Plan
Need For a Semantic Network
The present: sharing, indexation and retrieval of contextual objects (i.e., data,
e.g., documents or document elements).
The future: manual or automatic sharing, indexation and retrieval of non-contextual
objects (i.e., formal or semi-formal knowledge: conceptual categories and statements)
and then their combination or presentation according to each user's information need,
knowledge and preferences.
This has always been the goal of the knowledge modelling and sharing community.
To support an efficient, precise, structured and complete Information Retrieval,
information has to be organised into a semantic network: a set of relations between
quantified conceptual categories, that is, a set of statements (a set of knowledge representations).
Need For a Semantic Network (Con't)
Examples of information needs (during learning, research, ...):
Centralization and Distribution
Nowadays, semantic relations cannot be automatically extracted from informal documents.
Setting semantic relations across documents (formal or not) lead to very poor semantic networks:
little guidance and checking can be offered.
Ideal condition for a scalable semantic organization:
a unique way and place to add a precise category or statement
(or a set of equivalent ways and places).
Requirement 1: one ontology
-> a cooperatively updated knowledge base (KB) with editing protocols
or a network of such KBs linked by cross-references and replication mechanisms between them
-----> it does not matter where queries/updates are made first
-----> in a peer-to-peer network: special replication mechanisms; on the Web: piggy-backing.
Principle: any KB contains all the knowledge related to its "objects of interest".
Thus, centralisation and distribution can be combined.
Centralization and Distribution (Con't)
A (consistent) KB can support people different terminologies and different beliefs.
Principles:
- each category identifier is prefixed by the identifier of its creator
- each statement must have a recorded source/creator (and source interpreter),
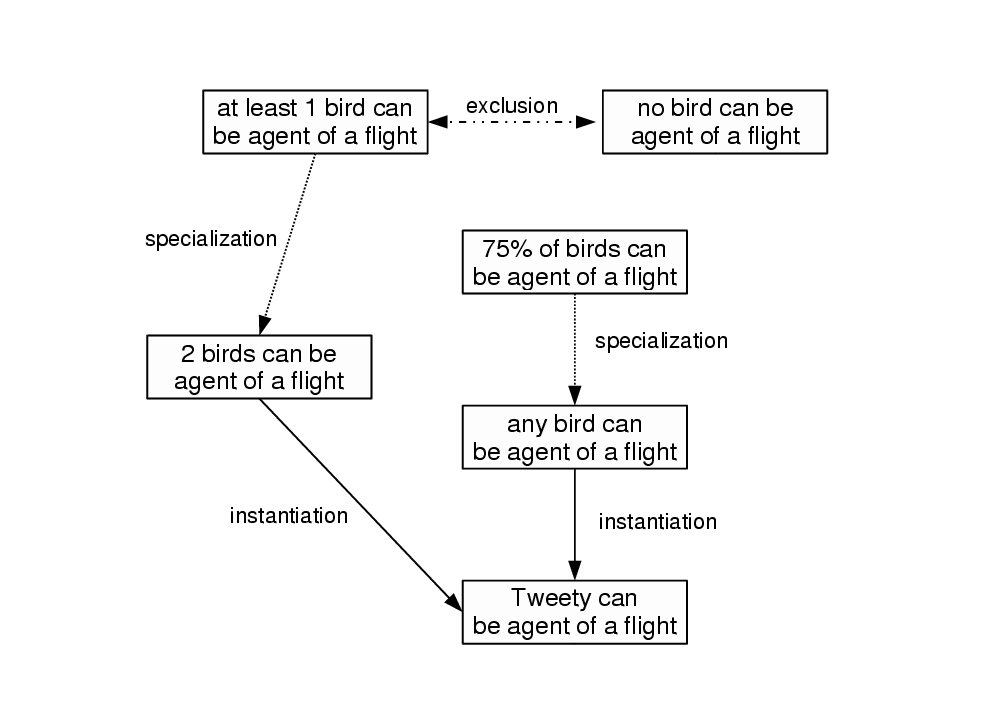
- redundancies/inconsistencies must be removed using correction/specialization relations, as in:
` `any bird is agent of a flight'(John) has for corrective_restriction
`most healthy French birds are able to be agent of a flight' '(Joe).
Requirement 2: a large lexical ontology and well organized domain ontology
Requirement 3: the following ontology design principles, for example:
- never use verb/adverb/adjective categories unless defined with respect to noun categories
- whenever possible, use singular nouns
- whenever possible, use "subtype" relations instead of "instance" relations
- whenever possible, use basic relations (especially transitive ones such as "subtask")
Relations such as "propose", "proposed_by" and "has_definition" are typical of small and
un-scalable schemas.
