Typology of Some Programming Practices Or Conventions
Goal/use, structure and reading of this file:
- This file – or similar ones – may be pointed to in a program header (e.g., via a comment such as "//Complied-to programming practices and conventions: see http://www.phmartin.info/js/doc/PPs/") to specify and justify the collection of programming practices (PPs) that this program complies to. When complied to, these PPs become design conventions, and knowing them (especially the naming conventions) help the readers of the program interpret the code.
- This file is meant to provide one possible high-level organization for all (potential)
programming-related practices: this file shows how such PPS can be organized by specialization
relations (in this document, this is informal but such relations can then be represented
formally in a knowledge (representation) base).
Thus, in this document, “programming practice” does not refer to a rule that everyone (or a majority of person) considers as a “good/best practice”, but to a rule that at least one person considers as “good/best practice”. This is why the abbreviation “PP” is used in this document even though “BP” is a more common abbreviation. - This file is also used in a software development course. This is why some parts – such as the definitions of Section 1.2 – are given even though they could be taken for granted. The reader of this document is assumed to read at least the expressions in bold characters, in their given order. These expressions are generally the titles of sections, paragraphs, definitions or PPs; the title of a definition is the term it defines). Thanks to these titles, the reader can choose to skip their related bodies or not, and can come back to some of them whenever needed (e.g., when encountering particular uses of particular defined terms).
- This section and the PPs in this file are more or less ordered from the most general ones to the less.
Table of Contents
1. General Goals, Definitions and PPs 1.1. General Goals: Normalizing Programs For Understandability, Maintenance, Scalability, Translatability and Genericity Purposes 1.2. Other General Definitions 1.3. Most General PPs 2. Structural Representation PPs (→ Programming Paradigm, Modularity, Structural Normalization, ...) and Lexical Representation PPs (→ Naming PPs, Lexical Normalization, ...) 2.1. General Representation PPs For Genericity/Re-usability Purposes 2.2. Variable Names (PP_2.2: using good/useful variable names, essentially, informative ones, even if long) 2.3. Function Names and Parameters (PP_2.3: using good function names+parameters) 2.4. Other Names: File Names, XML Names, ... 2.5. About Documentations 2.6. About Inputs and Outputs: User Interfaces, ... 3. Non-Structural/Lexical PPs (→ Programming Style) 3.1. Function Size and Space/Indentation Related PPs
1. General Goals, Definitions and PPs
1.1. General Goals: Normalizing Programs For Reusability, Hence For Understandability, Maintenability, Scalability, Translatability and Genericity Purposes
Context: categorization of software quality criteria. Software quality refers to two related notions or sets of criteria:
- Functional quality:
- the functional suitability
of the software (how well it complies with or conforms to a given design, based on functional
requirements or specifications),

- its usability (for the client; e.g. regarding the user graphical interface), i.e. the degree to which it can be used by specified consumers to achieve quantified objectives with effectiveness, efficiency, and satisfaction in a quantified context of use.
- the functional suitability
of the software (how well it complies with or conforms to a given design, based on functional
requirements or specifications),
- Structural quality: how the software meets non-functional requirements that
support the delivery of the functional requirements, such as robustness or maintainability.
The quality criteria are said to be “external” if they are visible by the client,
and “internal” otherwise. The
“information security criteria” can be decomposed into
dependability and
security in its classic sense. Their uppermost sub-criteria are:
- for dependability but not security: maintainability, reliability and safety;
- for dependability and security: availability and (data) integrity (+ accountability);
- for security but not dependability: confidentiality.
There are other structural quality criteria, e.g. efficiency and performance.
(Re-)usability. In this document, “reusability” refers to the internal criteria for “dependability but not security”: maintainability and reliability. The notions of scalability, genericity, modularity, translatability (automatically, in other programming languages) and understandability (alias readability; by people) can be seen as sub-criteria of maintainability and then, indirectly, of reliability. In this document, only the internal aspects are considered but these criteria have external consequences, hence related external criteria. Programming is not just about coding a program that seems to solve a given problem for the particular cases that the programmer have thought about, it is about creating a program that is
- as usable and helpful as possible, hence reliable, taking into account as many situations as possible and delivring good/helpful error messages for all the different kinds of bad input that the user can enter), and
- as reusable as possible, hence maintainable, scalable and understandable (readable) and translatable. Note: 40%-80% of the lifetime cost of a piece of software goes to maintenance.
Normalization. Normalizing a program is to follow programming practices/techniques (PPs) when writing it (notably for the above cited purposes): structural representation PPs (→ programming paradigms, methodologies or (notions of) common APIs), lexical representation PPs (→ naming conventions) and presentation PPs (→ programming style).
1.2. Other General Definitions
The following paragraphs precise the meaning the particular meaning that some terms have in this particular document.
Translation: automatic conversion of operations from a programing language to another.
Operation: function or another statement that uses a programming language.
Function: subroutine (or whole program), whether it return a value or not. Thus, “procedures” and “methods“ are also “functions”.
Method: a function associated to an object, as in object-oriented (O.O.) programming. A function that is not a method is, from now on, called a “normal function”. Note: when a method is translated into a normal function, the object this method is associated to becomes the first parameter of the normal function; hence, below, when the first parameter of a method is referred to, the object is actually referred to.
In/out parameters: a function parameter (alias, argument) may be either
- “in” (alias “in”); it has a value that is not modified by the function; in C, it would be declared as “const”;
- “in-out” (alias “varP”): it has a value that is modified by the function);
- “out” (alias “outP”): its value is initialized by the function.
In this document, the return value of the function is not a parameter. Parameters are also variables.
Type: predefined type or user-defined type/class, typically for a variable or a constant. In Javascript, the predefined primitive types (those that can be checked via the “typeof” operator) are: Function, Symbol, Object, String, “undefined”, Boolean, Number (and BigInt). However, Javascript also proposes other types such as Array, Date, RegExp, Set and Error. The (static or dynamic) type checking of an operation is the automatic checking that the operation does not violate constraints associated to the types of the variables involved in the operation. The checking is static if it is performed at compilation time and dynamic if it is performed at execution time.
Program: collection of functions.
Process: execution of a program. Each process has its own id, allocated memory, etc.
Thread:
execution of the smallest collection of functions (from a program, hence generally within
a process) that can be run by a scheduler: a thread is a unit of execution.
Different threads of a process shares the memory (variables, ...) of this process.
Different threads may be run in parallel but functions within a thread may not.
In this file, this is the absence of parallelism within functions of a thread that is important.
User (of a program):
- programmer: someone that reads the program (in order to write, update or reuse it), e.g. its author;
- end-user: someone that executes (and hence uses) the program.
Generic. In this document, “generic” means i) scalable, and ii) not tied to particular choices (e.g., of data structure, technique and communication medium, ...). This last point implies that, if some choices are handled, many are handled (as many as possible) and that the end-user may choose between them.
Informal (as opposed to semi-formal or fully formal): represented in a way that the used software (compiler, ...) cannot exploit. In semi-formal representations, the software understands some general structure but not the full content. E.g., for a compiler, (discarded) comments are informal, (stored) annotations and identifiers are very weakly semi-formal (the compiler know what they are), while pragmas and any keyword of the parsed language is formal.
Knowledge (Representations; KRs): information that is, at least partially,
represented and organized i) in some logics, and ii) via by semantic relations
(e.g. subtype, part, instrument, result, time, place, ... and hundreds more).
Data: information that is not a collection of KRs.
Note: these two definitions make "information" a generalization of data and knowledge,
which is coherent with the fact that KR bases/repositories and data bases/repositories are
also (usually considered as) information repositories. There are other definitions of
"information" with refer to an intermediary between "data" and "knowledge" (e.g., for some
of these definitions, "information" is "data + semantics", while "knowledge" is
"information + entailment"). These other definitions are not followed in this document.
Knowledge Base (KB): a collection of terms or KRs, composed of
- an ontology: a set of formal terms + KRs defining these terms;
- a base of facts: KRs about objects that are not types.
Database: collection of terms and information that is not a KB but which, instead of an ontology, has a fixed structural schema (only the creator of the database can update it, not end-users, and, except in deductive databases, the programmer cannot define relations in this schema). Databases, even deductive databases, do not allow their users to define new types of relations and do not allow them to relate objects via explicit semantic relations except sometimes via relations of a few predefined kinds such as "subtype Of" and "instance Of". An XML document is not a relational database but be viewed as a database.
DB management system (DBMS): software managing a DB.
KB management system (KBMS): software managing a KB. A KBMS may be implemented by reusing
(and very strongly extending) a DMBS where the structural schema mainly has two kinds of objects:
i) concept nodes (objects that can be related by relation nodes,
e.g. terms and quantified objects), and
ii) relation nodes (or simply “relations” things that relate concept nodes;
a relations can only indirectly be related to other ones, via its “reification”,
a concept node that refer to this relation).
Instance: anything that is instance of (i.e, that has for type)
a predefined or user-defined type or a class.
Individual: anything that cannot have an instance
(hence, anything that is not a type or class; thus, a literal is an individual;
in itself, a variable is an individual but some variables may have a class
as value, i.e. may point to that class).
