Petri Nets and UML Activity Diagrams are related but semantically different languages; see Störrle and Hausmann (2005) for details. This document proposes similar looking textual notations (inspired by the Conceptual Graph Linear Form) for Petri Nets and UML Activity Diagrams.
Indeed, there exist graphical or XML-based notations for these languages but no concise and readable textual notations. For example, the XML-based Petri net standard (PNML) is hardly readable. Graphical forms (i) require a tool to be entered or visualized, (ii) are time-consuming to enter, (iii) need to be transformed into images before exchanging them via email or including them into documents, (iv) take a lot of space on a screen and hence are difficult to compare visually, (v) cannot be handled via text management tools, e.g. their parts cannot be searched and copy/pasted in a text editor or a Web browser.
Google on "Petri Net Linear Form" to find the persons/organizations using PNLF.
Table of Contents
The examples are taken from the book used at www.workflowcourse.com.
Below, a PNLF representation of the solution of this Example (p.310 of the book) is followed by the image of its modelling with PIPE (the Platform Independent Petri Net Editor). Compare the two representations.
In PNLF, a Petri net in the linear/textual form is composed of one of several
statements separated by semi-colons (the last statement ends by a dot).
Places are enclosed within parenthesis and transitions within square brackets.
Each token is represented by "@". Coreference variables (e.g. *r and *ry below) are
used for connecting various occurrences of a same place or transition.
Commas are used for separating different branches of the graph.
Given the following graphical form (which is nearly identical to the one given in
the book), the textual representation does not seem particularly helpful but you
will see in a later document (disclosed Week 8) that the linear form is very
helpful to present and comment the graphical representations of these models in the
IBM WebSphere Business Integration Workbench. See also the last section of this document.
Also note that PIPE can only permit it user to represent implicit AND/OR splits, not explicit AND/OR splits. The page 59 of the book shows the mapping between the two forms (and page 56 explains why using an implicit OR split is sometimes adequate when using an explicit OR split is not). Thus, to represent an OR-split in PIPE, use a place and connect it to two (or more) transitions (the simulation in PIPE works, it just randomly selects one transition). To represent an AND-split, connect a transition to two (or more) places.
[red_yellow *ry] //in PNLF, for readability reasons, all the outputs of
// a node should rather be presented together;
{ <-(c1 *c1 @), // some inputs may also be given
->(red *r @) { ->[*ry], ->[yellow_green *yg] }, //OR-split
->(yellow *y) { ->[yellow_red *yr] { ->(*c1), ->(*r) },
->[*yg]->(green)->[green_yellow] { ->(*y), ->(c2)->[*yr] }
} //OR-split
}. //all the outputs of an OR-split should be presented together
//Note that in PNLF, when a variable is re-used (as in [*ry]), the node type is not
// given again; different nodes can have a same type but a variable is unique to a node
//Also note how paths are explored/presented as soon as readability permits it
// (the arcs from/to *yg could have been presented later but this may
// have made the mental synthesis/checking of the graph a bit more difficult,
// especially for people who do not have a good short term memory).
// Better one graph than two (or more), unless a graph becomes bigger than 25 lines
// (a short page; a graph should never be cut by a page break); like functions in
// a C/Java program.
// A branch should be described on the remainder of the line if it has at
// most two sub-branches and if the desciption does not make the line
// go over 70 characters (limit over which some email clients begin
// line-wrapping).
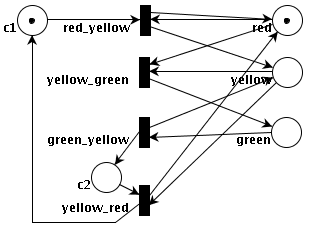
Note the above layout with the transitions (the black rectangles) below one another.
Such a "vertical layout" makes graphics simpler to understand and gives the author plenty of
space: it permits the author not to use abbreviations for names (which is rarely a good idea),
nor to overlap names (overlaps force the reader to guess the names, or if she can, move
the nodes to read the names), nor to use too many arcs with several breakpoints (use
direct/simple arcs whenever possible). It is better to develop graphs vertically
instead of horizontally to ease printing or other displays on devices with limited
width..
Although places named c1, c2, ... are used in the PNLF representations above and
below because these are the names used in the solutions in the book,
ONE SHOULD NOT USE abbreviations such as c1, c2..., P1, P2, ..., T1, T2, ...,
even with a legend (within an annotation) giving the full names of the places and
transitions. Indeed, this makes the graphics and the results of the analysis
EXTREMELY hard/long to understand and check (by people), and hence are also
inappropriate to support communication between people (using such abbreviations
is nearly as inappropriate as writing in a foreign language and giving a reference
to a translation dictionary for this language). The book may use such abbreviations
either because actual names do not really matter for certain exercices (any symbol
will do), or because it has space constraints.
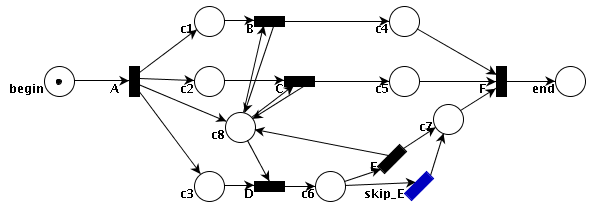
This model contains "implicit OR-splits" (p.59 in the book): in the linear form, see the strings "){" (for the OR-split after "c6", the "yes" and "no" cases actually form an explicit representation).
