to which the service provider may want to share or trade personal information of users. The functionalities offered by a service provider are defined by a set of objects/services. This scenario considers a user that needs to access a service. The user can be registered and characterized by a unique user identifier (user id, for short) or, when registration is not mandatory, characterized by a persistent user identifier (pseudonym). Three major use cases are listed in the following.
XACML version 2.0 was ratified by OASIS standards organization on 1 February 2005.
Similarly to PRIME languages, XACML proposes a XML-based language allowing the
specification of attribute-based restrictions. Main differences with PRIME languages are
as follows.
- XACML does not explicitly support privacy features.
- Although XACML supports digital credentials exchange, it does not provide
request for certified credentials.
- XACML does not support and integrate location-based conditions and ontology.
P3P allows Web sites to declare their privacy practices in a standard and machine-
readable XML format. Designed to address the need of the users to assess that the
privacy practices adopted by a server provider comply with their privacy requirements,
P3P has been developed by the World Wide Web Consortium (W3C). Users specify their
privacy preferences through a policy language, called A P3P Preference Exchange
Language (APPEL), and enforce privacy protection by means of an agent. Similarly to
PRIME languages, P3P proposes a XML-based language for regulating secondary use of
data disclosed for the purpose of access control enforcement. It provides restrictions on
the recipients, on the data retention and on purposes. Main differences with PRIME
languages are as follows.
- P3P does not support privacy practices negotiation. The users in fact can only
accept the server privacy practices or stop the transaction. The opt-in/opt-out
mechanisms result limiting.
- P3P does not support definition of policies based on attributes of the recipients.
- P3P does not provide protection against chains of releases (i.e., releases to third
parties).
* Protocol
* Memory
* Other
* EPCGlobal Class1 Gen2 fully compliant
* 16-bit lock command