Note: this definition of individual is most often used in general logics (e.g. 2nd-order logics)
and general object-oriented systems (where almost everything has a class, e.g. in Smalltalk).
In some more restricted logics (e.g. description logics) or object-oriented systems,
some non-type objects (e.g. litterals) are not considered "individuals".
1.3. Most General PPs
PP_1.1 (1st PP advocated by this document, and also the most general and hence most important): supporting choices by the users (→ not making choices for the users but not forcing them to make choices either) and allowing the user to check as much things as possible (with users referring to end-users and programmers). This is an adaptation to “software design” of the more general PP “Letting everyone choose and check everything in an optimal way” which is a PP for any action or decision. This for example means that a program that systematically satisfies this PP should be sufficiently generic to satisfy the following more specialized PPs:
- PP_1.1.1: letting users choose
- the exploited particular database backend (e.g. a disc-based one or a memory-based one) and data structures (e.g. mutable ones or not, file based or memory based ones), and hence
- the exploitable of kinds of data (e.g. collections of objects stored in directories, files, databases or main memory), in so far as the exploited data containers have the properties required by the software (thus, if the program requires a KBMS instead of a DBMS, a DBMS cannot be directly used as backend).
- PP_1.1.2: letting users choose more or less specialized versions or implementations of a function. This is for example possible by i) storing functions in a KB instead of a traditional library, ii) organizing them via specialization relations and other ones (creator, part, ...), and iii) letting the end-user statically/dynamically override each choice of “default version” made by the program creator (as long as the used parameters allow this or, conversely, with a normalization of parameters to support this).
- PP_1.1.3: letting users specify or modify preconditions and post-conditions for any function (and, if possible, any loop) for i) broadening, restricting or checking the kind of data the function works on (e.g. for uppercase letters to be handled as lowercase letters), or ii) removing or adding some treatments, e.g. for adaptation or checking purposes.
- PP_1.1.4: letting users selectively check what is performed, e.g. for safety or explanation purposes; regarding safety purposes, this means (among other things) i) providing a well organized “execution graph” of functions and instructions, ii) letting digital signatures be associated to each program (and to each function, especially if the functions can be dynamically selected), iii) supporting or enforcing the association of these signatures to each result (to ensure that each result come from a function that is trusted by the end-user, either because its code has been checked by the end-user or because the end-user trusts its creator).
PP_1.2: maximizing the number of complied-to requirements (functional ones and non-functional ones, e.g. PPs), supported features and complementary ways to support them (this last point is also required for letting users choose, as advocated by the previous PP).
- PP_1.2.1: complying with as many PPs as possible or,
more exactly, complying with a set of compatible PPs that maximizes advantages.
Indeed, i) each PP has advantages, so “the more are complied to, the more advantages
there are”, and ii) PPs are often compatible.
PPs are generally “compatible” and often even reinforce each other. This is
because they reinforce related criteria. E.g.:
- Improving code modularity/precision also improves code clarity (readability, understandability) and all improve core (re-)usability. This example also shows why this document does not directly focus on the clarity (readability, understandability) criteria but why they are often indirectly or implicitly supported by most of the proposed PPs.
- As seen in Section 1.1, security in its classic sense and dependability and i) have shared criteria, and ii) this last one may be seen as one super-criteria for scalability, genericity, modularity, translatability, understandability, reliability and “(re-)usability” (as defined in Section 1.1). When making choices, it is always good to especially think about “information security” (in its general senses) and translatability. They both mostly relate to structural PPs (Section 2) and, in particular, PP_1.1 (plus, for translatability, PP_2.1.5).
- PP_1.2.2: supporting as many complementary media/devices as possible. E.g., communication/collaboration tools should (have various modes allowing them to) work i) with a low "minimum bandwidth", ii) when possible, with several media, communication channels and remote control of the cameras by the participants (→ to observe various non-verbal feedbacks), iii) over long distances (→ taking into account communication delays), and iv) in a secure ways for participants (→ both anonymity and accountability should be possible, even when comunications are recorded).
2. Structural Representation PPs (→ Programming Paradigm, Modularity, Structural Normalization, ...) and Lexical Representation PPs (→ Naming PPs, Lexical Normalization, ...)
This section groups structural and lexical representation PPs because Section 2.3 is about a PP for naming functions and choosing their parameters.
2.1. General Representation PPs For Genericity/Re-usability Purposes
Programming for genericity/re-usability purposes is about avoiding the loss of information
representation (and hence exploitation) opportunities.
This includes letting users make choices and extensions, not making these choices
for the users.
Many of these PPs are inter-related even when categorized in different sub-sections, e.g.
PP_2.1.4.2 (not directly using the functions of a language or of a library
that you cannot modify) and
PP_2.1.2.1 (not directly relying on particular data types/structures).
PP_2.1.1: avoiding the loss of opportunities to i) represent information in explicit and precise ways (hence in as formal ways as possible), and then ii) automatically check its usages. E.g., it is better to store information in function names than in comments, for two reasons: i) what is stored can be exploited, and ii) when a function with an informative name is used, the reader does not have to find the function definition and its associated comments to get the information and understand what the function does). Similarly, when comments can be replaced by tests (pre-conditions, post-conditions, ...) with informative error messages, it is much better since i) the content of the comment is operationalized (→ checks are performed automatically, not just in the head of the program readers), and ii) not just the program readers that can get the information. Example sub-PPs derived from these examples:
- PP_2.1.1.1: using names with all the distinguishing details necessary for understanding their uses (e.g., instead of "persons", "aFromSourceX__oPerson": see details in PP_2.2, e.g., for the abbreviations and conventions used in this last example name).
- PP_2.1.1.2: using more exploitable representations than comments, whenever possible (e.g., via name conventions, pre-conditions, post-conditions, informative error messages); pre-conditions and post-conditions should be used at least at the beginning of each function and loop when all the necessary checks and explanations are not provided via types checking.
- PP_2.1.1.3
(which actually generalizes the two previous PPs):
use defensive programming,
via pre-conditions and post-conditions delivering relevant and informative error messages,
not just via assert
operations or throwing exceptions and/or forwarding them!
Defensive programming (DP) is essential for code quality and scalability.
Here are important subkinds of DPs:- Systematic Functional defensive programming (SFDP) means that i) all kinds of errors (that the programmer can think about) are checked, and ii) functions always return, even if it is with a value that indicates an error. This value should always support function composability (one of the advantages of functional programming), e.g. if usually a collection is returned, returning an empty collection when an error is encountered maintains this composability. Although exception throwing may be seen as a modularisation feature (since they allow to handle errors in places not madated by the control flow, a bit like "aspects" of "aspect programming"), in non-functional programming languages, throwing an exception is sometimes seen (e.g. by the author of the document refered to by this hyperlink) as akin to a "goto" (albeit worse since a goto at least jumps to a well-defined location): it disrupts the normal program flow, thus generally breaking function composability and possibly introducing side effects, resource leaks (such as escaping a section locked by a mutex, or one temporarily holding a file open) or inconsistent states. Functional languages that support exceptions generally automatically i) extend the return types of the functions where exceptions can occur, and ii) transform exceptions into special return values using this extension. This is also what is implemented, albeit manually, in what is called "using a functional style for exceptions in an imperative language", e.g. in Java. In any case, as soon as an error is detected, a maximum of information should be collected about the context (e.g. program line, stack of function calls) to be incorporated in error messages/logs with the level of precision chosen by the user.
- Offensive programming (OP) is a sub-category of DP (but not of SFDP) where particular kinds of errors are purposely not handled defensively: asserts or exceptions may be used to handle these errors, or even nothing at all if the approach described by the next point is used.
- “Let it Crash” programming (LICP) is a sub-category of OP. LICP is a fault-tolerance technique that is used when the program cannot (or is not meant to) properly handle particular kind of errors. However, when LICP is used, the processes that called the processes that crash must correcty handle the crash, e.g. by correctly braking process chains and logging or delivering relevant error messages, closing file descriptors, shutting down opened network connections, killing or restarting relevant processes, etc. This is why LICP often relies on BEAM, the virtual machine of the Erlang functional language.
When a client-server architecture is used, input data should i) for performance and usability reason should (also) be validated client-side (i.e. by the client's browser, using some Javascript or client-side VBscript code), and ii) server-side, for security reasons since the client-side checking may be bypassed. - PP_2.1.1.4: using (debug/warning/...) traces that are dependent on (and hence indexed by) importance levels and topics, to allow the users to search them or filter them out whenever they are (not) needed.
- PP_2.1.1.5: using a strongly typed language
(hence, generally, a statically typed language, e.g. a
functional one such as Standard ML,
Haskell and
Scala).
If using a less typed language as target language is mandatory (e.g., if Javascript must be used because this is the only language that most Web browsers directly understand),- one solution is to develop programs using a strongly typed language and then automatically translate the functions into the less typed language (for Javascript, this may for example be performed via Javascript transpilers/transcompilers or TypeScript);
- when such a translation is not practical, a solution is to use
function preconditions and post-conditions for checking the types of their
parameters and allowing other treatments (cf. PP_2.3.3).