(begin @)->[A *a]{->(c1)->[B *b]->(c4)->[F *f]->(end),
->(c2)->[C *c]->(c5)->[*f],
->(c3)->[D *d]->(c6){yes->[E *e]->(c7 *c7), no->[skip_E]->(*c7)}
};
[*a]->(c8){ ->[*d], <-[*e], ->[*b], <-[*b], ->[*c], <-[*c], ->[*f] }.
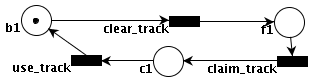
(busy1 *b1 @)->[clear_track]->(free1)->[claim_track]->(claimed1)->[use_track]->(*b1).
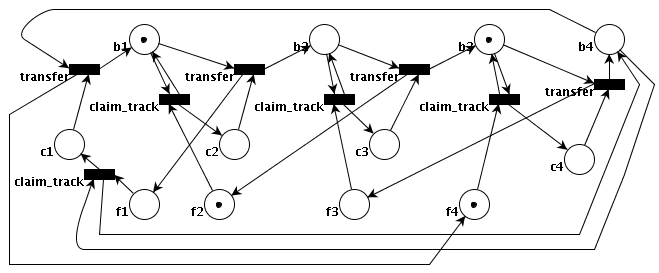
The solution given in the book seems to miss an arc from the place "f4" to a transition "claim_track". I have added it here.
(busy1 @
*b1){ <-[claim_track *ct2]<-(free2 *f2 @), ->[*ct2]->(c2)->[transfer *t12],
->[*t12]{ ->(free1 *f1), ->(busy2 *b2) };
(*b2){ <-[claim_track *ct3]<-(free3 *f3), ->[*ct3]->(c3)->[transfer *t23],
->[*t23]{ ->(*f2), ->(busy3 *b3 @) };
(*b3){ <-[claim_track *ct4]<-(free4 *f4 @), ->[*ct4]->(c4)->[transfer *t34],
->[*t34]{ ->(*f3), ->(busy4 *b4) };
(*b4){ <-[claim_track *ct1]<-(*f1), ->[*ct1]->(c1)->[transfer *t41],
->[*t41]{ ->(*f4), ->(*b1) }.
Here are three example steps in a simulation of
a basic Petri net ('@' representing the token, as in my examples):
step 1: (p1 *p1 @)->[tr1]->(p2)->[tr2]->[*p1].
step 2: (p1 *p1)->[tr1]->(p2 @)->[tr2]->[*p1].
step 3: (p1 *p1)->[tr1]->(p2)->[tr2]->[*p1 @].
Regarding transition "triggers" (p.63 of the book), PIPE does not permit
to represent them directly/explicitely but you can use an extra input place to
model them anyway (p.64 of the book).
In PNLF you can represent triggers directly as in:
(p1 @)->[tr1 "time signal"]->(p2).
Use "time signal" or "resource initiative" or "external event" or
anything else you think is more precise (just use double quotes
around).
PIPE permits a restricted representation of time in the transitions
(see "rate" and "enable timing" when you right-click on a transition)
but I have not seen differences in the simulations.
You can represent time in PNLF as follow:
[transition_name 18sec].
With PNLF, for other precisions that you would like to include in a
transition or a place, simply use some new syntactic element (e.g.
use single quotes or $ or %, ...) and tell me within a C/Java comment
what your new syntactic element means.
/* This is an example of a C/Java comment */
OR-splits are useful for representing outcomes of decision tasks. For example, consider the following alternative representations:
[review_of_schedule]->(change_required?) { yes->[make_changes],
no->[send_copy]
}.
(client_contacted)
{ ->[positive_review_of_schedule]->(change_required),
->[negative_review_of_schedule]->(change_not_required)
}.
In PIPE, "yes" and "no" are not represented (as illustrated in above
for Example 2). The second representation does not seem elegant
(and only one token must be in "(client_contacted)" for the OR-split to
happen). It also implies that selection rules have to be associated to
each of the alternative tasks and hence the tasks themselves are
empty (they perform no action and thus cannot be decomposed).
The first representation is also better because it is closer to
how it would
be represented in Websphere:
[review_of_schedule_by_client]->< change_required? >
{ yes->(change_required)->[make_changes],
no->(change_not_required)->[send_copy_to_FD]
}.
To conclude, it is better to use the first representation and not to forget
putting the question mark at the end of the name of the place that is the origin of
the OR-split. It is not necessary to put "OR" within an annotation near
the place.
Note the naming conventions used in transitions and places:
- for transitions: verb (or nominal for a process) + object
(+ subject if it is not the system,
e.g. "review_of_schedule_by_client");
- for places: nominal expression, e.g. "schedule_reviewed_by_client".
The syntactic rules are expressed using the EBNF notation. The terminal tokens are in italics. The lexical rules needed to specify these terminal tokens are given in the last section of this document. C++ line comments are used to include comments.