Semantically Structured Wikipedia/Courses/Newsgroups/Repositories Would Be Better
Some problems related to the lack of structure:
- difficulty to understand how objects are related and find related objects
- necessity to make choices about information ordering and levels of detail
- no update protocols, valuation/voting mechanisms, semantic query/navigation/filtering mechanisms
Nowadays: Wikipedia, courses, learning objects and domain repositories are not semantically structured
- Wikipedia has a minimal structure: it only permits to avoid many redundancies
- Semantic MediaWiki
and Wikipedia's extensions
(person DTD,
space-time DTD,
Metalingo) are insufficient
- current Learning Objects are informal packages of relations, nor relations
The more structured/formal the information, the better IR and KM can be. However,
- the more precise the authors must be (but shouldn't they?)
- the more time-consuming knowledge entering is (but no repetition/linearization)
- nowadays, people are not trained to see and use semantic relations and (semi-)formal notations
Semantically Structured Wikipedia/Courses/Newsgroups/Repositories Would Be Better (Con't)
Conclusion:
- more structure is worthwhile,
- there is no alternative,
- the way forward: cooperatively-built repositories with a semantic network structure where
relations must be formal but where nodes can be as small/large and formal/informal
as the users wish
(precise metadata on documents can be re-used for modelling relations).
Classic mistakes:
- allowing relation names to be any linguistic expression,
- restricting the expressivity of the notations accepted by a "general" system
- not allowing the users to add and use new concept/relation types (predefined ontology)
- not allowing the insertion of (semi-)formal statements within informal nodes/documents
Readable, Concise, Expressive and Normalising Notations
Readable, concise, expressive and normalising textual notations are necessary for
visualising, browsing and editing
realistic amounts of knowledge.
Graphic interfaces are a good complement but visualising a small amount of knowledge.
Most formal notations (KIF, RDF, ...) are not readable, expressive and normalising.
Examples without information on the creators of categories and statements:
En: Any human_body is a body and has at most 2 arms and 1 head.
Any arm, leg and head belongs to at most 1 human body.
Male_body and female_body are exclusive subtypes of human_body
and so are juvenile_body and adult_body.
FE: Any human_body is a body and has for part AND{at most 2 arms, 1 head}.
Any OR{arm, head} is part of at most 1 human body.
Human_body has for subtype AND{male_body, female_body, juvenile_body, adult_body}.
Male_body has for exclusion female_body. Juvenile_body has for exclusion adult_body.
FCG: [any human_body, type: body, part: AND{at most 2 arms, 1 head}]
[any OR{arm, head}, part of: at most 1 human body]
[human_body, subtype: AND{male_body, female_body, juvenile_body, adult_body}]
[male_body, exclusion: female_body] [juvenile_body, exclusion: adult_body]
FL: human_body supertype: body,
part: arm [0..1,0..2] head [1,1],
subtype: {male_body female_body} {juvenile_body adult_body};
Readable, Concise, Expressive and Normalising Notations (Con't)
The full translation in KIF of the 3 lines in FL:
(forall ((?b human_body)) (body ?b))
(forall ((?b human_body)) (atMostN 2 '?a arm (part ?b '?a)))
(forall ((?a arm)) (atMostN 1 '?b human_body (part '?b ?a)))
(forall ((?b human_body)) (atMostN 2 '?a leg (part ?b '?a)))
(forall ((?a head)) (atMostN 1 '?b human_body (part '?b ?a)))
(forall ((?b male_body)) (and (human_body) (not (female_body ?b))))
(forall ((?b female_body)) (and (human_body) (not (male_body ?b))))
(forall ((?b male_body)) (and (human_body) (not (female_body ?b))))
(forall ((?b juvenile_body)) (and (human_body) (not (adult_body ?b))))
(forall ((?b adult_body)) (and (human_body) (not (juvenile_body ?b))))
(defrelation atMostN (?num ?var ?type ?predicate) :=
(exists ((?s set)(?n)) (and (size ?s ?n) (=< ?n ?num)
(truth ^(forall (,?var) (=> (member ,?var ,?s)
(and (,?type ,?var) ,?predicate)))))))
Readable, Concise, Expressive and Normalising Notations (Con't)
Full translation in RDF+OWL of the 3 lines in FL:
Readable, Concise, Expressive and Normalising Notations (Con't)
With information on creators:
En: According to Joe (who has for user id "joe"), a body (as understood in
WordNet 1.7) may have for part (as defined by "pm") a leg (as understood
by "fg") and exactly 1 head (as understood by "oc").
FE: `A wn#body has for pm#part at least 1 fg#leg and for pm#part 1 oc#head'(joe).