If the language is untyped and if special prefixes are not used in the names of variables for indicating their types (cf. PP_2.2.4), these types may be indicated via special comments before variable declarations (cf. PP_2.3.2).
- PP_2.1.1.6: when typing a
function/variable/property/..., also stating other precisions/modifiers/specifiers such as whether it is
- modifiable and deletable/removable, e.g. via const, volatile and mutable in C++ and writable or configurable in Javascript;
- overridable by a more specialized function or property, e.g. in C++ (and Java) the keywords virtual and final can be used;
- (in the case of a function) callable asynchronously (e.g. to handle non-blocking I/O without explicit callbacks) or able to support lazy-computed sequences; C++20 allows the use of keywords such as co_await, co_yield, generator and lazy as well as synchronized and atomic_commit for threads;
- ... (the more precisions/modifiers/specifiers the better, e.g. see named requirements in C++20).
- PP_2.1.1.7: making sure that variables are correctly initialized before they are used. For most variables, this means initializing them as soon as they are declared (possibly with a value meaning that the variable is not yet defined, e.g. null, NULL, 0 or Infinity or INFINITY.
- PP_2.1.1.8: using the strongest error detection
options or procedures available, e.g.:
- PP_2.1.1.8.c: for a C++ program with gcc, using the “-Wall” compilation option;
- PP_2.1.1.8.js:
for a Javascript program,
- using the “strict” interpretation mode (hence the “use strict” macro),
- enabling “error notification” in the browser; - PP_2.1.1.8.html: for an HTML+CSS program, using an HTML+CSS validator.
PP_2.1.2: avoiding the loss of opportunities to represent information in (more) generic ways. E.g.:
- PP_2.1.2.1
(not directly relying on particular data types/structures):
first proposing functions that do not rely on particular data types/structures
– e.g. using templates, virtual functions or general objects –
and then specializing these functions or objects, e.g. for efficiency purposes
and letting the users (end users or other programmers) choose the data types/structures.
PP_2.2.4 (using prefixes in variable names for indicating the variable types) is for specializing these functions or objects, i.e. when implementation choices have to be made, and hence is not contradictory with this PP. It should also be noted that using data structures that represent generic "knowledge representations" is ideal for genericity and interoperability purposes. - PP_2.1.2.2: using first-order entities, hence variables instead of particular identifiers, whenever possible, e.g. using functions as parameters. In programming, first-order entities (alias, first class objects/citizen) are those that can be put into variables. In functional languages, functions can be put into variables and are thus usable in function parameters, e.g. for applying the parameter function to the members of a collection, representing a new control structure or choosing between different strategies according to the context (the data, the users' preferences, ...). Until recently, many other-oriented languages such Java did not support this. This is why, to turn around this limitation,objects representing functions or some O.O. design patterns were used instead (and this leads to more complex codes).
- PP_2.1.2.3: stating when operations can be performed in parallel or asynchronously. This may imply defining a function that specify that its parameter functions can be executed in parallel or via larzy evaluation. Alternatively, the program may use conventions (for particular comments) supporting translations in languages that allows more formal ways of specifying parallel or asynchronous operations.
PP_2.1.3: avoiding the loss of opportunities to represent information in (more) standard and inter-related ways. This for example implies
- reusing (as much as possible) methodologies, common vocabularies/terms/concepts and (notions of) common APIs such those of JavaBeans),
- always reusing existing functions (and hence never starting programs from scratch).
PP_2.1.4: avoiding the loss of modularity opportunities: managing different aspects separately (→ separation of concerns). E.g., the following aspects should each be handled by different (and generic) functions: i) each of the aspects that can be fully handled client-side, typically, all or most of the handling of inputs, outputs, errors and communications with the users or other agents (information prviders or consumers), ii) each of the aspects that can be fully handled server-side, typically, database handlings. At least three paradigms are complementary powerful ways to modularize and normalize the representation of functions: i) object-oriented (O.O.) programming (OOP), ii) functional programming (FP), especially the use of function as parameters and the use of immutable data), and iii) aspect-oriented programming (AOP). Even when a language does not offer particular facility to support them, these paradigms can be adopted: O.O. can be simulated in any language (cf. PP_2.3.1); FP and AOP can be simulated in any language that allow variables to contain (pointers to) functions (via function pre-conditions and post-conditions for AOPs; cf. end of PP_2.3.3). Example sub-PPs:
- PP_2.1.4.1: using the OOP, FP and AOP approaches in conjunction with other PPs (cf. PP _1.1), and at least SFDP (when OP and LICP are not used; cf. PP_2.1.1.4; when SFDP is used, functions always return and with an initialized value: there are no procedure, no assert operation and no exception raising).
- PP_2.1.4.2: not directly using the functions of a language or of a library that you cannot modify, e.g. functions for error handling or information printing, displaying and logging. The added indirection (e.g. via inheritance) i) eases the use of other languages or libraries (→ translatability), and ii) allow the use and exploitation of more PPs (paradigms, pre-conditions, ...).
- PP_2.1.4.3: structuring the code as much as possible,
e.g.
- avoiding any code duplication (of more than 1 line) at different places
- avoiding any function of more than 30 lines (and more than 10 lines outside functions).
- PP_2.1.4.4: maximizing modularity (→ separation of concerns, control by the user, ...) and information representation+sharability via a KB-supporting data model (→ possibly a shared KB) and a decentralized architecture (→ at least a Web-based client-server architecture or possibly a more decentralized architecture, e.g. an agent-based one or a peer-to-peer based one).
PP_2.1.5: avoiding the loss of data or access to data (when this is relevant).
- PP_2.1.5.1: avoiding/reducing the loss of data by avoiding/reducing updates, using (→ purely functional programming, use of immutable data, etc.), fault-tolerant data structures or additive updates (storage of the fact that something as a corrrected version instead of the modification of this thing). Purely functional programming and, more generally, loss-less updates, have many advantages. They ease the reuse, analysis (proof, ...) and parallelization of functions, their conversion to other programming languages or their use along with functions from other programming paradigms, including logic programming.
- PP_2.1.5.2: avoiding the loss of access to data
caused by the use of some options/directives. E.g.:
- PP_2.1.5.2.1: always allowing users to chose between the GET protocol and the POST protocol for the way a server can be called (or, in a client, the way information are sent to a server), and letting the GET protocol be the defaut choice. Indeed, while the parameters of POST calls are not visible to users (they are not stored in the call/command), GET calls/commands explicitly include their parameters and hence GET calls can be i) stored for later reuse (in a file, in bookmarks, via URLs, ...), ii) redone via the “going back” or “history” facilities of a browser (for particular operations such as “paying something with a credit card”, accidental repetitions can still be easily avoided via simple checks by the server), iii) manually modified by users, etc. Updates can be made via the GET protocol, e.g. via the GET or PUT methods. Using POST instead of GET for security reasons is a mistake. To conclude, except when the size of the sent information is too big (URL greater than 2048 chararacters), there is no reason to prefer using POST instead of GET.
- PP_2.1.5.2.2: never using transfer/redirect/goto instructions as a way to call a function or a sub-program (e.g. the instructions Request.transfer and Request.redirect in VBscript and the instruction "redirect" in a CGI header). Indeed, this makes the whole program hard to understand, maintain and debug. Normal program/function calls may be used instead.
2.2. Variable Names
(PP_2.2: using good/useful variable names, with all details necessary for understanding their
use, even if the name long)
Reasonably long names (→ typically less than 40 characters long) can be used in ways that do not strongly reduce the readability of a program and, the more information are stored in variable names (e.g. about their types), the more useful these name are. Using conventions (or a formal language) when storing information in a name make them more concise, normalized and, often, extractable and exploitable via a software (e.g., for checking and translation purposes): the name is then said to be semi-formal. The more conventions are used (or, the more a formal language is used), the more information can be stored in an automatically exploitable way. A knowledge representation language could be designed and used for representing information within a name (-> some of its meaning) but i) this often makes the name long and/or hard to read for people, and ii) a KB system must be used to decode and exploit the information (→ an heavyweight solution that is generally not required for programming purposes only). Using conventions such as the ones presented below is a good tradeoff: although using some of these conventions slightly reduces readability for people that do not know these conventions, it may be argued that the more such conventions are used in a name, the more useful the name (hence the better).
PP_2.2.1: using very informative names (PP_2.1.1.1) for variables and hence, generally, long names and NO abbreviations (except for an abbreviation that is frequently used AND whose meaning has been made explicit via a document referred to in the program header, as for the reserved prefixes of PP_2.2.4).
PP_2.2.2: when naming variables, using uppercase characters in the following ways (which are classic in C programs):
- variable names mainly use the InterCap/CamelCase naming style since it is concise and allows the separators "_" and "__" to have special meanings (cf. next PP);
- type/class names only use the InterCap/CamelCase naming style to allow the use of these names in variables with the special uses of "_" and "__" (cf. next PP);
- macros and global constants must either have at least 2 successive characters in uppercase (and may use the '_' separator for distinguishing words in this name) or be prefixed by "Cst_" (then they can be written like variables; macro functions begin by an uppercase, may have 2 successive characters in uppercase but do not use '_', so function names without '_' and with an uppercase initial should be macros).