PNLF := (statementsWithinTheSameScopeForVariables ".") +
statementsWithinTheSameScopeForVariables := statement ( ";" statement )*
statement := transitionStatement | placeStatement
transitionStatement:= transition indirectLinksToTransitions
placeStatement := place directLinksToTransitions?
transition := "[" transitionId annotation* "]"
transitionId := ( transitionType transitionVariable? ) | transitionVariable
transitionType := identifier
transitionVariable := identifierOfVariable
identifier := singleQuotedString | doubleQuotedString | term
place := "(" placeId token? annotation* ")"
token := "@"
placeId := ( placeType placeVariable? ) | placeVariable
placeType := identifier
placeVariable := identifierOfVariable
annotation := attributeAndValue | annotationString
attributeAndValue := attribute "=" value
attribute := identifier
value := identifier | PositiveInteger
indirectLinksToTransitions := 1IndirectLinkToTransition | nIndirectLinksToTransitions
1IndirectLinkToTransition := (("<-" place "<-")| ("->" place "->")) transitionStatement
nIndirectLinksToTransitions:= "{" 1IndirectLinkToTransition ("," 1IndirectLinkToTransition)* "}"
directLinksToTransitions := 1DirectLinkToTransition | nDirectLinksToTransitions
1DirectLinkToTransition := ("<-" | "->") transitionStatement
nDirectLinksToTransitions := "{" 1DirectLinkToTransition ("," 1DirectLinkToTransition)* "}"
| "{ yes -> " transitionStatement ", no ->" transitionStatement "}"
| "{ no -> " transitionStatement ", yes ->" transitionStatement "}"
The syntactic grammar of ADLF is more or less an extension of the grammar of PNLF, and it is presented in a similar way below. However, the term of "object" is used instead of "transition", and "activity" is used instead of "place".
ADLF := (statementsWithinTheSameScopeForVariables ".") +
statementsWithinTheSameScopeForVariables := statement ( ";" statement )*
statement := objectStatement | activityStatement
objectStatement := object indirectLinksToObjects
activityStatement := activity directLinksToObjects?
object := "[" objectId annotation* "]" | controlObject
controlObject := "<" controlObjectId annotation* ">"
controlObjectId := "InitialNode" | "ForkNode" | "JoinNode" | "DecisionNode" |
"MergeNode" | "ActivityFinal" | "FlowFinal"
objectId := ( objectType objectVariable? ) | objectVariable
objectType := identifier
objectVariable := identifierOfVariable
identifier := singleQuotedString | doubleQuotedString | term
activity := "(" activityId token? annotation* ")"
token := "@"
activityId := ( activityType activityVariable? ) | activityVariable
activityType := identifier
activityVariable := identifierOfVariable
annotation := attributeAndValue | annotationString
attributeAndValue := attribute "=" value
attribute := identifier
value := identifier | PositiveInteger
indirectLinksToObjects := 1IndirectLinkToObject | nIndirectLinksToObjects
1IndirectLinkToObject := (("<-" activity multiplicity? "<-")|
("->" multiplicity? activity "->")) objectStatement
nIndirectLinksToObjects:= "{" 1IndirectLinkToObject ("," 1IndirectLinkToObject)* "}"
multiplicity := positiveInteger ".." positiveInteger
directLinksToObjects := 1DirectLinkToObject | nDirectLinksToObjects
1DirectLinkToObject := ("<-" | "->") objectStatement
NthDirectLinkToObject := ("<-" | guard? "->") objectStatement
nDirectLinksToObjects := "{" NthDirectLinkToObject ("," NthDirectLinkToObject)* "}"
guard := simpleGuard
simpleGuard := identifier
The lexical rules - needed to specify the characters constituting terminal tokens and what characters between these tokens are ignored (spaces, comments) - are represented in Lex (EBNF would be much more cumbersome; EBNF also does not permit to represent negation and hence exclude certain characters).
Lexical rules in Lex format:
([ \n\t\r ]|" ")+ ; //ignore spaces (the character after \r is not a regular
//space but the non-breaking space)
"//"[^\n]* ; //ignore C++ line comments: //...
"/*"([^\*]|(\*[^\/]))*"*/" ; //ignore C multiline comments: /*...*/
"/^"([^\^]|(\*[^\/]))*"^/" ; //ignore also this kind of multiline comments: /^...^/
"(^"([^\^]|(\*[^\/]))*"^)" return annotationString; // (^...^)
'([^'\\]|(\\(.|\n)))*' return singleQuotedString;
\"([^"\\]|(\\(.|\n)))*\" return doubleQuotedString;
"->" return rightArrow; // "->"
"<-" return leftArrow; // "<-"
[0-9]+ return positiveInteger; //this rule has priority over the next
[^*+-/%=;,!|<>{}[]()`'" \n\t\r ][^*=;|<>{}[]()`'" \n\t\r ]* return term;
. return yytext[0]; /*return the character.
Note: for ADLF, it is also necessary to return each controlNodeId as a special kind of
lexical token (i.e., not as a term); for example:
"InitialNode" return INITIAL_NODE; */