FL: wn#body pm#part: fg#leg (joe) oc#head [1](joe);
FCG: [wn#body, pm#part: at least 1 fg#leg, pm#part: 1 oc#head](joe);
KIF: (believer '(forall ((?b wn#body)) (atLeastN 1 '?l fg#leg (pm#part '?b ?l))) joe)
(believer '(forall ((?b wn#body)) (exists1 '?h oc#head (pm#part '?b ?h))) joe)
Readable, Concise, Expressive and Normalising Notations (Con't)
FL can also be used for structured discussions.
"XML is useless for knowledge representation, exchange or storage"
argument: ("using XML tools for KBSs is a useless additional task"
argument: "KBSs do not use XML internally" (pm,
objection: "XML can be used for knowledge exchange or storage" (joe,
objection: "it is as easy to use other formats for
knowledge exchange or storage" (pm),
objection: "a KBS (also) has to use other formats for
knowledge exchange or storage" (pm)))
)(pm);
"XML can be used for knowledge exchange or storage"
argument: - "an XML notation permits classic XML tools (parsers, XSLT, ...) to
be re-used" (pm)
- "classic XML tools are usable even if a graph-based model is used" (pm),
argument of: ("a KRL should (also) have an XML notation",
specialization: "the Semantic Web KRL should have an XML notation" (pm),
specialization of: "a KRL (Knowledge Representation Language)
can have an XML notation" (pm),
)(pm);
Valuating Contributions and Contributors
For each statement and user of a repository, it is possible to come up with a value for
its/his/her "usefulness" (a value representing its interest, popularity, originality, etc.) based on
- the existence (or not) of arguments/objections/corrections for each statement,
- who authored which statements and argued for/against which statements, and
- who voted on which statements and how.
This value can be used for highlighting or filtering out some statements,
and for valuating research outputs more accurately than by counting the number of publications.
Such a measure should often be user-defined; the article for a base/default algorithm.
Advantages:
- enhancing Information Retrieval and the evaluation of researchers, teachers and students
- removing the reliance on committees or other users to judge what is of interest or not
- encouraging authors to be precise and original
- training and evaluating critical thinking.
Ontologies
The default ontology proposed by WebKB-2 (which any user of WebKB-2 can extend
and that is known as the M.S.O. by the
IEEE SUO) is a
transformation of WordNet 1.7 into a
genuine lexical ontology and an integration of
integration of various
top-level ontologies, e.g. from
Sowa,
Dolce, the
SUMO, the
Lifecycle Integration Schema, the
Natural Semantic Metalanguage,
OWL,
DAML+OIL,
KIF and the
Dublin Core.
Representation of 3 courses
(Multimedia,
Systems Analysis & Design,
Workflow Management)
and beginning of the representation of
Knowledge Management Resources (data structures, processes, techniques, tools, ...),
first focusing on
CG-related resources
(e.g., classification of 7 CG tools according to 160 features).
Conclusion
Minimal requirements elements for efficient knowledge sharing and retrieval:
- readable, concise, expressive and normalising notations
- large multi-source ontology, edition protocols, knowledge/creator valuation
- various mechanisms for querying/comparing knowledge and generating querying/entering forms
Not sufficient but one complement to other works in knowledge sharing and retrieval,
learning constructivist approaches, learning objects, learning grids and semantic grids.
Researchers, teachers and students are ideal users for this precision-oriented approach.
Annex 1: Querying
Category querying: WebKB permits to find categories (types or instances) according to their names, creators, relations connected to them, and permits to display all the objects (categories and statements) directly or indirectly connected to them on a single screen. Most other tools impose much more browsing to access information and hence make it difficult to retrieve and compare information in any realistic amount of knowledge.
Category comparison: WebKB permits to find which relations exist between two given categories (this feature is sometimes useful but not very common).
Statement querying:
FCG (instead of FL) can be used to express and retrieve statements that are more complex
than relations between categories. Various search operators are provided: "spec", "gen",
"?" (a combination of "spec" and "gen"), etc.
? [a person, agent of: a sell]
[Ned, agent of: (a sell, object: a car)](pm, 21/2/2001);
[3 cars, object of: (2 sells, agent: Ned, time:21/1/2001)](pm,12/7/2005);
[John, believer of: not [Ned, agent of: a sell]](jj,3/12/2004);
Annex 2: Comparing statements in a scalable way
compare pm#WebKB-2 km#Ontolingua on
(support of: a is#IR_task, output_language: a km#KR_notation,
part: a is#user_interface), maxdepth 5
WebKB-2 Ontolingua
support of:
is#IR_task + +
is#lexical_search + +
is#regular_expression_based_search + .
km#knowledge_retrieval_task + .
km#generalization_structural_retrieval + .
...
output_language:
km#KR_notation + +
(expressivity: km#FOL) + +
km#FCG + .
km#KIF . +
km#XML-based notation + .
km#RDF + -
...
{kind=link}