- names for global variables and classes (and constants written like variables). uppercase initial, and only them.
Note: in most programming languages, identifiers characters can (unfortunately) only be 'a'..'z', 'A'..'Z','0'..'9' and '_'; thus, '-' is generally not a character usable within names, only '_' is.
PP_2.2.3: when naming variables, using the separator "_" when the InterCap/CamelCase naming style is insufficient, e.g. for specifying the following kinds of information (in that order):
- For specifying the name of the adopted set of conventions when this set is not specified in another way.
- For prefixes specifying variable attributes (or other specificities not related to types),
e.g.
- "cl" for class variables (for class methods, "mk" is to be preferred").
- "st" for non-class local static variables, with "static" having the meaning given to this word in C++. In C++, a static local variable (i.e. declared using the keyword "static") is global in some sense but can only be used with the scope of the class, function or file it is declared in (for details, see a C++ documentation). Thus in C++, "Employee::cl_birthdate" would refer to the class variable "cl_birthdate" of the class "Employee".
- "St" for static global variables, i.e. global but local to a file. For the sake on conciseness, global pointers do not require a "St_" prefix as long as they begin by "Spt" or "Spo".
- "Gl" for non-static global variables (not global constants). For the sake on conciseness, global pointers do not require a "Gl_" prefix as long as they begin by "Pt", "Ptr" or "Po".
- "Cst" for macros and global constants written like variables.
- "cst" for non-global "constants" ("c" may also be sufficient after other attribute prefixes). In Javascript, the keyword "const" can be used to ensure that semantic. Idem in C if "const" is used on a variable that is not a reference.
- "csti" (or "ci") for what is meant in C when "const" is used for a reference, before the '*', as in "const char*" and "char const*". This means that what is referred cannot be change via this variable, hence the 'i' for this special kind of immutability; see the next point ("imm") for another view. To avoid having to specify "ci_" before the abbreviation for the type, some suffix can be used in this abbreviation, as with "si" for variables containing "csti" strings (see "StringOrCharPointer" in the box below).
- "imm" for variables referring to with immutable objects (there are various ways to specify immutability in Javascript). In C, this is specified with "const" after the type or '*', as in "char* const".
- "r" for a variable that is local to a function and is used for the return value of this function.
- "io" or "varP" for a variable that is an in-out parameter, and
"oP" or "initP" for a variable that is an out parameter, i.e., that is meant to be initialized by the function.
In these two cases, pointers are usually indirectly used (in C++, the '&' operator is used before the parameter and makes it a pointer even though syntactically it is not; in Java and javascript, there is such '&' operator since all variables referring to objects are already actually pointers to those objects).
- For separating class/structure names from member/property names, e.g. as in “Company_Employee_DateOfFirstHiring” (and, "Employee_birthdate" would refer to the birthdate of an employee). I.e., '_' is to be used instead of the '.' of an O.O. notation when this one cannot be used.
- In variables referring to a collection, "__" introduces the type of sub-elements. E.g., with the prefixes listed in PP_2.2.4, "a__a__int" would refer to an array of array of integers, and "c_aa__slinkName__cLinkAbbrev" would refer to a static associative array (alias "map" or "dictionary") mapping string link names to their character abbreviations.
- A variable that ends with "_Env" is an environment variable that can be directly changed by the end user, e.g. via a shell-like interpreter provided by the software.
- For other uses of '_', "___" (3 consecutive '_') may be used. E.g., "doIndent1stVal___new" may be used instead of "doIndent1stVal2" to highlight that the variable "doIndent1stVal___new" contains an updated version of what "doIndent1stVal" contained.
PP_2.2.4: using prefixes in
each variable name (or, '_' separated variable name part that specifies a
member/property/sub-element) for indicating the type of this variable (or part)
(for the reader to know this type without having to re-access
– or memorize – variable declarations).
The ending of a prefix may be the ending of the name, a number, a '_' or
“an uppercase characters after some lowercase characters”.
Whether a typed language is used or not, i.e. whether types are also formally declared or not,
using such prefixes eases the understanding of the code.
When the used language is not typed, using such prefixes often avoid having to use comments
(e.g. comments directly or indirectly specifying types of variables).
This PP is not contradictory with PP_2.1.2.1
(not directly relying on particular data types/structures), as explained in the above description
of that PP. It should also be noted that using data structures that represent generic
"knowledge representations" is ideal for genericity and interoperability purposes.
The following box contains a list of useful prefixes (if the programmer use other ones, they
should be listed in the program header or in a document referred to in the program header).
Box 1: List of Prefix Examples For Common Types.
Below, various prefixes are proposed for various types of objects and
these types are organized into an indented list that show their subtype relations.
When type names from Javascript (JS), C or C++ could be reused below, they are: they are within
single quotes ('...'), JS/C++ class names have an uppercase initial, C type names have a
lowercase initial (except for 'FILE'). The other type names are whithin double quotes ("...").
The type names in bold characters are the JS types reused in
JSON and JSON-LD.
Prefixes for the most precise types should be used (hence, for example, the prefix "num"
should not be used if the prefix "int" can be used).
"Anything" (any information object, whichever their type): "x" ("e"|"elem" is for objects) "PrimitiveObject" (object of a basic/built-in data type): "builtin" 'Symbol': "symbol", "symb" "type" (type) "PrimitiveValue" (literal or not, e.g. a Primitive in JS): "v", "val", "value" 'Number': "nr" //warning: "n", "nb" and "num" are for Naturals; see below "nru" (unsigned, i.e. >=0), "nrp" (positive: >0), "nr32"|"nr4b"|"fl" ('float': floating-point number of at least 32 bits (3 bytes)) "nr64"|"n8b"|"d" ('double': floating-point number of at least 64 bits (8 bytes)) "dl" ('long double': generally 10 to 12 bytes; see en.cppreference.com/w/cpp/language/types) "n64u" (unsigned n64), "flp" (positive float) 'int': "zi", "int" (16 or 32 bits on a 32-bit system), "szi" (short int: 16 bits) "zil" ('long int': n bits on a n-bit system) "zill" ('long long int': 64 bits on a 32/64-bit system) "zib" (JS BigInt: used in JS to represent arbitrary large integer, those ≥ 253) "enum": "enum" (e.g. std::byte) or as for int/uint/... "int>=-1": "i" (to follow by a number; do not use "j", "k"), "index", "lastIndex", "fromIndex", "toIndex" (esp. for Get-from/Generate-from fcts) 'size-t' ("usize"): "zu", "size", "lng", "length", "uIndex", "uindex", "depth" (+ "num") //note: these prefixes may be preceded by "min" or "max" 'uint' ("natural"): "ui", "uint", "nat", "n" (+ "nb" but long and ambiguous for some) "natural>0": "ordinal", "ord", "nbp", "ip" (cf. prefixes 'p' and 'u' and 'nr' above) "nb16"|"nb2b" (natural on 4 bytes), "nb32"|"nb4b" (natural on 4 bytes) 'byte' ([0 to 255]): "uc", "ui1b" //since "cu" is for "update cursor" (see below) "Truth-value/Boolean-like" ('bool', O12, O123): "b", "b012" "b0123", "o123", "with", "has", "is", "are", "can", "may", "must", "no", "do", "use", "via", "as", "for", "in", "within", "equal", "caseEqual", "only", "maybe" 'char': "c", "char", "cz" ([-127 to 127]), "uc" ([0 to 255]), "cs1" (string of length 1, as in JS) "NonPrimitiveObject" (object of composite type or abstract data type, e.g. a "JS Object"): "o", "obj", "e","elem" (if collection item or document element; event: oEvent) "k" (knowledge representation object), "ko" //immutability (read-only) (if not the default option) may also be specified (e.g. "or") and used // since it allows safer, simpler and sometimes quicker functions; see also this in C++ 'union': "u" //except for "uc" ("unsigned char") 'Function': "fct", "f" //see Box 2 (below) 'FILE': "fi", "fp" (file pointer, "pof" is also ok) //but "ifd": int "file descriptor"; see std::filesystem too) "ReferenceObject" "AtomicReference": "p" (object that is an in-memory pointer or would be if translated in C++), "rp" (object that is a C++ reference or would be if translated in C++), "rpr" (read-only "rp", i.e. the value cannot change), "rpro" (const "rp" on an object) "IdReferenceObj" (-> id/key or mainly including that): "r", ro", "rid" //but "StringIdForAnObject": "sid" "Iterator" (function/pointer/... to traverse a collection, e.g. std::iterator) "Cursor" (to traverse/point to an object/collection, esp. in a DB): "cur", "cu"(read cursor), "cu"(update cursor) "Collection" (e.g. C++ container): "coll", "collv" (for a "view": collection of items/references, each removed when what is pointed to is removed (e.g. garbage collected), e.g. std::span); all collections are or can be iterable (not "enumerable") "Sequence": "seq", "stack" (std::stack), "queue" (std::queue), "queueWpriority" (std::priority_queue") "List" (non-numerically indexed sequence): "list", "lst", "li" "SingleLinkedList" (forward-only, e.g. std::forward_list): "lif" "DoubleLinkedList" (forward+backward, e.g. std::list): "lifb", "lifbqueue" (std::deque) 'Array' (-> numerically indexed): "a", "ar", "arr", "subArr", "table" "as" (static: fixed-size), "ad" (dynamic, hence a "vector") "ab" (array/view for a blob, i.e. for a binary large object) "aspan" (span: view on an interval on another array) "ArrayOfHeterogeneousValues" "Tuple" (fixed-size, e.g. std::tuple, std::pair): "tup", "tuple", "pair", "triple" "ArrayOfHomogeneousValues" (e.g. std:array, std::vector) "NullTerminatedArray": "a0" ("sc" or "sa" if C-like string) "StringOrCharPointer": "s"/"str" (<=> "sc" in a C program, "ds/dstr"/"string" in a JS program, ...), ("1st"/"2nd"/...)("sub")("str"/"name"/"word"/"w"/"text"/"token"), "to"("Locale")("String"/"Print") (for Get-from/Generate-from fcts); with "csti" (see above): "si", "stri" "Cstring": "sc" (non-allocated C-like string pointer), "sa" (allocated C-like char array); with "csti" (see above): "sci", "sai" 'String' (dynamic; with a size/length attribute): "ds", "dstr", "string" "StringView" (e.g. std::string_view): "strv"; with "csti": "dsi", ... "KeyedCollection" "Multimap" (associative array that may store the same key several times, e.g. C++ std::map): "mapm" 'Map' (e.g. C++ std::map): "aa", "aah" (map based on an hash-table) "MapView" (or 'WeakMap') : "aav" (stores 'key/referenceToValue' items; see "view" above) "Multiset" ("Bag", e.g. C++ std::multiset): "setm", "bag", "bagh" (bag based on an hash-table) 'Set' (e.g. C++ std::set): "set", "seth" (set based on an hash-table) "SetView" (or 'WeakSet'): "setv" (stores 'referenceToValue's; see "view" above) "Graph": "graph" "Tree" (connected acyclic graph; generally "undirected" in math and directed in data structures): "tree" "Heap" (std:make_heap): "heap" |
