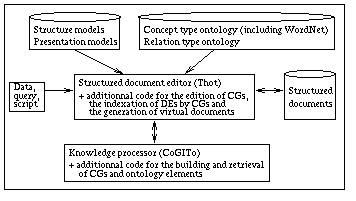
Fig. 1. The CGKAT architecture
Philippe
MARTIN
University of Adelaide -
Computer Sciences department, Australia
e-mail: pm .@. phmartin dot info
This work was completed at the INRIA
(ACACIA Project),
France
In Knowledge Acquisition (KA), the knowledge engineer must model and represent expertise into a knowledge base (KB). To do so s/he often searches for information in documents (e.g. interview retranscriptions and technical reports) and structures these documents in order to ease search and modelling. S/he also has to do searches on the knowledge representations to compare, organize and validate them.
In Information Retrieval (IR), the indexation of (parts of) documents by direct hypertext links, keywords or SGML-like tags do not allow the IR system to adequately answer queries expressed at different levels of generality or generate an organised view of the document contents. To allow this, an adequate knowledge representation (KR) language must be used. The more detailed the indexation is, the more precise the answers of the IR system will be. Like KA, precision-oriented IR implies the construction of an organised KB from documents and searches in documents via searches in this KB. It is also eased by a KA/IR system exploiting the structure of documents (i.e. the fact that the document elements are typed and may be linked by composition links or hypertext links, and that various presentation models may be associated and applied to them).
CGKAT [2,3,4] helps KA and IR in two ways.
CGKAT has a client/server architecture and also includes the above cited libraries.
The server is made up of the CG workbench CoGITo plus an additional functional interface to allow a) building and retrieval of CGs via Thot menus or textual commands callable inside Thot documents or from an Unix shell or script, and b) browsing ontologies (e.g. WordNet) and modifications on the user ontologies.
The client is the structured document editor Thot plus additional code to allow a) CGs to be edited, handled and stored inside structured documents using the Thot interface, b) the indexation of DEs by CGs, and c) the generation of virtual documents. When a Thot document including CGs is opened, CGKAT also automatically creates them in the base of CoGITo, and removes them when the document is closed. Thus, Thot documents may be used to load, display, browse, structure, document, edit and store selected parts of the KB (an editing operation on a CG via Thot is allowed only if it is accepted by CoGITo, i.e. if it does not violate conceptual constraints previously defined). Conceptual queries may also be done on these selected parts in order to retrieve some CGs or type definitions, or the DEs they index.
Fig. 1. The CGKAT architecture
CGKAT is a domain-independent KA tool and precision-oriented IR tool. Arbitrary precise representations are enabled by the CG formalism. However, the representations are done manually, therefore their precisions depends only on the users goals. CGKAT has already been used for modelling road accident expertises.
The main limitations of CGKAT for IR, and to a lesser extent for KA, are the facts that: a) it does not help knowledge extraction (DE representation) by natural language processing techniques, b) no index on knowledge representations is exploited for accelerating their retrieval (except via their membership to documents), e.g. the search for the specialisations of a CG is done by projection of this CG on each CG loaded in main memory), and c) it does not allow the retrieval of paths of concepts and relations inside CGs (inside each CG or inside the CGs seen as a global semantic network). For these reasons, CGKAT is mainly interesting from a KA viewpoint.
CGKAT helps KA and IR by combining a CG workbench with a structured document editor, and by providing default general ontologies and functions to search and handle them. Thus, compared to other current KA or IR systems, it provides more ways or more precise ways to represent or index DEs and structure these DEs or the knowledge representations, and more guidance or freedom for representing or structuring information (KA or IR systems generally do not provide a default ontology or provide a non-extensible ontology). Articles related to CGKAT are accessible at http://www.phmartin.info/CGKAT/.
CGKAT could be quickly extended by using extensions of CoGITo (e.g. with rules and CGs index), of Thot (e.g. Alliance for document cooperative edition and Amaya for Web-browsing) and of WordNet (e.g. EuroWordNet and International WordNet).
Many of the CGKAT functionnalities could also be obtained and complemented using other knowledge processors, other structured document editors or browsers and other information management systems (see The WebKB set of tools in these CGTOOLS'97 proceedings for more details on our work in that direction).
1. O. Haemmerlé, CoGITo: une plate-forme de développement de logiciels sur les graphes conceptuels. Ph.D thesis, Montpellier II University, France, Jan. 1995.
2. P. Martin, Using the WordNet Concept Catalog and a Relation Hierarchy for KA, in Proceedings of Peirce'95, Santa Cruz, California, Aug. 18, 1995.
3. P. Martin, and L. Alpay, Conceptual Structures and Structured Documents, in Proceedings of ICCS'96, Sydney, Australia, Aug. 19-22, 1996.
4. P. Martin, Exploitation de graphes conceptuels et de documents structurés et hypertextes pour l'acquisition de connaissances et la recherche d'informations. Ph.D thesis, University of Nice - Sophia Antipolis, France, Oct. 14, 1996.
5. G.A. Miller, WordNet: A Lexical database for English, in Communications of the ACM. Nov. 1995.
6. V. Quint, and I. Vatton, Combining Hypertext and Structured Documents in Grif, in Proceedings of ECHT'92, D. Lucarella, ed., ACM Press, Milan, Dec. 1992.