2.3. Function Names and Parameters (PP_2.3: using good function names+parameters)
PP_2.3.1: using either methods (hence the O.O. approach) or "pseudo-methods" (normal functions that mimic the O.O. approach). The O.O. approach has modularization advantages. Furthermore, this approach generally leads to method names that are shorter and more normalized than normal function names since the class to which a method is associated (its first genuine parameter) is already explicit and hence is never referred to in a method name. When using the O.O. paradigm is impossible (e.g., because the target language does not support it) or insufficient (details further below), this paradigm can be mimicked with normal functions, which are then here called "pseudo-methods":
- Instead of associating a method of name M to a class of name C, a pseudo_method of name C_M can be written (and, now, C is actually not restricted to be a class name, it can be any type name). E.g.: the counterpart function of the method “lastCharacter” of the class String would be named “String_lastCharacter”. This mimicking does not have all the advantages of a genuine O.O. approach (e.g., no inheritance and no encapsulation) but is as normalizing.
- Some O.O. approaches/languages (e.g. CLOS, the
Common Lisp Object System)
support multiple dispatch for
functions and methods (which are then named "multimethods"): the function or method is
dynamically dispatched based on the run-time (dynamic) type or, in the more general case,
some other attribute of more than one of its arguments.
To name a pseudo-multimethod mimicking a multimethod M "shared" (in the sense just described) by two classes C1 and C2, the form C1__C2_M may be used. Here, the use of "__" (two '_') is advocated to avoid an interpretation rule clash with the convention given in PP_2.3.7 (which advocates a second use of '_' in a method name to denote a part relation, as in "C1_attributeOfC1_methodOnAttributeOfC1").
Using a pseudo-method is particularly useful for associating a function to several classes that cannot be modified, without having to introduce a superclass for these classes and then having to create instances of this superclass. E.g., the pseudo-method "str_toNumber" can be implemented i) in Javascript as having an object of class String as first parameter, and ii) in C++, as having a char pointer as first parameter (and, since C++ supports polymorphism, it can also be implemented as having an instance of the C++ standard library class "string" as first parameter). Thus, pseudo-methods are particularly useful to use the same functions for different implementations of collections (strings, arrays, ...) and functions, whether they are class instances or not (e.g. functions: they are class instances in Javascript but not in C++).
PP_2.3.2: specifying the types of parameters. In many interpreted languages, parameters – or, more generally, variables – are not typed, and hence not type checked. This is detrimental since static or dynamic type checking often permit the detection of many errors. When variable uses are not checked statically, i.e. at compilation time, an easy way to check that the content of most variables comply to their types is to check these types via dynamic types checks of parameters, since most variables are used in functions. PP_2.3.3 provides more details. As noted in PP_2.1.1.3, there are at least two non-exclusive ways to do specify variable types in a non (fully) formal way: i) using comments, e.g., by prefixing each parameter with its type within parameters, and ii) using special prefixes in variable names, as illustrated in PP_2.2.
PP_2.3.3: checking the types of parameters via function preconditions and postconditions when not all check may be performed statically. The rationale for the dynamic checking of parameters (when it is not fully done statically) have been given by the previous paragraph. Even when static checks occurs, some constraints sometimes cannot be expressed via types (e.g., interval-based value ranges) and then can be checked via dynamic type checks of parameters. To do so, each function may call a type-checking function to check its parameters and, in its return value statements, also call a type-checking function. These precondition and post-condition functions may also be used as aspect-oriented programming (AOP) devices: these functions may retrieve and check preconditions and post-conditions that users have associated to functions.
PP_2.3.4: besides their types, giving as many other precisions about the parameters, e.g., whether they are i) “in” (alias, “inP” or “constP”), “in-out” (alias, “varP”) or “out” (alias, “outP”), ii) created/allocated or freed by the function, and iii) lazy-evaluated or not.
PP_2.3.5: using functions that have no
side effect other than
via the modification of their “in-out” parameter(s) which should be their first
parameter or their last parameters (return value not included).
Indeed, in an actual or simulated O.O. approach, the function is a method and its first
parameter is the object that the method is associated to and, possibly, modify.
Apart from the first parameter in this last case, the “in-out” parameter(s) must
be specified as such via prefixes (e.g. "io" or "varP"; cf. previous PP and
PP_2.2.3).
- Underlying idea. A pure function does not have side effects and hence, for example, only has “in” parameters (again, excluding the return value). To mimic side effects via pure functions (and still support function composability) pure functional languages for example propose the use of monads. An idea related to monads is that “if, besides local variables, each function in a thread only modifies some parameter(s) that are – or could easily be – used as (or aggregated into) the return value of the function, this function can be easily represented into a pure functional language”.
- Case of functions that are methods. With a method, instead of an explicit aggregation of modified parameters into the return value, if the modified parameters are part of – or referred by – the object on which this method is called, function composability can be indirectly achieved by using the same modified object(s) in later function/method calls (indeed, pure functions can be chained if they return the object that they modify or if they return this object and an additional return value by aggregating both of them). More intuitively, this means that all objects used as modified parameters should i) be part of – or referred by – a same “Environment” object which in pure functional language can be transformed into a monad, and ii) refer to this Environment” object which then is (directly or indirectly) the global object/monad modified by all method/functions. In theory, to avoid genuine modifications, only a modified copy may be returned by a pure function but, in a chain of functions, directly modifying and returning the same object is not problematic for keeping the advantages of pure functions.
- Conclusion: this is a a way to normalize functions and ease their understanding
as well as their translation to pure functions.
Although a function modifying many parameters could be translated into a pure function that
aggregate and return (copies of) the modified parameters, the restriction (PP) of
modifying only the first and/or last parameter of functions
– with the additional conventions that
i) the function is then an actual or simulated method for this first parameter, and
ii) the function returns this last modified parameters if it is different from the
first – ease
- the translation of the program into a purely functional language, and
- the understanding of these functions by people (they know exactly which parameters are modified and how they are returned).
PP_2.3.5.1: the
previous PP is especially useful to do functional-like programming (without memory leasks)
with a language that does not rely on a garbage collector (e.g. with C, unlike Java or JS
which have such a garbage collector):
indeed, with such a language, a function should not allocate memory for
returning an object, it should instead initialize or modify its last parameter and return it.
Thus, the stack can be used (by a calling function) instead of the heap.
PP_2.3.5.2: never directly allocating (and de-allocating)
memory (e.g., using "new" or "mallow" (and "delete" or "free") but using
- when possible, "Resource acquisition is initialization" (RAII) techniques, using local variables or "smart pointers", or
- intermediary functions that enable the centralization (and hence the control of) calls to
memory allocation/de-allocation;
- for an allocation, such a function should rather be a static method (preferably named "make" or "mk", and "delete" or "del") of the class of the allocated objec; this methods calls the constructor of this class;
- for a de-allocation, such a function should rather be a method that calls the destructor of the soon-to-be de-allocated object.
PP_2.3.6: mainly using the InterCap/CamelCase naming style (for functions and variables) since it is concise and allows the separators "_" and "__" to have special meanings (see the following PPs; note: in most programming languages, identifiers characters can only be 'a'..'z', 'A'..'Z','0'..'9' and '_', so '-' is generally not a usable character, only '_' is).
PP_2.3.7: using a “method naming convention” that indicates at least the following information, in that order (and in a distinguishable way, e.g., separated by “_”, “__” or “___”; note: if “_” is used as delimiter within one of the following pieces of information, e.g. the 3rd or 5th one in the following list, “_” cannot be used as delimiter between the pieces of information, “__” or “___” can be used instead):
- if the method is a class method (hence not an "object member method"), an indication that it is, e.g. via the prefix "cl" (as in "cl_restOfTheNameOfThisClassMethod");
- if the method is asynchronous (e.g. is a co-routine or can be lazily-evaluated), an indication of which kind, e.g. "gener" for a
generator, "task" for a task, "thread" for a thread, and, more generally, "async" for an
"asynchronous evaluation" and/or "deferrable" for a
"lazy evaluation";
the "parallel execution policies may also be made explicit via keywords such as "seq" ("sequentially"), "par" ("parallel") and "parUnseq" ("parallel unsequenced"); - each (kind of) additional important mandatory parameter
(prefixed by "__" instead of "_" if this last one has just/already been used in the
name to express a sub-object/attribute/method relationship; cf. the last sub-point below);
reminders:
- if the O.O. '.' is usable just before the name (this is preferable), the function is a method and the 1st parameter is the object that has this method but is not described in the method name;
- if not, when possible, it is preferable to normalize the function name by simulating the O.O. approach: the 1st described parameter is also the 1st actual parameter, it is the object that would have the method if the function was a method;
- in this document, the return value of the function is considered as its last parameter;
- for each described parameter,
- the O.O. approach can also be simulated (but this is rarely needed) : after a '-' (or the '.' for the 1st parameter in an O.O. approach), a sub-object/attribute can be described (if it is more relevant/precise for the function than the whole described parameter; then, for separating parameter descriptions, "__" must be used instead of "_" in order to avoid ambiguities;
- the "prefixes for variables" (see PP_2.2.4) should be used here too but, to avoid ambiguities, not the "_" or "__" of PP_2.2.3 – instead, postfixes (such as "Array", instead of the form "a__") should be used (as in the function name "elemArray_setEachAsHighlighted");
- a description of the (kind of) performed operation
(and, via a prefix/suffix, of the returned value, if there is one and if it has not already been described)
via names such as the following reserved ones
(notes:- the description of the performed operation should be anambiguously distinguished by the use of the reserved names or because there is not other mandatory parameter besides the return value;
- to specify the return value, these names may themselves have
– or, in the case of get and mk (since they are often not needed when the
return value is specified), even be replaced by – a
- prefix that is a camel-case expression the first part of which is a "type specifying prefix" such as those for variables: cf. Section 2.2), or
- suffix which is a class name or, if separated by "-", an expression complying to the
variable name conventions,
as in "Object.cl_obj_mk_a__sKey(obj)" to create the array of keys of obj;
if "mk" is used without prefix nor suffix, the return value is of the type of the first parameter;
if "get" is used without prefix nor suffix, the return value is of the type of the previous described part if it is a described sub-object/attribute, otherwise the name is not well-formed;
- for make/get/generate-from methods that do not modify the object:
- “mk” (alias “make”, “create”) “mkTo” (or simply “to”);
- “get”, “to”; the following ones may seem interesting but, in case of ambiguity, should not be used alone (i.e., without registered keywords such as "get" or "to") since they can also be used as prefixes specifying the type of a mandatory parameter: “indexOf”, “at” (alias “getAtIndex”), “nb” (alias “getNbOccurrencesOf”);
- “cpSetAt” (alias “iSetAt” or “immutableSetAt”);
- “cpReplEach” (alias “iReplEach” or “immutableReplaceEachOccurrenceOf”);
- “cpAppend” (alias “copyAndAppend”, “immutableAppend”);
- “cpDelAt” (alias “copyAndDeleteAt”, “immutableDelAt”);
- for set/transform/delete methods:
- “setAt” (alias “mutableSetAt” or “mSetAt”);
- “setAppend (alias “addAtEnd” or “mAddAtEnd”);
- “replAt” (alias “mReplAt”), “repl” (alias “replBy” or simply “mv”);
- “delAt” (alias “rmAt”), “setDelLast” (alias “rmLastOccurrenceOf”);
- test methods begin by “is” (or “are”) or “has” (or “are”) or “if”;
- prefixed by "___" (or "__" if there is no ambiguity), each additional important mandatory parameter.
Box 2: Examples of Function Normalization.
Here are examples of normalized names for methods from Javascript classes such as
Number,
String,
Array and
Object.
(The main constructors of these classes are not included in the list below
since they have the name of these classes and hence are already normalized.)
The parameter descriptions used in the pointed Web sites for the three classes are kept.
These normalization examples show that the used conventions lead to
i) giving more precision,
ii) making similar functions have more similar names, and
iii) making explicit distinctions between similarly named functions (e.g. see the
method named “entries”).
The methods listed below on the left sometimes generate exceptions (here is the list of their types). As implied by
PP_2.1.1.3, in Systematic Functional defensive programming (SFDP),
the methods listed below on the right
should not generate these exceptions or should catch them,
and should instead return an adequate error value.
Method name in Javascript Normalized name
|
Build/Mk(-this-(from)) / MkIterator / Iterate / Call
(regarding the returned value type, see the prefixes in Box 1, the next 2 rows and the comments)
----------------------------------- Build/Mk:
Number.parseInt(str,[radix]) Number.cl_str_intMk(str,[radix]) //"intMk"->int returned
Math.abs/cos/exp/...(number) Math.nr_nrAbs/nrCos/nrExp/...(number) //"nr" -> Number
Date.now() Date.cl_oDateForNow()
Date.parse(str) Date.cl_strToParse_mk(str) //"mk" -> Date returned
Date.UTC(int) Date.cl_nYearToUTC__nSecondsSince1970(int)
BigInt.asIntN(width,bigint) BigInt.cl_mkWith(width,bigint) //idem for asUintN
Object.create(proto,[ObjProperties]) Object.cl_oPrototype_mk(proto,[ObjProperties])
Object.fromEntries(iterable) Object.cl_oIterable_mk(iterable)
Object.entries(obj) Array.cl_obj_mk_aa__sKey__sValue(obj)
Number.parseInt(str,[radix]) Number.cl_str_intMk(str,[radix])
Object.keys(obj) Object.cl_obj_mk_a__sKey(obj)
Object.getOwnPropertyNames(obj) Object.cl_obj_mk_a__sNonInheritedProperty(obj)
String.fromCharCode(num1[,...[, numN]]) String.cl_mkFromUTF16codes(num1[,...[, numN]])
String.fromCodePoint(num1[,...[, numN]]) String.cl_mkFromCodePoints(num1[,...[, numN]])
Array.from(arrayLike[,mapFn[,thisArg]]) Array.cl_mkByCp1stLevelOf(arrayLike[,mapFn[,thisArg]])
Array.of(elem0[,elem1[,...[,elemN]]]) Array.cl_mkWith(elem0[,elem1[,...[,elemN]]])
----------------------------------- MkIterator:
Array.keys() Array.mk_oKeyArrayIterator() //idem for values
Array.entries() Array.mk_okeyValuePairIterator()
----------------------------------- Iterate:
Array.some(fct[,thisArg]) Array.fct_isForSome(fct[,thisArg]) //"is" -> boolean
Array.every(fct[,thisArg]) Array.fct_isForEach(fct[,thisArg])
Array.forEach(fct[,thisArg]) Array.fct_doOnEach(fct[,thisArg]) //this method may modify the array!
Array.reduce(fct[,thisArg]) Array.fct_aggregateFromEach|reduce(fct[,thisArg]) //(no modif)
Array.reduceRight(fct[,thisArg]) Array.fct_aggregateFromEachFromEnd(fct[,thisArg]) //|fold|raccumulate
Array.map(fct[,thisArg]) Array.fct_cpDoOnEach|map(fct[,thisArg])
Array.flatMap(fct[,thisArg]) Array.fct_cpDoOnEachThenFlat|mapThenFlat(fct[,thisArg])
Array.filter(fct[,thisArg]) Array.fct_cpDoOnEachSatisfying(fct[,thisArg])
Array.find(fct[,thisArg]) Array.fct_at1stSatisfying(fct[,thisArg])
Array.findIndex(fct[,thisArg]) Array.fct_indexOf1stSatisfying(fct[,thisArg])
----------------------------------- Call:
Fct.call(thisArg[, arg1, arg2, ...argN] ) Fct.callWithArgs(thisArg,[argsArray])
Fct.apply(thisArg,[argsArray]) Fct.callWithArgArray(thisArg,[argsArray])
Fct.bind(thisArg,[argsArray]) Fct.mk(thisArg,[argsArray])
|
Test (the returned value type is a boolean/integer/...)
(same prefixes as in the previous "box"; e.g., for booleans: "is", "has", "do", ...)
Number.isNaN/isFinite/is(Safe)Integer(value) Number.cl_x_isNaN/...(value)
Array.isArray(value) Array.cl_x_isArray(value)
Object.is(value1,value2) Object.cl_x_isIdenticalTo(value1,value2)
String.includes(searchString[,position]) String.sSearchedSubstr_isAt(searchString[,position])
Array.includes(valueToFind[,fromIndex]) Array.aSearchedSubArr_isAt(valueToFind[,fromIndex])
String.startsWith(searchString[,length]) String.substr_isStartingIt(searchString[,length])
String.endsWith(searchString[,length]) String.substr_isEndingIt(searchString[,length])
String.localeCompare(compareString[,locale]) String.str_iNumForDiffInLocale(compareString[,locale])
|
(Use/Do/Handle /) Get-from / Generate-from(toString,toPrint,...,cpAppend,cpReplace,...)
(the returned value type is either explicit from the selected part and/or action, or is the same as the class)
----------------------------------- Get-from
String.charAt(index) String.getCharAt(index) //or: String.index_charAt
String.charCodeAt(index) String.getCharForUTF16(index) //or: String.UTF16_charFor
String.indexOf(searchValue[,fromIndex]) String.sSearchedSubstr_index(searchValue[,fromIndex])
Array.indexOf(searchElement[,fromIndex]) Array.xSearchedElem_index(searchElement[,fromIndex])
String.lastIndexOf(searchValue[,fromIndex]) String.sSearchedSubstr_lastIndex(searchValue[,fromIndex])
Array.lastIndexOf(searchElement[,fromIndex]) Array.xSearchedElem_lastIndex(searchElement[,fromIndex])
String.search(regexp) String.regexpForSubstr_indexOfSubstr(regexp)
String.slice(fromIndex[,toIndex]) String.fromIndexOfSubstr_cp(fromIndex[,toIndex])
Array.slice(fromIndex[,toIndex]) Array.iSubArr_cp1stLevelAt(fromIndex[,toIndex])
String.substr(fromIndex[,length]) String.iSubstr_cpAt(fromIndex[,length])
String.substring(fromIndex[,toIndex]) String.iSubstr_cpAt(fromIndex[,toIndex])
AA_VarValue.sVar__pxValue_toString(const char*) AA_VarValue.sVar_pxValue(const char*)//->T*
----------------------------------- Generate-from (last: the cpAndModify):
Date.getDate/getTime/toJSON...() Date.toIntDate/toIntTime/toJSON...()
Number/BigInt/Boolean.valueOf() Number/BigInt/Boolean.toValue()
BigInt/Number/Fct/Array.toString() Array/....toString() //so, toString and toPrint should exist or
Array.join([separator]) Array.toStrWith[separator]) // be automatically derivable
BigInt/Number/Array.toLocaleString([loc[,opts]]) Array/....toLocaleString([locales[,options]])
Number.toPrecision/toExponential/toFixed Number.toStrWithPrecision/...
Array.flat([depth]) Array.cpFlattenedTill([depth])
String.split([separator[,limit]]) String.cpSplit__strArray([separator[,limit]])
String.concat(str2[,...strN]) String.cpAppend(str2[, ...strN])
Array.concat([value1[,...valueN]]) Array.cpAppend([value1[,...valueN]])
String.repeat(count) String.cpAppendNtimesToItsef(count)
String.padEnd(targetLength[,padString]) String.cpAppendPaddingIfNeededToReach(targetLength[,padString])
String.padStart(targetLength[,padString]) String.cpPrependPaddingIfNeededToReach(targetLength[,padString])
String.normalize([form]) String.cpReplEachCharByItsUnicodeNormalizedValue([form])
String.toLocaleLowerCase([locale,...]) String.cpReplEachCharByItsLowerCaseInLocale([locale,...])
String.match(regexp) String.toArrayOfStringsMatching(regexp)
String.matchAll(regexp) String.toIteratorForStringsMatching(regexp)
String.replace(regexp|substr,newSubstr|fct) String.cpReplace1st(substr,newSubstr|fct)
String.cpReplace(regexp,newSubstr|fct)
String.replaceAll(regexp|substr,newSubstr|fct) String.cpReplaceAll(regexp|substr,newSubstr|fct)
String.trim() String.cpDelWhiteSpacesAtBeginningAndEnd()
Array.copyWithin(target[,start[,end]]) Array.cpReplaceAt1stLevel(target[,start[,end]])
|
Set / Replace / Delete ('m' prefix: “modify”, alias “mutate”)
(the returned value is (a pointer to) the one of the set/replaced/deleted element; null/NULL if error)
----------------------------------- Set:
Date.setDate/setTime/...() Date.setWithIntDate/setWithIntTime/...()
----------------------------------- Replace:
Array.fill(value[,start[,end]]) Array.setEachElemTo(value[,start[,end]])
Array.unshift(element1[,...[,elementN]])) Array.mPrepend()
Array.push([element1[, ...[, elementN]]]) Array.mAppend([element1[, ...[, elementN]]])
Array.reverse() Array.mReverse()
Array.sort([compareFunction]) Array.mSort([compareFunction])
Array.splice(start[,delCount[,item1[,...]]]) Array.elems_setOrDel(start[,delCount[,item1[,...]]])
AA_VarValue.sVar_pxValue_addOrUpdate(const char*,const char*)
----------------------------------- Delete:
Array.shift() Array.firstElem_del()
Array.pop() Array.lastElem_del()
|
PP_2.3.8:
(in accordance with PP_2.3.6 and the O.O. based approach advocated by
PP_2.3.1)
naming “pseudo-methods” by
- prefixing them with the type of their first parameter (or types of their first two parameters – separated by '-' – to specify that the function is associated to 2 types; see the second bullet of PP_2.3.1 for details), followed by '_", and then
- using the conventions given and illustrated by the previous PP
(PP_2.3.7).
E.g., a function equivalent to the method “String.substr_isAt” would be named “String_substr_isAt”.
2.4. Other Names: File Names, XML Names, ...
PP_2.4.1: using the same conventions for file names as for variable names (cf. previous subsection; → only using a-z, A-Z, 0-9, '_' and '-', hence not using spaces and accentuated character; this eases the retrieval and handling of file name via scripts) and beginning non-directory file names by a lowercase character.
PP_2.4.2: using the same conventions for markup names as for variable names (cf. previous subsection) and, for individuals (types instances that are not types, e.g. HTML form element identifiers), prefix/suffix them with an abbreviation of their types. Here are examples of prefixes/suffixes:
- “Input” for an Input element of type Text or Password
- “Hidden” for an Input element of type Hidden
- “Choice” for an Input element of type Radio
- “Selection” for a Select element
Examples of their use: “addressInput”, “passwordInput”, “transmissionChoice”.
2.5. About Documentations
PP_2.5.1: for each file, giving
at least the following information in its header, via comments and/or using more formal
ways:
- creator: name, identifier+contacts (URL, e-mail, ...);
- creation date;
- purpose of the content of the file and what remains to be done wrt. this purpose;
- ways to use or test the file, e.g. description of its inputs and outpouts
(e.g. parameters, identifiers of input/test files) if it has some;
- ways the content has been tested/validated.
- PP_2.5.1.1: beginning an HTML document
at least by the following information and other relevant uses of the meta types and link types
(see also this example list):
<!DOCTYPE html> <html lang="en-US"> <!‐- or another language ‐-> <head><title>Document title/purpose here</title> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"><!‐- or: iso-8859-1, ... ‐-> <meta name="Author" content="http://someHomePageURL"> <!‐- or some other identifiers/contacts ‐-> <meta name="description" content='bla...'> <link rel="start" href="http://someHomePageURL">
Complying with line size limits (e.g. PP_3.1.2: using lines of no more than ... characters) is eased by- adding a line like the following one near the top of the HTML file:
<!-- in this text editor, this comment is as large as 79 characters outside a comment -->
indeed, with such a line, the width of the window for the text editor can be easily adjusted so that larger lines cause line wrappings, hence noticeable cues that the chosen PP is not complied to; - when a big screen is used (as opposed to a smartphone, for example),
- using an absolute width (and justified lines) for the text of the document (as in this one), or
- underlying the displayed title/header by a line like the following one):
_____________________________________________________________________________________________
indeed, with such a line or absolute width, the width of the window for the browser can then be easily manuually adjusted so that larger lines cause an horizontal scroller to appear, hence noticeable cues that the chosen PP is not complied to.
- adding a line like the following one near the top of the HTML file:
/* in this text editor, this comment is currently as large as 83 characters outside comments */
2.6. About Inputs and Outputs: User Interfaces, ...
PP_2.6.1: distinguishing the content, structure and presentation of information, as well as their handlings, and letting the user choose or parameter these 3 aspects and their handlings, while not forcing the user to make choices nor (re-)enter information (thus, this PP specializes PP_1.1). Furthermore, what can be decentralized on the user's machine should be (PP_2.1.4.4) and, more generally, all the media/devices/... that can be exploited should be (PP_1.2.2). Example sub-PPs:
- PP_2.6.1: using non-textual elements (images, animations, movies) only if i) their content cannot be as clearly expressed in a textual way, ii) their textual alternative has also been proposed.
- PP_2.6.2: using copy-pastable elements whenever possible, e.g. text/XML/SVG elements instead of images.
- PP_2.6.3: not forcing the user to (re-)enter information when this can be avoided. E.g., values in the last relevant query or form should be provided as default values in the current query or form. Default choices shoud always be provided and be modifiable by the user.
- PP_2.6.4: not forcing the user to know or choose identifiers, e.g. Web site addresses or record identifiers. First, unique identifiers can (and often should) be automatically generated. Second, information search can be supported via queries and navigation. Third, information storage at the right place can be supported via search or automatic replications/distributions.
- PP_2.6.5: always allowing users to chose between alternatives, e.g. the GET protocol and the POST protocol (PP_2.1.5.2.1).
- PP_2.6.6: letting each displayed piece of information be the source of i) at least at an hyperlink that leads to an organized gathering of information about this piece, or ii) better, a cascading menu that permits the user to access/search (by navigation and querying) not only to that kind of information but also to set/modify its contents and the way it is displayed for this user (idem for the menu itself). Ideally, the information are stored in a KB and the hyperlinks/menus supports the navigation in the KB along the semantic relations between the pieces of information.
- PP_2.6.7: displaying the results of a query not just in a flat list but in a way that is organized by the semantic relations between the results, typically specialization relations.
3. Non-Structural/Lexical PPs (→ Programming Style)
3.1. Size/Space/Indentation Related PPs
PP_3.1.1: using a compact style (→ concision when this does not conflict with
explicitness; this presentation PP has no consequence on
structural/lexical PPs and hence on the length of function/variable names for which PPs
where given in Section 2.2 and Section 2.3).
Since the short-term memory of
most people is very limited, functions should be as short as possible for people to see as much
of them without scrolling and thus understand and compare them easily. In other words,
the more code the reader can see and compare at a glance (i.e., without scrolling), the better.
If scrolling is necessary, debugging or reuse time is greatly increased. PP_3.1.2: using lines of no more than PP_3.1.3: using a space after the function name in its definition, never when in its
calls (this eases lexical searches of function definitions in programs with many modules).
PP_3.1.4: aligning block delimiters, e.g. the '{' '}' brackets,
vertically or horizontally, e.g, as in the GNU style.
This is a specialization of the
Horstmann style
(it is equivalent to the
Allman style
– alias BSD style – when the '{' is alone on a line, which is to avoid
since this is a useless loss of space).
However, there is no need to indent the direct sub-elements of the HTML tag
(e.g., HEAD and BODY) nor their direct sub-elements (e.g., STYLE, SCRIPT, P, H1 ...H5). PP_3.1.5: within an If-Then-Else statement, putting the smaller block first.
PP_3.1.6: when '=' is the operator for assignments, not using 1 space before,
i.e. writting them as in "i= 1;" or "i=1;", never like "i = 1;",
since this wastes space and ressembles too much equality tests ("i==1").
When an assignment is used within a test (as in “if ((n= 2)) then ” or
“if (!(n= 2)) then ”), put a space after the '=' and use two sets of parenthesis.
C/C++ compilers enforce this.
PP_3.1.7: using 1 space before and after a single '=' used for an equality test.
Here is an example sub-PP:
– 79 characters if this does not make the code harder to read,
– 83 characters for lines that do not include any comment, and
– 95 characters otherwise.
Indeed, lines should remain readable – hence without line wrapping or the use of an
horizontal scroll bar – wherever/however it may commonly be displayed, e.g.,
on a small screen, or using a 12-point, or in a pure text e-mail (in such emails, lines over
79 characters are often automatically line wrapped; gmail wraps at 70 characters or
sometimes till 83 characters if a word has begun before the 70-character limit;
here are some notes on the optimal line length for non-code text).
PP_2.5.1 shows how the program header can be adapted to ease complying with
such a PP.
Note: other styles for curly braces are less symmetric and hence less readable (← less
helpful to find block delimiters) but this is a matter of taste and there is no information
loss is using one style or another since they can all be automaticaly generated.
Box 3: Example 1 About Indentations.
Comparaison of two ways of indenting a same function.
The left one is clearly better for
readability or understanding purposes but still has 7 kinds of
presentation problems
(4 regarding indentation/spacing) wrt. the above listed PPs.
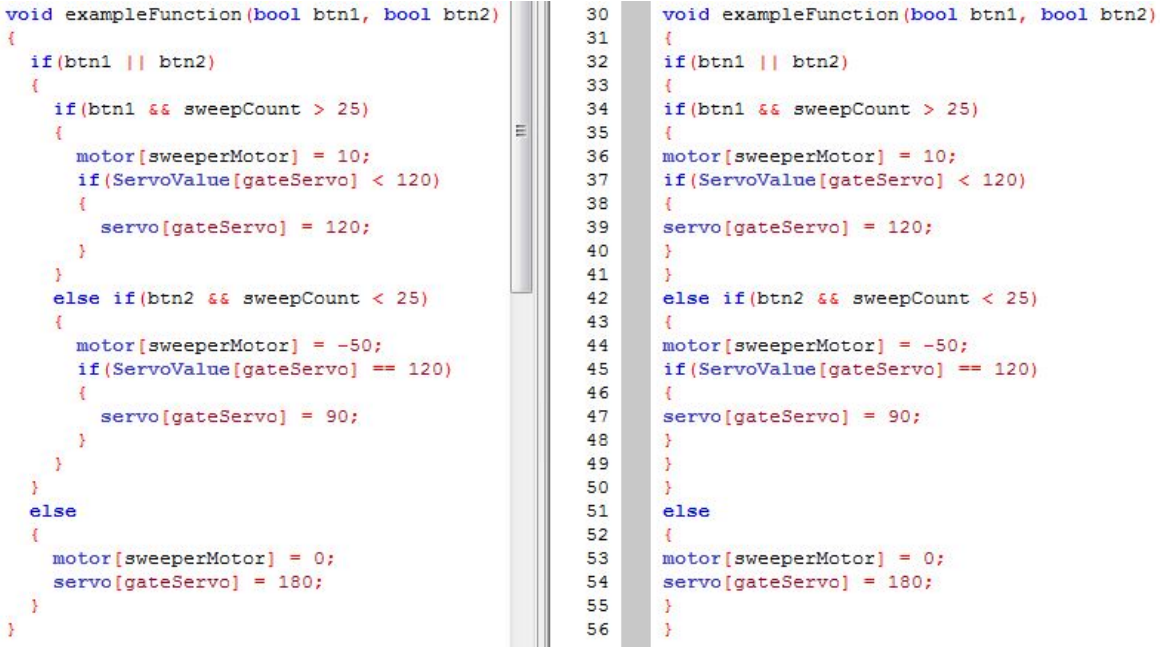
Box 4: Example 2 About Indentations. Case-by-case examples
using the Javascript syntax.
The bad/good "if" examples are also bad/good examples for
any other kind of block: "while", "for",
"function", "<td>", etc.
BAD
BETTER (for above cited reasons/criteria) prErr ("...");prErr("...");function someFct()
function someFct ()
a = 1;
a= 1;
if(a==1) ...
if (a==1) ...
if (a = b) ...
if ((a= b)) ...
if (!(a)) ...
if (!a) ...
if (a) { a= b; }if (a) a= b;
if (a){a=b; b=2;}if (a) { a= b; b= 2; }if (a) {
a= b; ...
}
if (a)
{ a= b; ...
}
if (a)
{
a= b; ...
}
if (a)
{ a= b; ...
}
if (a)
{
a= b; ...
}
if (a)
{ a= b; ...
}
if (a)
{a= b;
c= d;
}
if (a)
{ a= b;
c= d;
}
if (a)
{ a= b; ...
}
if (a)
{ a= b; ...
}
if (a)
{ a= b;
if (b) ...
}
if (a)
{ a= b;
if (b) ...
}
if (a)
{ a= b;
}
if (a)
{ a= b;
}
function someFct1 ()//...
{ ...
}
function someFct2 () //...
{ ...
}
function someFct1 () //...
{ ...
}
function someFct2 () //...
{ ...
}
function someFct(someNumber) {
if(result = someNumber + 1) {
prErr ('Some error message');
return result;
}
if(someNumber ==0)
{ result = 1; }
return result;
}
/*int*/function someFct (/*int*/someNumber)
{ /*int*/result= 0;
if (someNumber==0) result= 1;
else if ((result= someNumber + 1))
{ prErr('Some error message');
return result;
}
return result;
}
sub someSubroutineName
dim a
a = 8
while a > 1
a = a - 1
end while
end sub
sub someSubroutineName
dim a
a= 8
while a > 1
a= a - 1
end while
end sub
<table>
<tr><td>cell 1</td>
<td>cell 2</td>
</tr>
</table>
<table>
<tr><td>cell 1</td>
<td>cell 2</td>
</tr>
</table>